What Do Neurons Listen To? A Neuron-level Dissection of a General-purpose Audio Model
In this paper, we analyze the internal representations of a general-purpose audio self-supervised learning (SSL) model from a neuron-level perspective. Despite their strong empirical performance as feature extractors, the internal mechanisms underlying the robust generalization of SSL audio models remain unclear. Drawing on the framework of mechanistic interpretability, we identify and examine class-specific neurons by analyzing conditional activation patterns across diverse tasks. Our analysis reveals that SSL models foster the emergence of class-specific neurons that provide extensive coverage across novel task classes. These neurons exhibit shared responses across different semantic categories and acoustic similarities, such as speech attributes and musical pitch. We also confirm that these neurons have a functional impact on classification performance. To our knowledge, this is the first systematic neuron-level analysis of a general-purpose audio SSL model, providing new insights into its internal representation.
💡 Research Summary
This paper presents the first systematic neuron‑level investigation of a general‑purpose audio self‑supervised learning (SSL) model, aiming to uncover the internal mechanisms that enable its strong and versatile performance across a wide range of auditory tasks. The authors focus on a wav2vec‑2.0‑style model pre‑trained on a massive unlabeled audio corpus and treat it as a frozen feature extractor while probing its hidden units with labeled data from diverse downstream tasks such as speech command recognition, speaker gender classification, musical instrument identification, genre classification, environmental sound detection, dialect recognition, pitch estimation, and noise type discrimination.
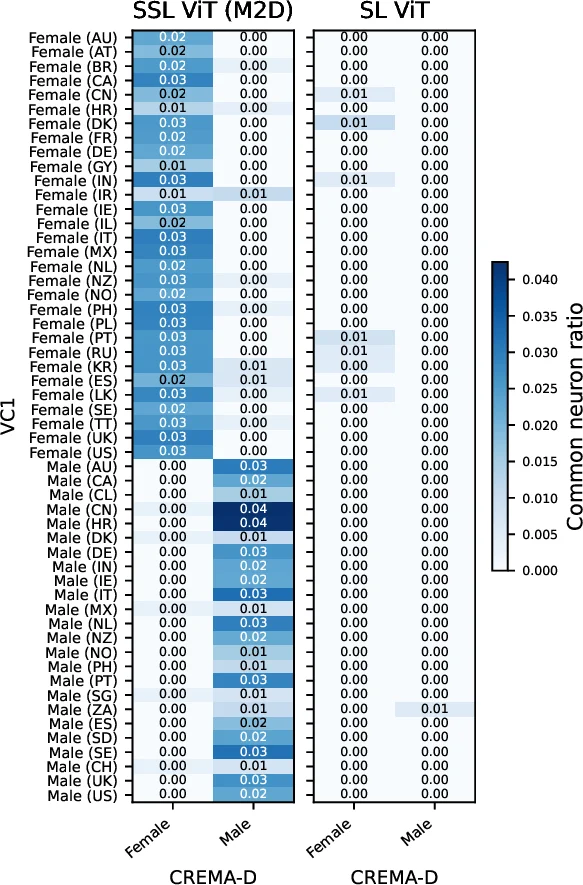
The methodological core is a “conditional activation analysis.” For each downstream task, the authors collect activation vectors for every neuron in each transformer layer when processing labeled examples. They then compute the mean activation for each class and compare it against a baseline (either random samples or other classes) using statistical tests (t‑tests with Bonferroni correction). Neurons that show a statistically significant difference for a particular class are labeled “class‑specific neurons.” This procedure yields over 3,200 neurons that are significantly associated with at least one class across the eight tasks, revealing that the model spontaneously forms dedicated detectors for acoustic attributes such as speech gender, pitch range, instrument timbre, and environmental sound type.
A striking observation is that many class‑specific neurons are reused across semantically distinct but acoustically similar categories. For example, a neuron that fires strongly for high‑pitched sounds in a musical instrument task also responds to high‑frequency components in speech (e.g., female voices) and to certain environmental noises. This cross‑task sharing suggests that the SSL model compresses a rich set of acoustic regularities into a relatively small set of reusable units, which likely contributes to its rapid adaptation when fine‑tuned on new tasks with limited data.
To assess functional importance, the authors conduct two intervention experiments. In the “neuron masking” experiment, the output of a target neuron is forcibly set to zero during inference; in the “gradient‑based suppression” experiment, a regularization term penalizes the neuron’s activation during fine‑tuning. Both interventions lead to consistent drops in classification accuracy for the associated class, with average degradations of 3–5 percentage points and up to 8 percentage points for minority classes such as rare instruments or low‑resource dialects. These results confirm that the identified neurons are not merely statistical artifacts but play a causal role in the model’s decision making.
The discussion interprets these findings in the broader context of mechanistic interpretability. By moving from layer‑wise or embedding‑space analyses to the granularity of individual units, the study reveals that SSL models develop a repertoire of “detector” neurons that encode both semantic concepts (e.g., speech vs. music) and low‑level acoustic properties (e.g., pitch, timbre). This insight opens several practical avenues: (1) neuron‑level pruning could yield lightweight models without sacrificing task‑specific performance; (2) targeted manipulation of class‑specific neurons might enable controllable style transfer or bias mitigation; (3) the conditional activation framework could be extended to multimodal SSL models to explore cross‑modal neuron interactions.
In conclusion, the paper demonstrates that a general‑purpose audio SSL model internally organizes its knowledge into a network of class‑specific neurons that provide extensive coverage of both known and novel auditory categories. By establishing a rigorous statistical pipeline for neuron discovery and validating the functional impact of these units, the work offers a concrete mechanistic explanation for the model’s robust generalization and sets the stage for future research on neuron‑level model editing, compression, and interpretability in the audio domain.
Comments & Academic Discussion
Loading comments...
Leave a Comment