The Information Geometry of Softmax: Probing and Steering
This paper concerns the question of how AI systems encode semantic structure into the geometric structure of their representation spaces. The motivating observation of this paper is that the natural geometry of these representation spaces should reflect the way models use representations to produce behavior. We focus on the important special case of representations that define softmax distributions. In this case, we argue that the natural geometry is information geometry. Our focus is on the role of information geometry on semantic encoding and the linear representation hypothesis. As an illustrative application, we develop “dual steering”, a method for robustly steering representations to exhibit a particular concept using linear probes. We prove that dual steering optimally modifies the target concept while minimizing changes to off-target concepts. Empirically, we find that dual steering enhances the controllability and stability of concept manipulation.
💡 Research Summary
The paper tackles a fundamental question in modern AI: how do neural networks encode semantic structure into the geometry of their internal representation spaces, especially when the final output is a softmax distribution? The authors argue that the natural geometry of such spaces is information geometry, i.e., the Riemannian structure induced by the Fisher information metric on the probability simplex.
First, they formalize the relationship between the pre‑softmax logits z and the resulting probability vector p. By differentiating the softmax function they show that the Jacobian of the mapping z ↦ p is exactly the Fisher information matrix F = diag(p) – p pᵀ. This matrix defines a local inner product ‖Δz‖²_F that is a second‑order approximation of the KL‑divergence between the original and perturbed distributions. Consequently, distances measured in this metric reflect true changes in the model’s probabilistic behavior rather than arbitrary Euclidean shifts.
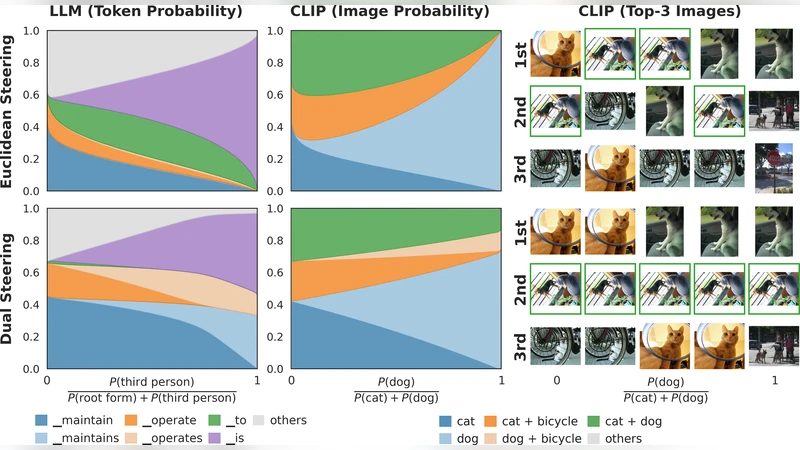
Building on this, the authors revisit the “Linear Representation Hypothesis” (LRH), which posits that semantic concepts are approximately linear subspaces or hyperplanes in the high‑dimensional representation space. In the Fisher‑metric view, a linear probe wᵀz + b is not just a Euclidean hyperplane but the tangent hyperplane to the probability manifold at z. The probe’s weight vector w therefore points in the direction of maximal information change for the targeted concept, while its orthogonal complement corresponds to directions that leave the concept unchanged. This reinterpretation clarifies why naïve Euclidean training of probes can lead to misleading importance scores: the true “semantic direction” must be evaluated under the information‑geometric metric.
The core technical contribution is a method called Dual Steering. Existing approaches to concept manipulation—prompt engineering, activation patching, or single‑probe steering—typically optimize only a single objective (e.g., increase the activation of a target concept). This often unintentionally alters off‑target concepts, leading to semantic drift. Dual Steering formulates a constrained optimization problem that simultaneously enforces a desired increase in a target probe and a desired decrease (or preservation) in one or more off‑target probes, while minimizing the Fisher‑norm of the perturbation. Formally:
\
Comments & Academic Discussion
Loading comments...
Leave a Comment