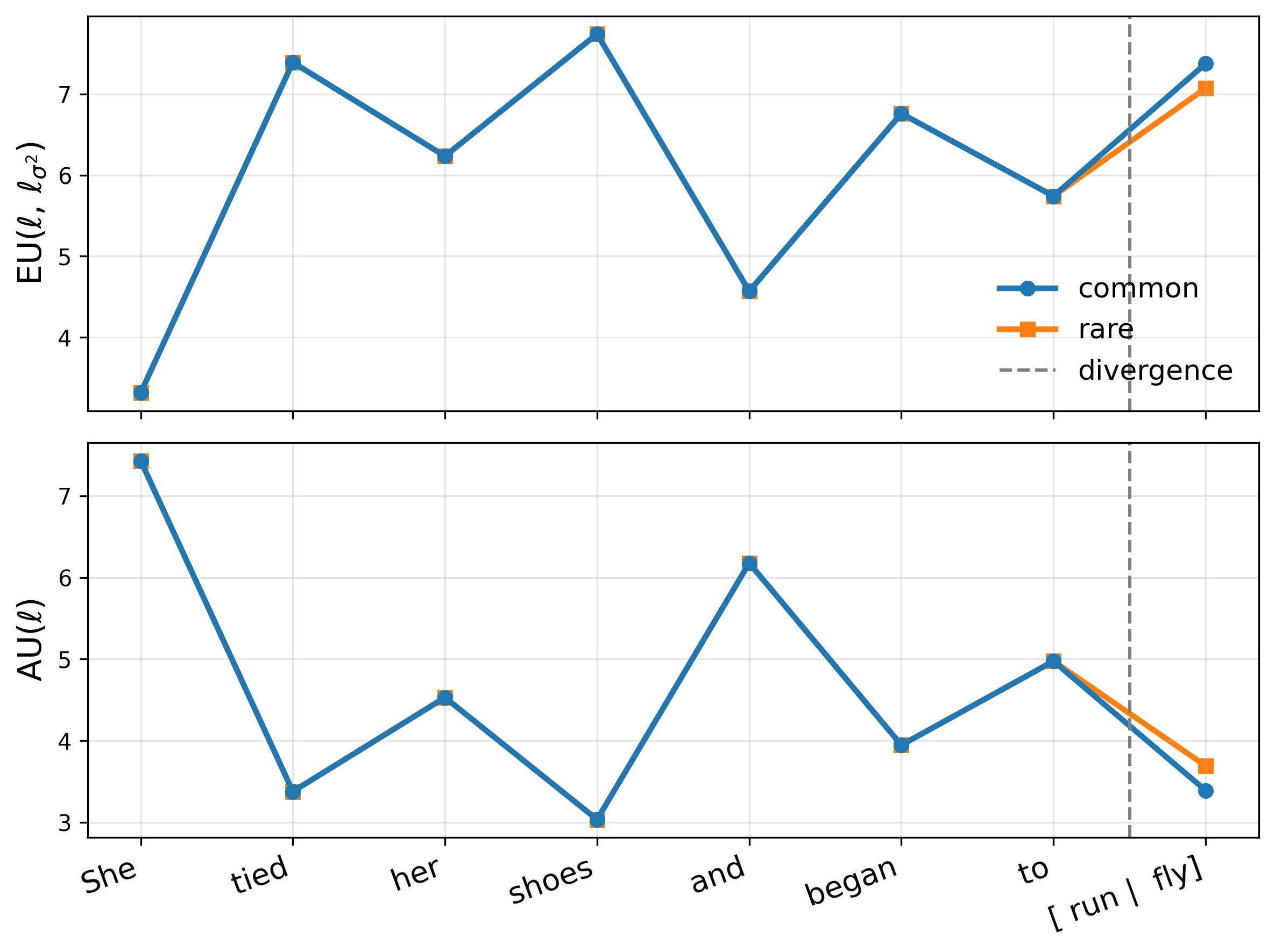
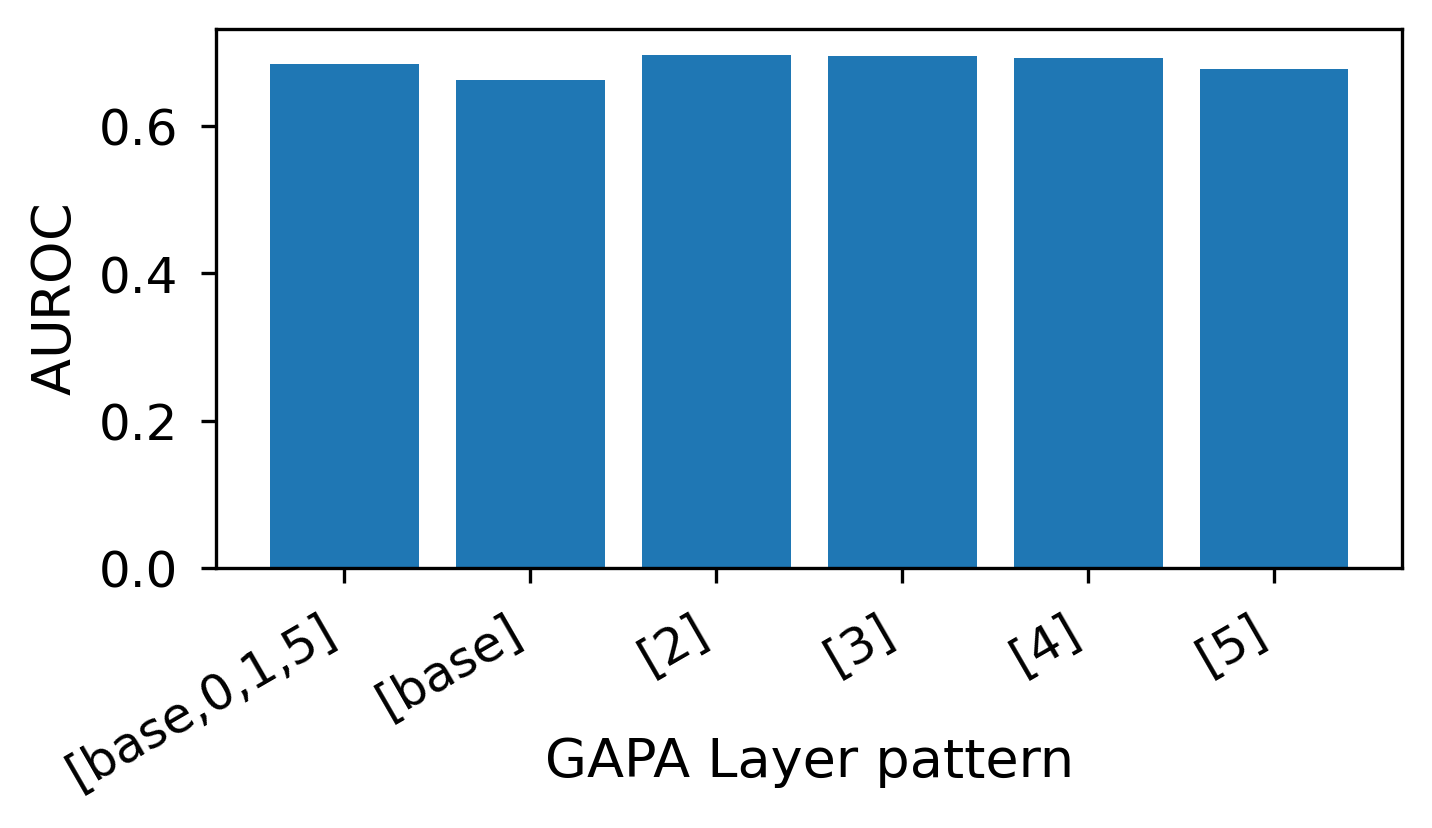
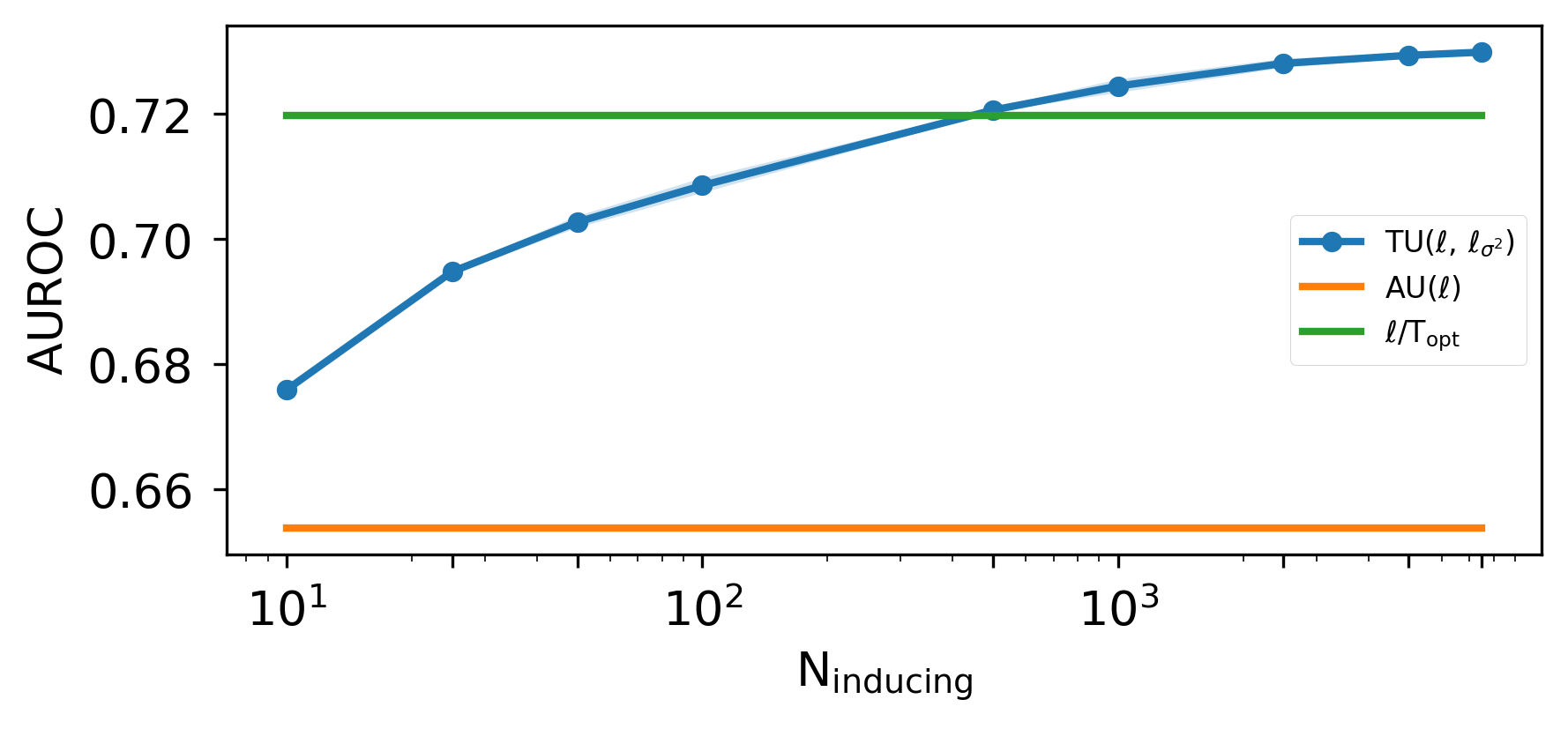
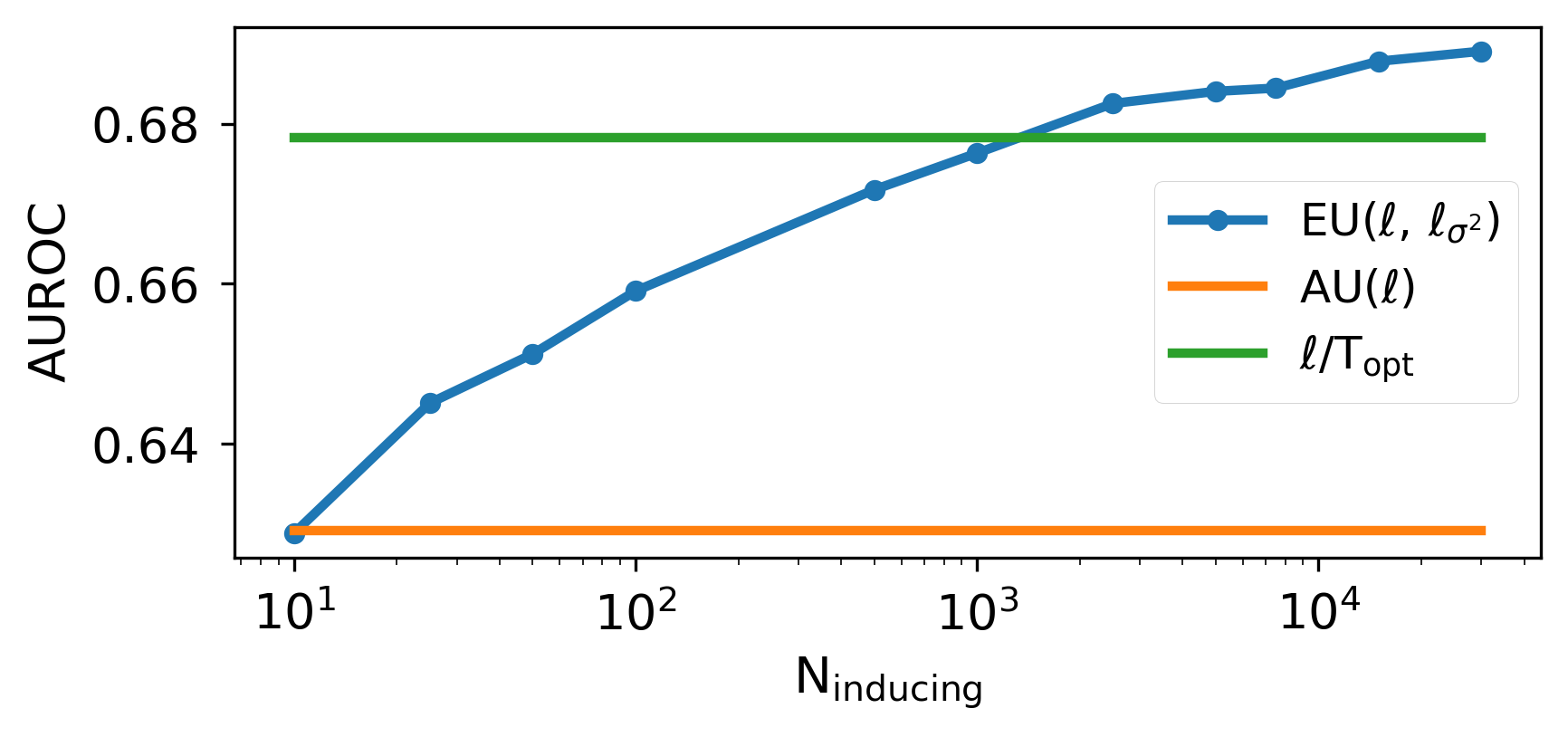
Reliable uncertainty estimates are crucial for deploying pretrained models; yet, many strong methods for quantifying uncertainty require retraining, Monte Carlo sampling, or expensive second-order computations and may alter a frozen backbone's predictions. To address this, we introduce Gaussian Process Activations (GAPA), a post-hoc method that shifts Bayesian modeling from weights to activations. GAPA replaces standard nonlinearities with Gaussian-process activations whose posterior mean exactly matches the original activation, preserving the backbone's point predictions by construction while providing closed-form epistemic variances in activation space. To scale to modern architectures, we use a sparse variational inducing-point approximation over cached training activations, combined with local k-nearest-neighbor subset conditioning, enabling deterministic single-pass uncertainty propagation without sampling, backpropagation, or second-order information. Across regression, classification, image segmentation, and language modeling, GAPA matches or outperforms strong post-hoc baselines in calibration and out-of-distribution detection while remaining efficient at test time.
Deep Dive into Activation-Space Uncertainty Quantification for Pretrained Networks.
Reliable uncertainty estimates are crucial for deploying pretrained models; yet, many strong methods for quantifying uncertainty require retraining, Monte Carlo sampling, or expensive second-order computations and may alter a frozen backbone’s predictions. To address this, we introduce Gaussian Process Activations (GAPA), a post-hoc method that shifts Bayesian modeling from weights to activations. GAPA replaces standard nonlinearities with Gaussian-process activations whose posterior mean exactly matches the original activation, preserving the backbone’s point predictions by construction while providing closed-form epistemic variances in activation space. To scale to modern architectures, we use a sparse variational inducing-point approximation over cached training activations, combined with local k-nearest-neighbor subset conditioning, enabling deterministic single-pass uncertainty propagation without sampling, backpropagation, or second-order information. Across regression, classific
Reliable uncertainty quantification (UQ) is crucial in risksensitive deployments, yet many effective research methods remain impractical in modern settings (Abdar et al., 2021). Weight-space Bayesian approaches (e.g., variational BNNs) often require retraining, labeled data or multi-sample evaluation, ensembles multiply compute, and Laplace-style methods rely on curvature estimates that scale poorly as models and output spaces grow (Blundell et al., 2015;MacKay, Proceedings of the 43 rd International Conference on Machine Learning, Seoul, South Korea. PMLR 306, 2026. Copyright 2026 by the author(s). 1992; Bergna et al., 2024;Gal and Ghahramani, 2016;Lakshminarayanan et al., 2017;Ritter et al., 2018;Ortega et al., 2023). The gap is most pronounced for pretrained backbones, where weights are not expected to be modified and test-time budgets favor single-pass inference. In this regime, a practical post-hoc method should be single-pass, prediction-preserving, epistemic, and scalable to foundation models (Table 1).
We address this by shifting uncertainty modeling from weights to activations. We introduce Gaussian Process Activations (GAPA), a drop-in module that replaces deterministic activations with Gaussian-process activations whose posterior mean matches the original nonlinearity, thereby preserving the frozen backbone’s point predictions by construction while producing activation-space epistemic variances (Figure 1). For scalability, GAPA conditions on cached training activations using a sparse approximation (compression + local kNN conditioning), and propagates the resulting uncertainty through the network via deterministic variance-propagation rules, enabling single-pass predictive uncertainty. Our contributions are
At a high level, GAPA augments a frozen neural network with activation-space uncertainty while strictly preserving its original deterministic predictions. Figure 2 provides a structural overview. In the following sections, we formalize our uncertainty perspective (Sec. 2.1), define the GP activation layer (Sec. 2.2), introduce a scalable inference mechanism (Sec. 2.3), and derive rules for single-pass variance propagation through deep architectures (Sec. 2.4).
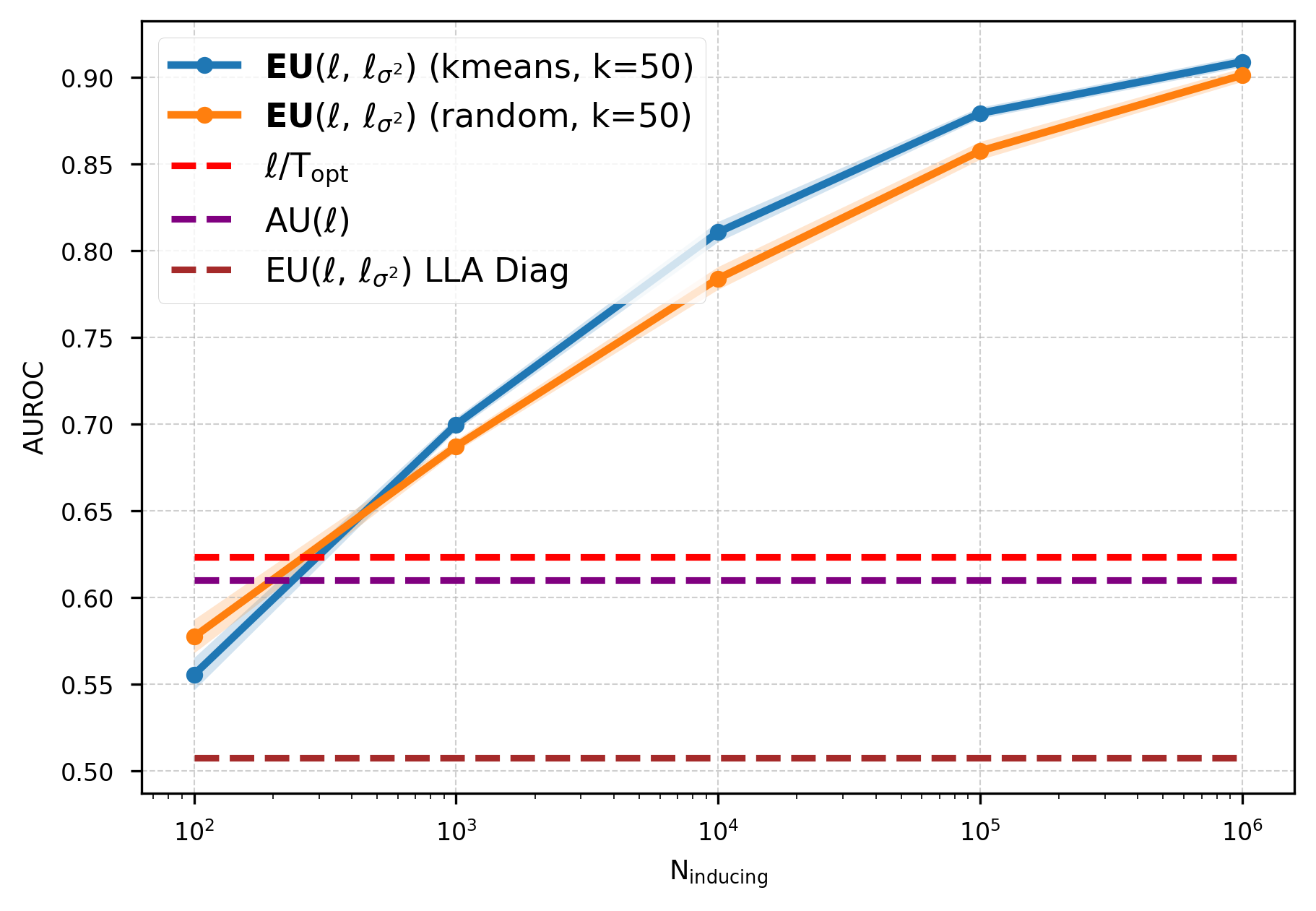
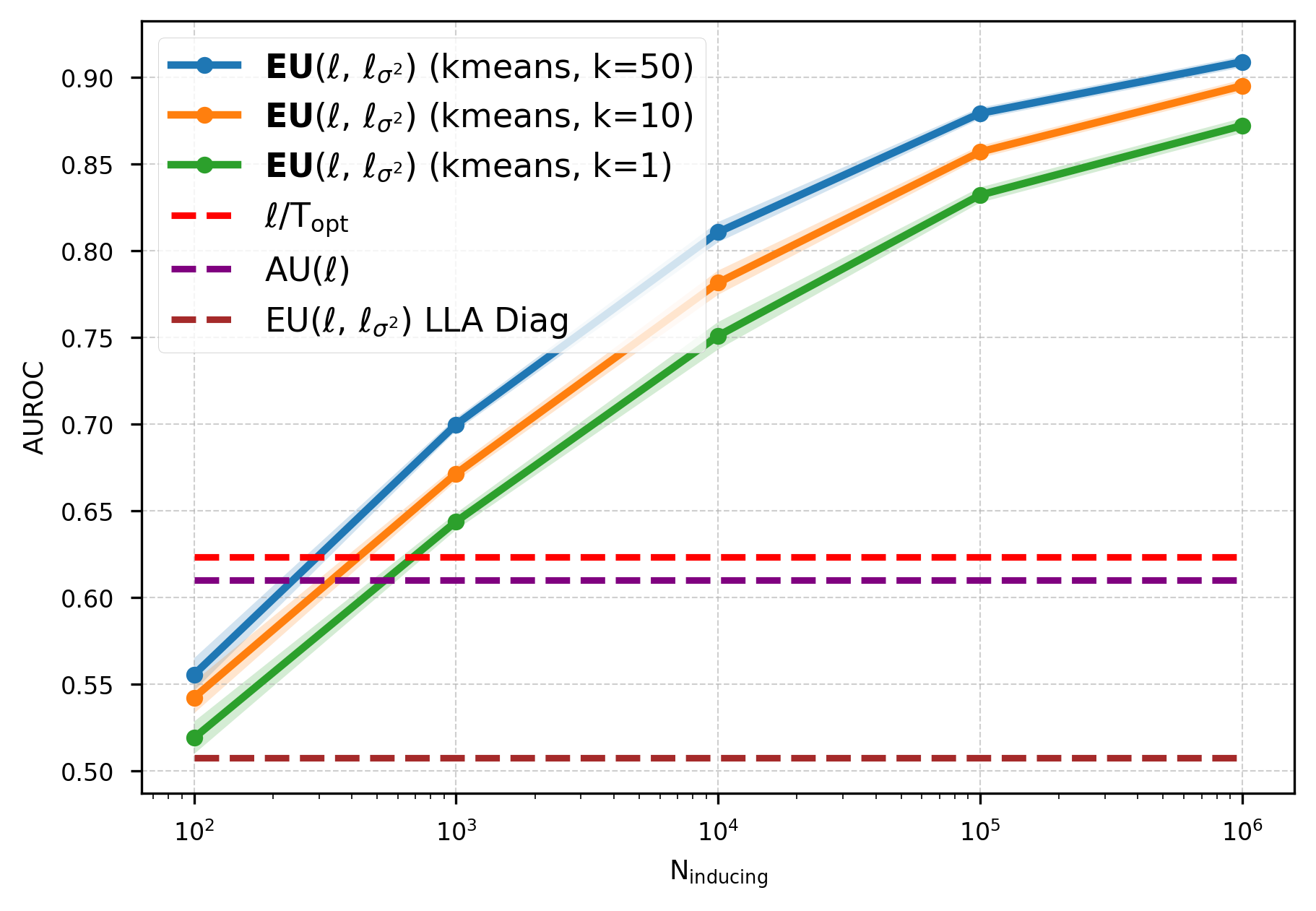
Method pipeline. GAPA operates in two phases. (i) Offline collection: we run a single forward pass of a reference input training set through the pre-trained backbone and cachepre-activations at selected layers. Optionally, we compress the cache into a smaller inducing set via k-means, yielding inducing inputs that admit a variational inducingpoint interpretation in the sense of Titsias (2009). (ii) Testtime inference: we replace deterministic activations with Gaussian-process (GP) activations that return activationspace epistemic variances. These variances are then propagated forward through the remaining frozen network using closed-form variance propagation rules, enabling deterministic single-pass predictive uncertainty without sampling, backpropagation, or retraining, while preserving the backbone’s point predictions.
We position GAPA by stating what is random in the predictive distribution. Let D = {(x n , y n )} N n=1 denote the training data, and let x be a test input with corresponding output y. We denote by f (x) the latent predictor (e.g., a neural network or GP) evaluated at x. Predictive uncertainty is obtained by marginalizing the latent predictor:
Weight-space uncertainty. Weight-space methods (BNNs, Laplace) parameterize f (x) = f (x; w) and infer a posterior w ∼ p(w | D), inducing epistemic uncertainty via variability across plausible weights.
Activation-space uncertainty (GAPA). GAPA keeps the frozen weights deterministic and instead places epistemic uncertainty on the hidden-layer activation (e.g., ReLU outputs). For a chosen layer ℓ, write
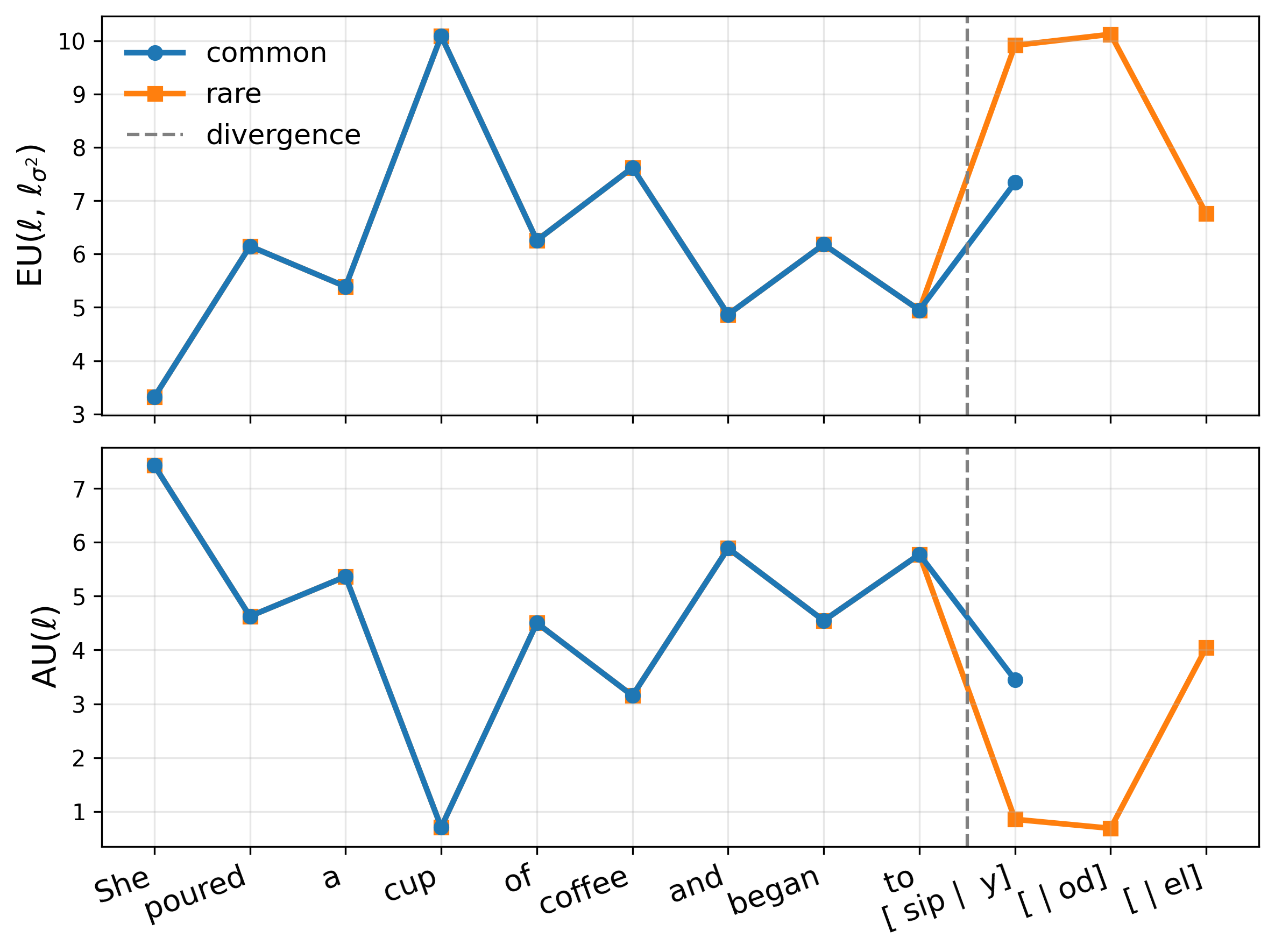
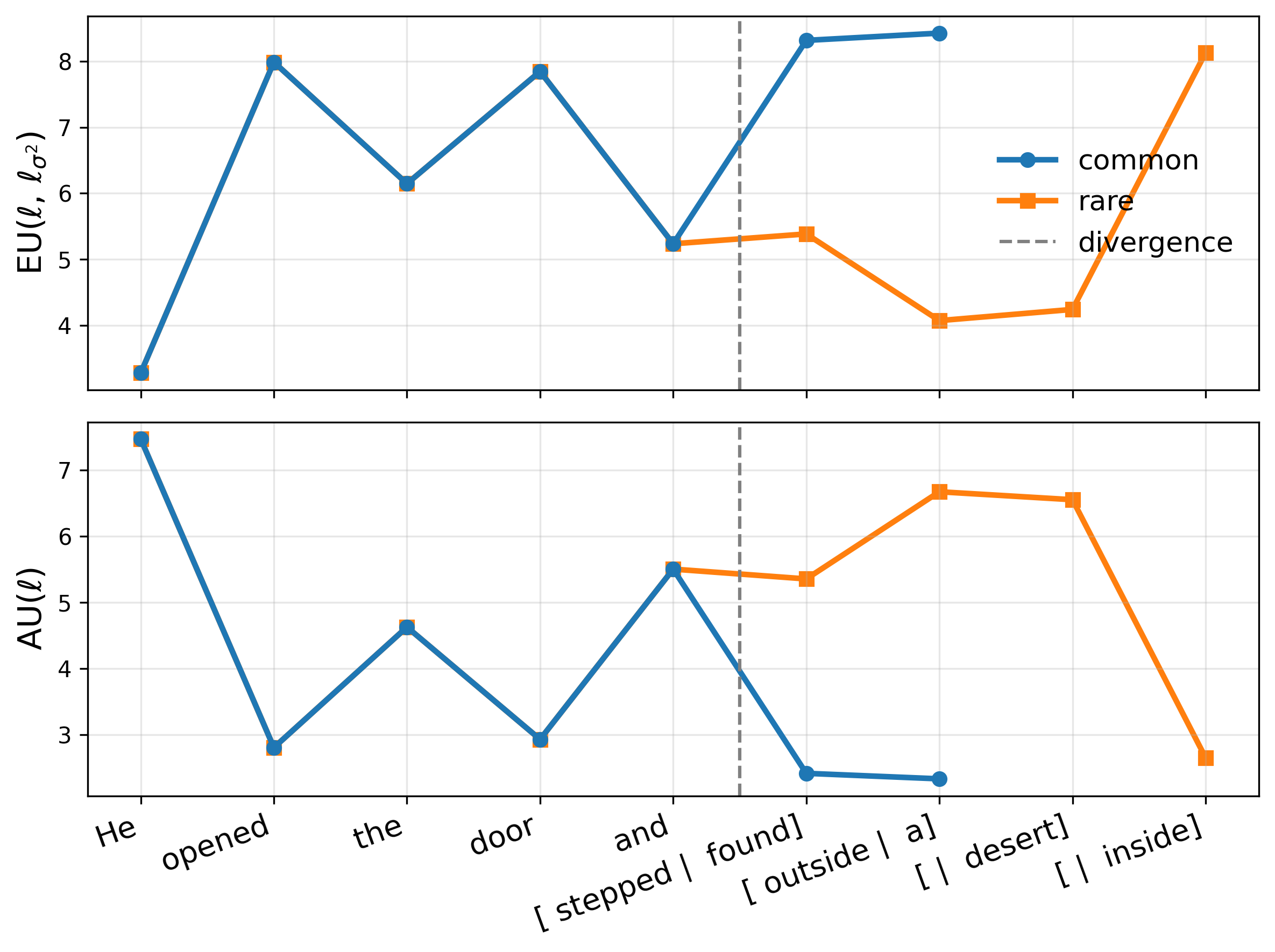
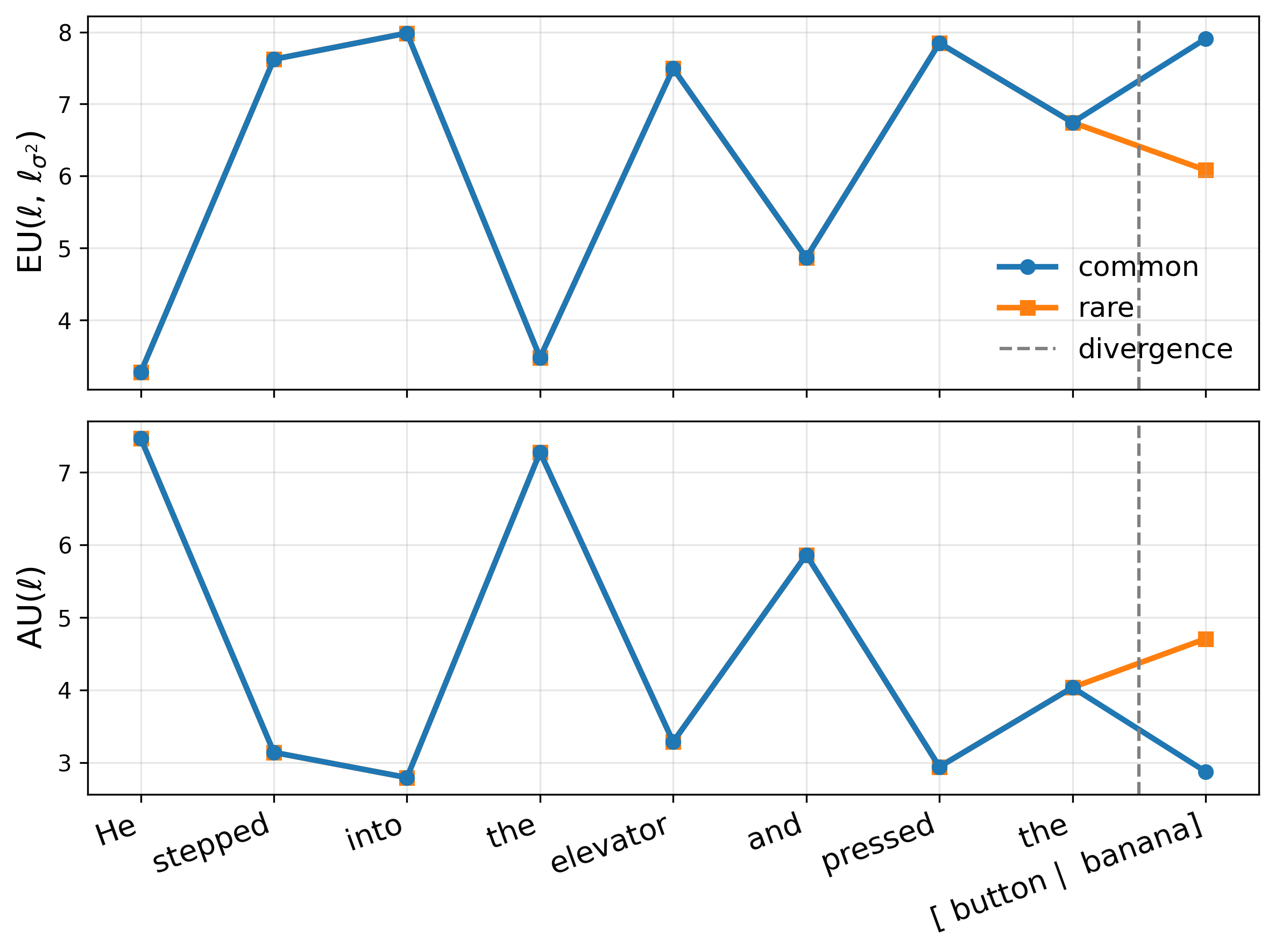
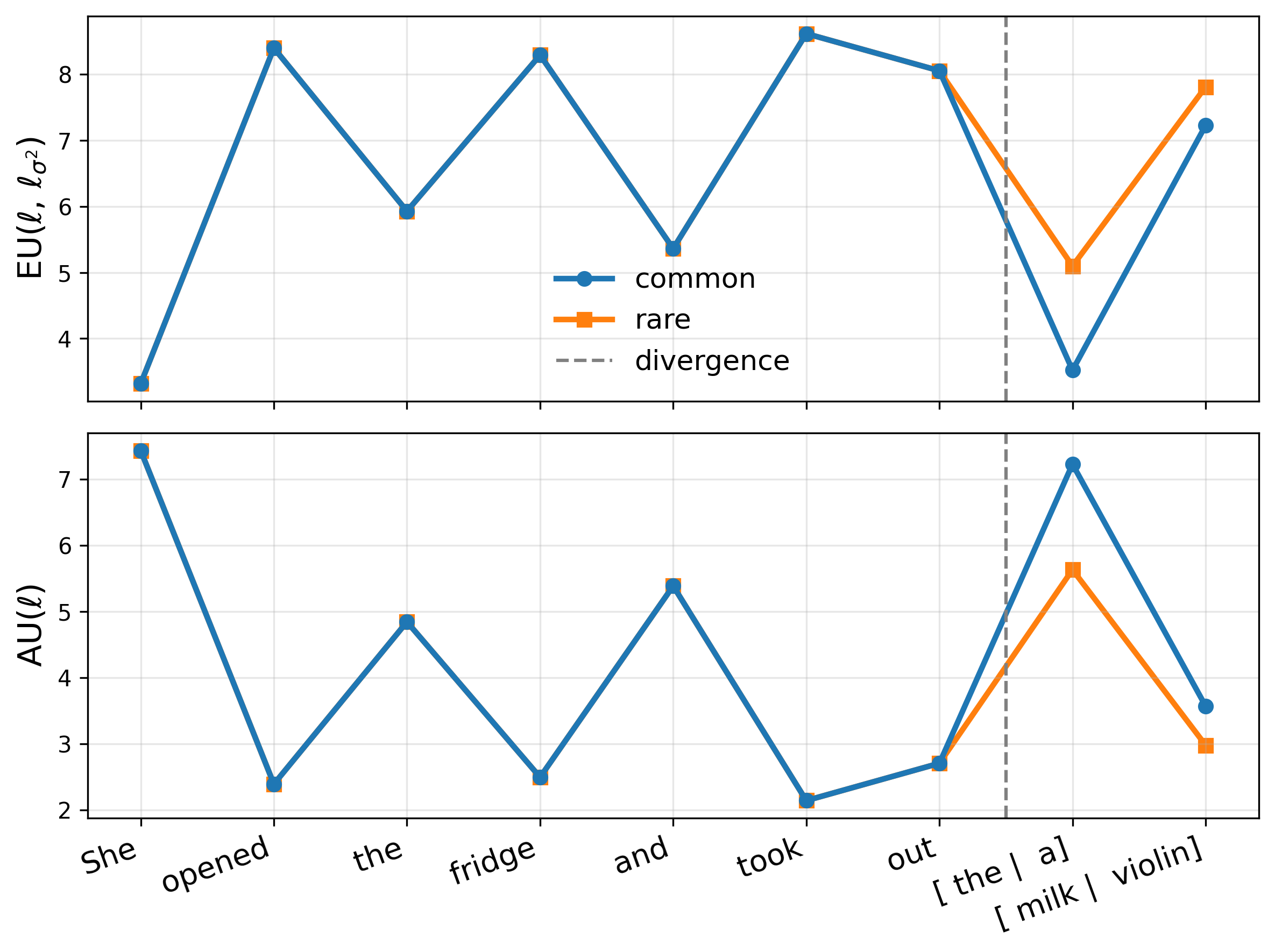
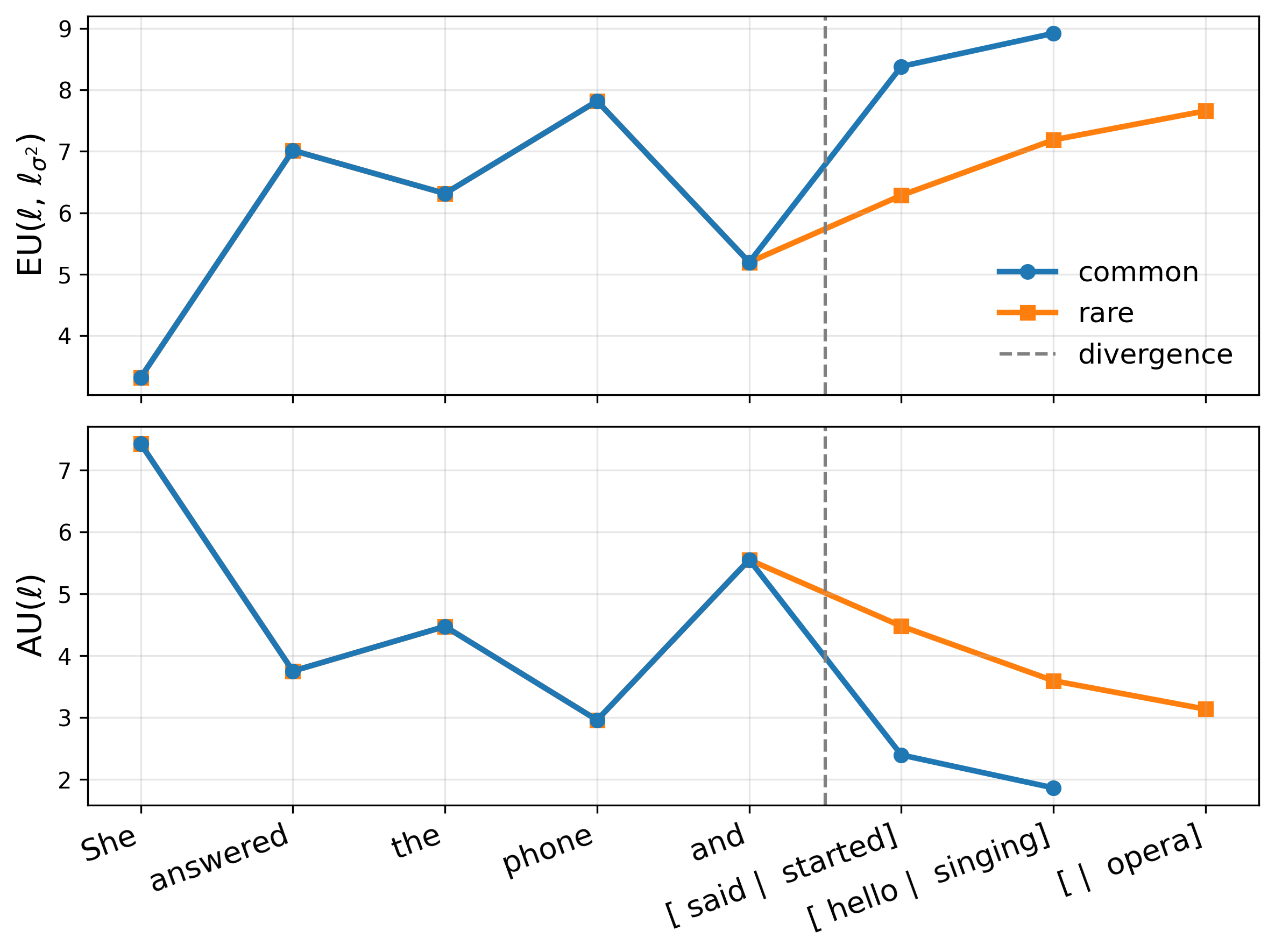
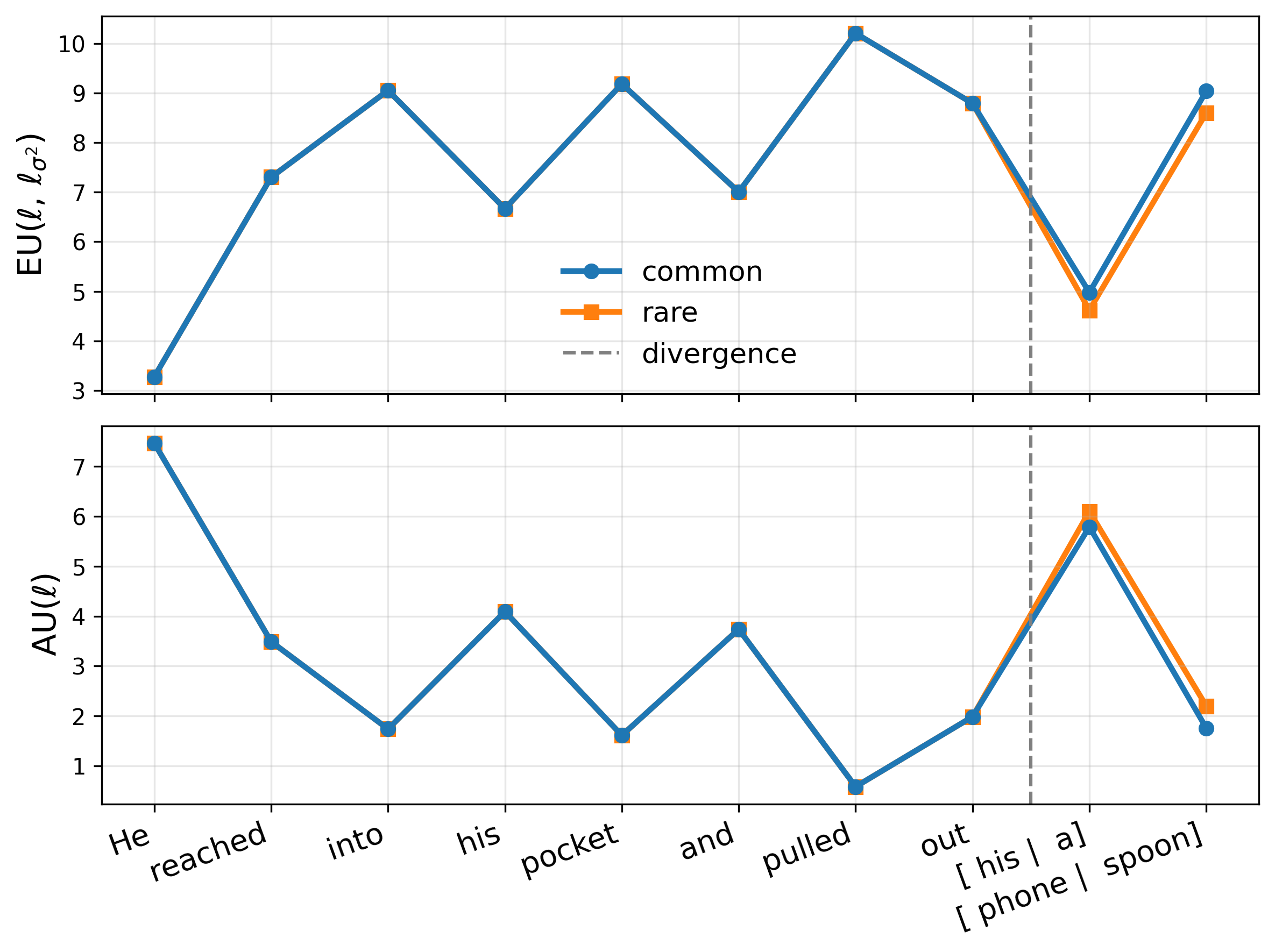
where z ℓ (x) are layer-ℓ pre-activations, ϕ is an elementwise nonlinearity, and h ℓ (•) denotes the remaining frozen network. We replace ϕ with a GP activation g ℓ such that its posterior mean matches the original activation, µ ℓ (z) = ϕ(z) (Sec. 2.2), thereby preserving the backbone point prediction exactly. Let a ℓ := g ℓ (z ℓ (x)) be the resulting random activation. Then p(y | x, D) = p y | h ℓ (a ℓ ) p(a ℓ | z ℓ (x), D) da ℓ . (2) Uncertainty grows as test-time pre-activations move away from regions supported by the training data.
We define the core GAPA module: a drop-in replacement for a deterministic activation that (i) preserves the frozen backbone’s point predictions exactly and (ii) returns a distance-aware epistemic variance in activation space.
Setup. Consider a frozen network and layer ℓ of width d ℓ . Let
where ϕ(z) = (ϕ(z 1 ), . . . , ϕ(z d ℓ )) ⊤ is an element-wise nonlinearity (e.g. ReLU).
GP activation. GAPA replaces the deterministic activation ϕ(•) with a vector-valued Gaussian process (GP)
For any input z, this GP induces a Gaussian marginal distribution over the activation vector
with posterior mean µ ℓ (z) and covariance K ℓ (z, z).
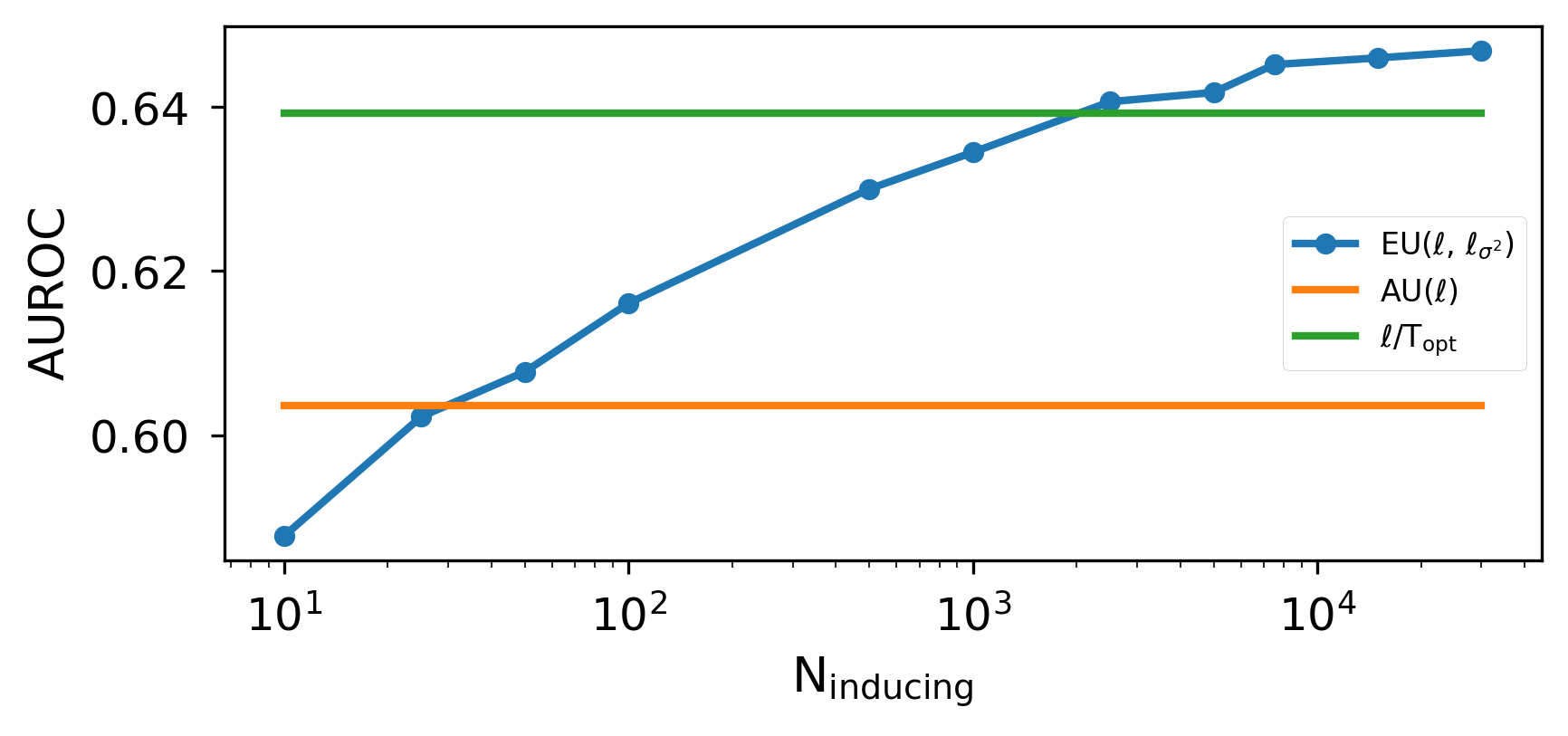
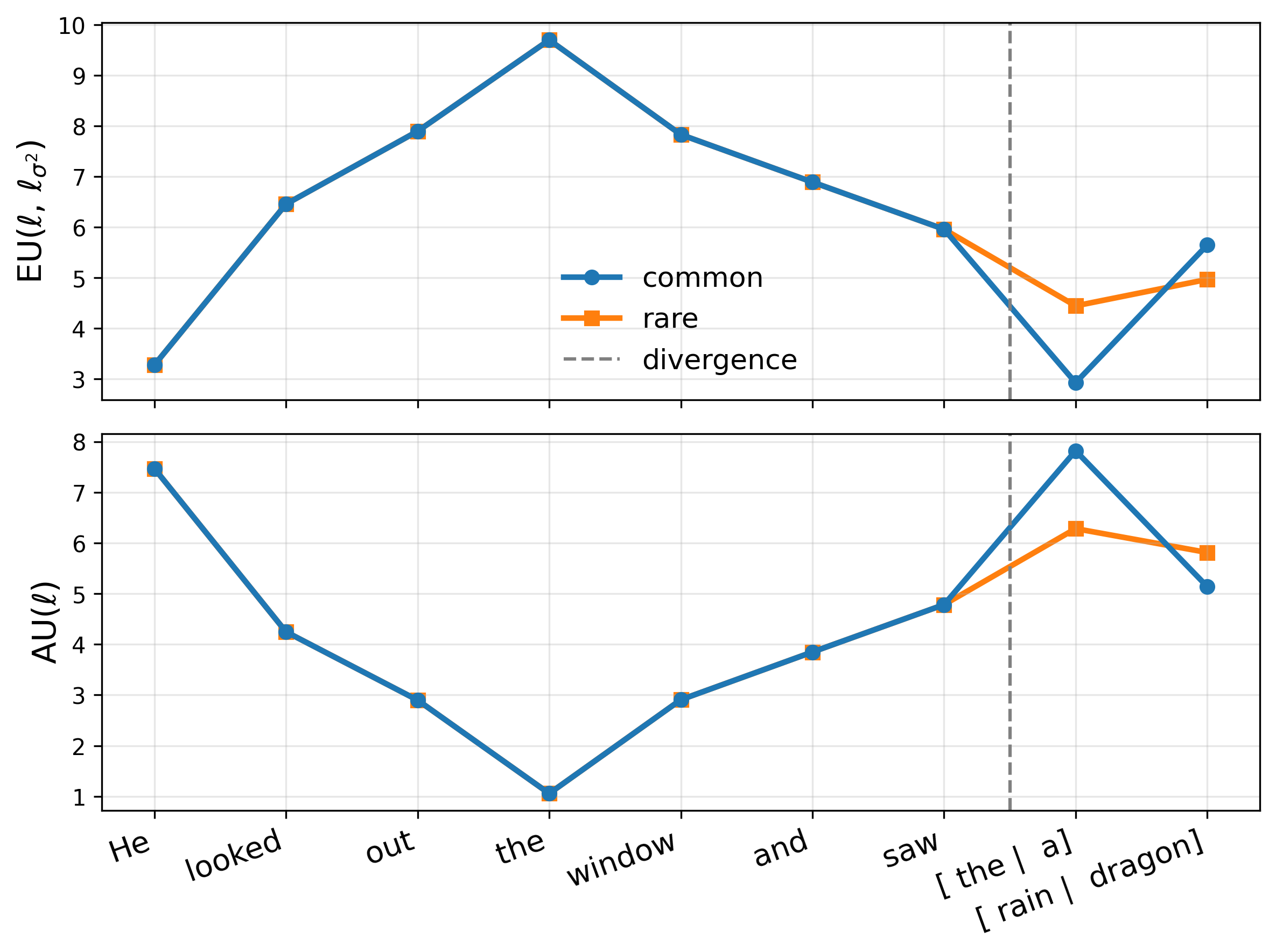
For scalabilit
…(Full text truncated)…
This content is AI-processed based on ArXiv data.