SpreadsheetArena: Decomposing Preference in LLM Generation of Spreadsheet Workbooks
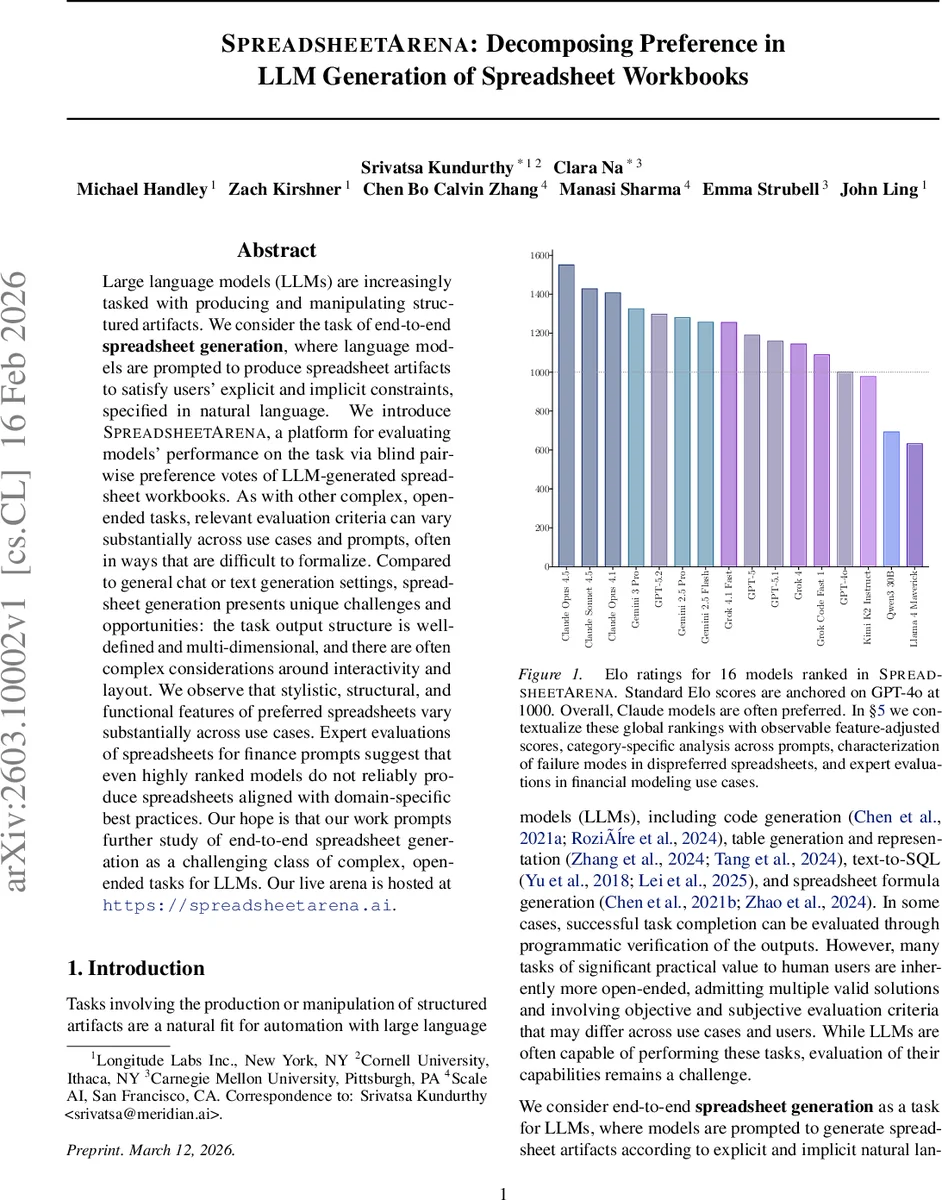
Large language models (LLMs) are increasingly tasked with producing and manipulating structured artifacts. We consider the task of end-to-end spreadsheet generation, where language models are prompted to produce spreadsheet artifacts to satisfy users’ explicit and implicit constraints, specified in natural language. We introduce SpreadsheetArena, a platform for evaluating models’ performance on the task via blind pairwise evaluations of LLM-generated spreadsheet workbooks. As with other complex, open-ended tasks, relevant evaluation criteria can vary substantially across use cases and prompts, often in ways that are difficult to formalize. Compared to general chat or text generation settings, spreadsheet generation presents unique challenges and opportunities: the task output structure is well-defined and multi-dimensional, and there are often complex considerations around interactivity and layout. Among other findings, we observe that stylistic, structural, and functional features of preferred spreadsheets vary substantially across use cases, and expert evaluations of spreadsheets for finance prompts suggests that even highly ranked arena models do not reliably produce spreadsheets aligned with domain-specific best practices. Our hope is that our work prompts further study of end-to-end spreadsheet generation as a challenging and interesting category of complex, open-ended tasks for LLMs. Our live arena is hosted at https://spreadsheetarena.ai.
💡 Research Summary
This paper introduces SpreadsheetArena, a novel evaluation platform for end‑to‑end spreadsheet generation by large language models (LLMs). In this task, a model receives a natural‑language prompt and must output a complete spreadsheet workbook that satisfies both explicit instructions and implicit stylistic conventions. Unlike code or SQL generation, spreadsheets have a multi‑dimensional structure: cells contain values, formulas, and rich formatting (colors, bold, borders), and the overall layout can affect usability. Consequently, evaluating spreadsheet quality requires more than programmatic correctness; it must capture functional accuracy, readability, domain‑specific conventions, and aesthetic preferences.
SpreadsheetArena collects human preference data through blind pairwise battles. For each user‑submitted prompt, four LLMs are selected, and their generated workbooks are presented in four 2‑vs‑2 match‑ups. Voters can mark one workbook as preferred, indicate a tie, or express dissatisfaction with both. Over 4,357 battles were gathered, covering 16 models from several families (Claude, Gemini, Grok, GPT‑4o, etc.).
The raw preference outcomes are modeled with the Bradley‑Terry (BT) framework, yielding latent strength parameters for each model. These parameters are transformed into Elo‑style ratings anchored on GPT‑4o (set to 1000). The baseline Elo ranking shows Claude models generally outperforming others, while Gemini and Grok variants rank lower.
Recognizing that a single latent score cannot explain why users prefer one workbook over another, the authors extend the BT model to incorporate observable spreadsheet features. They extract quantitative attributes from each workbook (number of sheets, filled‑cell ratio, formula count, formatting diversity, color usage, etc.) and include the pairwise differences of these features as covariates in a feature‑augmented BT model. This regression‑style adjustment reveals that the impact of specific features varies dramatically across domains. For finance prompts, adherence to color‑coding standards and the “one row, one formula” rule strongly drive preference, whereas for creative or template‑generation prompts, visual diversity and layout complexity are more influential.
A qualitative failure‑mode analysis shows distinct patterns: some models produce syntactically correct formulas but neglect formatting, resulting in bland or hard‑to‑read sheets; other models generate rich styling but embed incorrect or circular formulas, causing execution failures. Expert evaluation of finance‑focused workbooks confirms that even top‑ranked models frequently violate industry best practices (e.g., hard‑coded constants, inconsistent color palettes).
The study’s key insights are: (1) spreadsheet generation is a high‑dimensional, open‑ended task where functional, structural, and stylistic criteria intertwine; (2) human preference data, when decomposed by observable features, can uncover systematic biases and domain‑specific quality signals; (3) current RLHF or DPO pipelines, which typically optimize for generic correctness, may not capture the nuanced preferences required for professional spreadsheet use.
The authors will release the full dataset—including prompts, generated workbooks, and preference votes—to facilitate further research. They envision future work on preference‑guided fine‑tuning that jointly optimizes formula correctness, layout readability, and domain‑specific conventions, thereby advancing LLM capabilities for complex structured‑artifact generation.
Comments & Academic Discussion
Loading comments...
Leave a Comment