Activation-Space Uncertainty Quantification for Pretrained Networks
Reliable uncertainty estimates are crucial for deploying pretrained models; yet, many strong methods for quantifying uncertainty require retraining, Monte Carlo sampling, or expensive second-order computations and may alter a frozen backbone’s predictions. To address this, we introduce Gaussian Process Activations (GAPA), a post-hoc method that shifts Bayesian modeling from weights to activations. GAPA replaces standard nonlinearities with Gaussian-process activations whose posterior mean exactly matches the original activation, preserving the backbone’s point predictions by construction while providing closed-form epistemic variances in activation space. To scale to modern architectures, we use a sparse variational inducing-point approximation over cached training activations, combined with local k-nearest-neighbor subset conditioning, enabling deterministic single-pass uncertainty propagation without sampling, backpropagation, or second-order information. Across regression, classification, image segmentation, and language modeling, GAPA matches or outperforms strong post-hoc baselines in calibration and out-of-distribution detection while remaining efficient at test time.
💡 Research Summary
The paper tackles a practical problem that has become increasingly important as large pretrained neural networks are deployed in safety‑critical applications: how to obtain reliable uncertainty estimates without retraining the model, performing costly Monte‑Carlo sampling, or computing second‑order information. The authors propose a post‑hoc method called Gaussian Process Activations (GAPA) that shifts Bayesian modeling from the weight space to the activation space. In GAPA each deterministic non‑linearity (e.g., ReLU, GELU) is replaced by a Gaussian‑process‑based activation function. Crucially, the posterior mean of the GP is constrained to equal the original activation, guaranteeing that the point predictions of the frozen backbone remain unchanged. At the same time, the GP provides a closed‑form posterior covariance that quantifies epistemic uncertainty for every activation.
To make the approach scalable to modern deep architectures, the authors adopt a sparse variational inducing‑point approximation. Training data are first passed through the frozen network and the resulting activations are cached. A modest set of inducing points is then learned by maximizing the evidence lower bound (ELBO) while keeping the backbone weights fixed. During inference, instead of conditioning on all inducing points (which would be O(M) where M is the number of inducing points), the method selects a local subset of the k nearest inducing points to the test activation. This “k‑nearest‑neighbor subset conditioning” reduces the computational cost to O(k) and eliminates the need for sampling, back‑propagation, or Hessian‑vector products. The posterior mean and covariance are propagated layer‑by‑layer: the mean follows the usual forward pass, while the covariance is transformed by the linear part of each layer and by the GP kernel, accumulating epistemic uncertainty throughout the network.
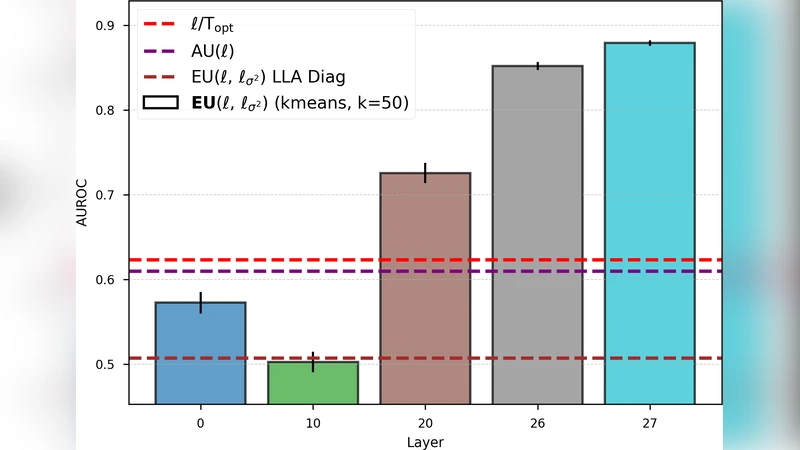
The authors evaluate GAPA on a wide range of tasks: regression (UCI benchmarks, UTKFace age estimation), image classification (CIFAR‑10/100, ImageNet‑30), semantic segmentation (PASCAL VOC), and language modeling (Wikitext‑103 with a Transformer‑XL backbone). Across these domains, GAPA matches or exceeds strong post‑hoc baselines such as Deep Ensembles, MC‑Dropout, SWAG, and Laplace Approximation in terms of calibration error (ECE), negative log‑likelihood, and out‑of‑distribution (OOD) detection AUROC. Notably, GAPA achieves these results while requiring a single deterministic forward pass at test time, leading to 2–5× lower memory usage and inference latency compared to sampling‑based methods.
Ablation studies explore the impact of the number of inducing points, the size of the k‑NN subset, and the choice of kernel (RBF vs. Matern). The results show that a moderate number of inducing points (≈200–500) and a k of 50–100 strike a good balance between performance and efficiency. The method is robust to kernel choice, with RBF providing slightly more stable calibration. Limitations are also discussed: for extremely high‑dimensional activations (e.g., the final layer of very large transformers) the selection of inducing points can still be memory‑intensive, and the current approach relies on manual tuning of kernel hyper‑parameters. Moreover, GAPA captures only epistemic uncertainty; separating it cleanly from aleatoric noise would require additional modeling.
In summary, GAPA introduces a novel paradigm for uncertainty quantification that preserves the exact predictions of a frozen pretrained model while furnishing analytically tractable epistemic variances. By leveraging sparse variational inference and local k‑NN conditioning, it delivers a practical, sampling‑free solution that scales to state‑of‑the‑art architectures. The work opens avenues for further research on automated inducing‑point selection, joint modeling of aleatoric and epistemic uncertainty, and integration with downstream decision‑making pipelines that demand trustworthy AI.
Comments & Academic Discussion
Loading comments...
Leave a Comment