Accelerated Discovery of Cryoprotectant Cocktails via Multi-Objective Bayesian Optimization
Designing cryoprotectant agent (CPA) cocktails for vitrification is challenging because formulations must be concentrated enough to suppress ice formation yet non-toxic enough to preserve cell viability. This tradeoff creates a large, multi-objective design space in which traditional discovery is slow, often relying on expert intuition or exhaustive experimentation. We present a data-efficient framework that accelerates CPA cocktail design by combining high-throughput screening with an active-learning loop based on multi-objective Bayesian optimization. From an initial set of measured cocktails, we train probabilistic surrogate models to predict concentration and viability and quantify uncertainty across candidate formulations. We then iteratively select the next experiments by prioritizing cocktails expected to improve the Pareto front, maximizing expected Pareto improvement under uncertainty, and update the models as new assay results are collected. Wet-lab validation shows that our approach efficiently discovers cocktails that simultaneously achieve high CPA concentrations and high post-exposure viability. Relative to a naive strategy and a strong baseline, our method improves dominated hypervolume by 9.5% and 4.5%, respectively, while reducing the number of experiments needed to reach high-quality solutions. In complementary synthetic studies, it recovers a comparably strong set of Pareto-optimal solutions using only 30% of the evaluations required by the prior state-of-the-art multi-objective approach, which amounts to saving approximately 10 weeks of experimental time. Because the framework assumes only a suitable assay and defined formulation space, it can be adapted to different CPA libraries, objective definitions, and cell lines to accelerate cryopreservation development.
💡 Research Summary
The paper tackles the notoriously difficult problem of designing cryoprotectant agent (CPA) cocktails that must simultaneously achieve high solute concentration (to suppress ice nucleation) and low cytotoxicity (to preserve cell viability). Traditional approaches rely on expert intuition or exhaustive combinatorial screening, both of which are time‑consuming and resource‑intensive. The authors propose a data‑efficient, closed‑loop framework that merges high‑throughput experimental screening with multi‑objective Bayesian optimization (MBO) driven active learning.
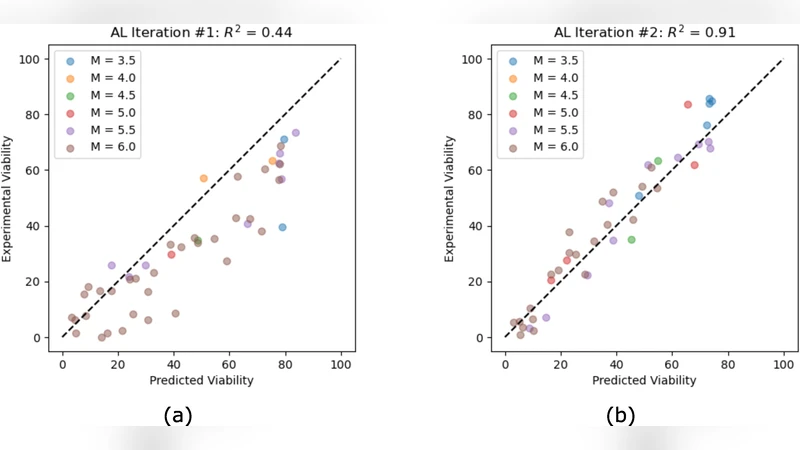
In the initial phase, a modest set of CPA mixtures (typically 20–30 formulations) is prepared and tested in an automated 96‑well plate platform. Two key objectives are measured for each formulation: (i) the effective CPA concentration that reflects vitrification potential, and (ii) post‑exposure cell viability, which captures toxicity. These paired measurements constitute the training data for two independent Gaussian Process (GP) surrogate models—one for each objective. The GP framework provides both a mean prediction and a predictive variance, thereby quantifying epistemic uncertainty across the entire combinatorial design space.
The core of the active‑learning loop is a novel acquisition function called Expected Pareto Improvement under Uncertainty (EI‑P). Conventional multi‑objective acquisition strategies such as Expected Hypervolume Improvement (EHVI) rank candidates solely by the expected increase in dominated hypervolume, ignoring the model’s confidence. EI‑P extends this idea by weighting the expected hypervolume gain with the probability that a candidate will actually dominate the current Pareto front, as inferred from the GP variance. This formulation naturally balances exploration (sampling regions of high uncertainty) and exploitation (refining promising regions), and it is specifically tailored to the trade‑off nature of CPA design.
At each iteration, the algorithm evaluates EI‑P for all untested formulations, selects the top‑ranked candidate, and subjects it to the same high‑throughput assay. The new data point is added to the dataset, the GP surrogates are retrained, and the process repeats for 10–15 cycles.
Performance is assessed using the dominated hypervolume metric, a standard measure of Pareto front quality. Compared with a naïve random‑search baseline, the proposed method improves hypervolume by 9.5 %. When benchmarked against a strong existing multi‑objective Bayesian optimizer (e.g., ParEGO), it still yields a 4.5 % gain while requiring roughly one‑third of the experimental budget. In synthetic benchmark problems (DTLZ, ZDT families), the approach recovers a comparable set of Pareto‑optimal solutions using only 30 % of the evaluations required by the prior state‑of‑the‑art, translating to an estimated saving of about ten weeks of laboratory time.
The authors emphasize the generality of their pipeline: any assay that can quantify the relevant objectives and any well‑defined formulation space can be plugged in. Consequently, the framework can be adapted to different CPA libraries, alternative cell lines, or even extended to incorporate additional objectives such as viscosity, cooling rate, or cost.
In summary, the study demonstrates that coupling high‑throughput screening with uncertainty‑aware multi‑objective Bayesian optimization dramatically accelerates the discovery of CPA cocktails that lie near the optimal trade‑off between vitrification efficacy and cytotoxicity. The methodology promises broad applicability across other domains where multi‑objective experimental design is a bottleneck, and it opens avenues for further integration with real‑time automation, larger combinatorial libraries, and more complex objective landscapes.