Bootstrapping MLLM for Weakly-Supervised Class-Agnostic Object Counting
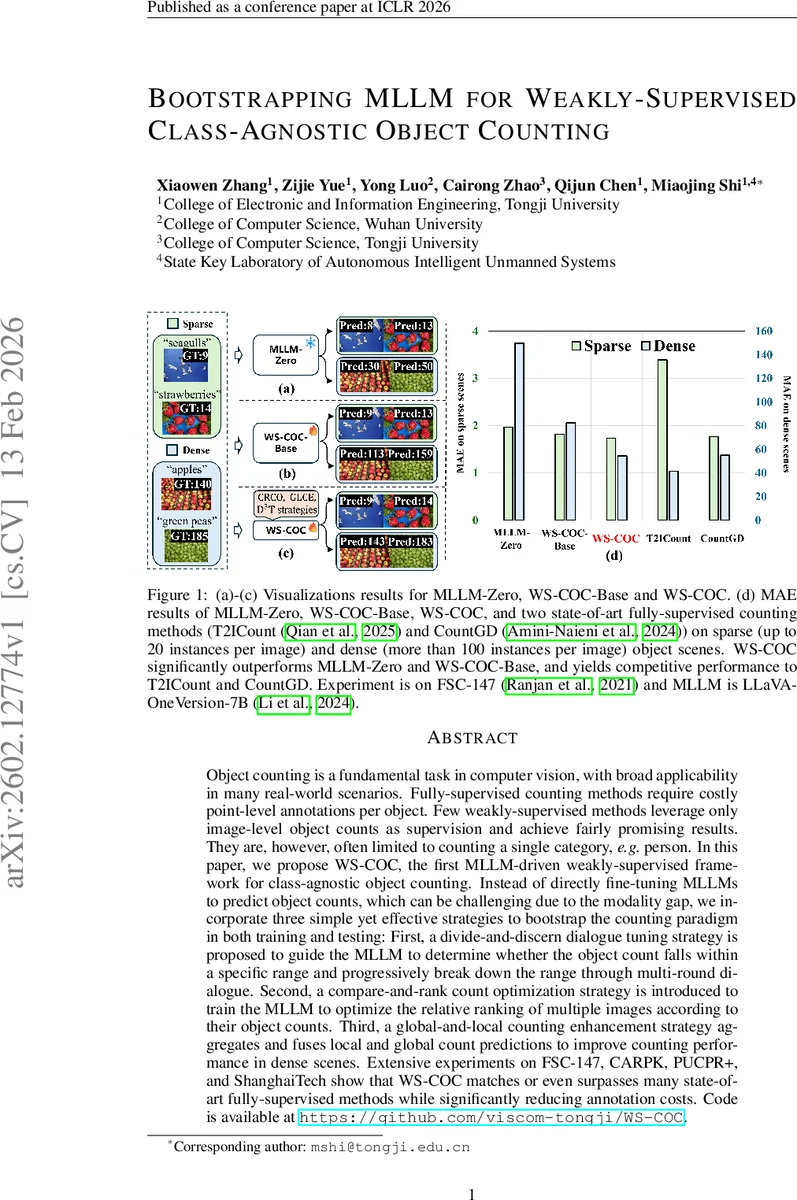
Object counting is a fundamental task in computer vision, with broad applicability in many real-world scenarios. Fully-supervised counting methods require costly point-level annotations per object. Few weakly-supervised methods leverage only image-level object counts as supervision and achieve fairly promising results. They are, however, often limited to counting a single category, e.g. person. In this paper, we propose WS-COC, the first MLLM-driven weakly-supervised framework for class-agnostic object counting. Instead of directly fine-tuning MLLMs to predict object counts, which can be challenging due to the modality gap, we incorporate three simple yet effective strategies to bootstrap the counting paradigm in both training and testing: First, a divide-and-discern dialogue tuning strategy is proposed to guide the MLLM to determine whether the object count falls within a specific range and progressively break down the range through multi-round dialogue. Second, a compare-and-rank count optimization strategy is introduced to train the MLLM to optimize the relative ranking of multiple images according to their object counts. Third, a global-and-local counting enhancement strategy aggregates and fuses local and global count predictions to improve counting performance in dense scenes. Extensive experiments on FSC-147, CARPK, PUCPR+, and ShanghaiTech show that WS-COC matches or even surpasses many state-of-art fully-supervised methods while significantly reducing annotation costs. Code is available at https://github.com/viscom-tongji/WS-COC.
💡 Research Summary
Object counting is a fundamental vision problem with wide‑range applications, yet fully‑supervised approaches demand costly point‑level annotations for every instance. Recent weakly‑supervised methods have reduced this burden by using only image‑level counts, but they are typically limited to a single class (e.g., people) and still rely on conventional CNN or ViT backbones. This paper introduces WS‑COC, the first multimodal large language model (MLLM)‑driven framework that performs class‑agnostic counting under a weakly‑supervised regime, requiring only image‑level counts as supervision.
The authors first evaluate a zero‑shot baseline (MLLM‑Zero) that feeds a prompt such as “How many
Comments & Academic Discussion
Loading comments...
Leave a Comment