Explaining and Mitigating the Modality Gap in Contrastive Multimodal Learning
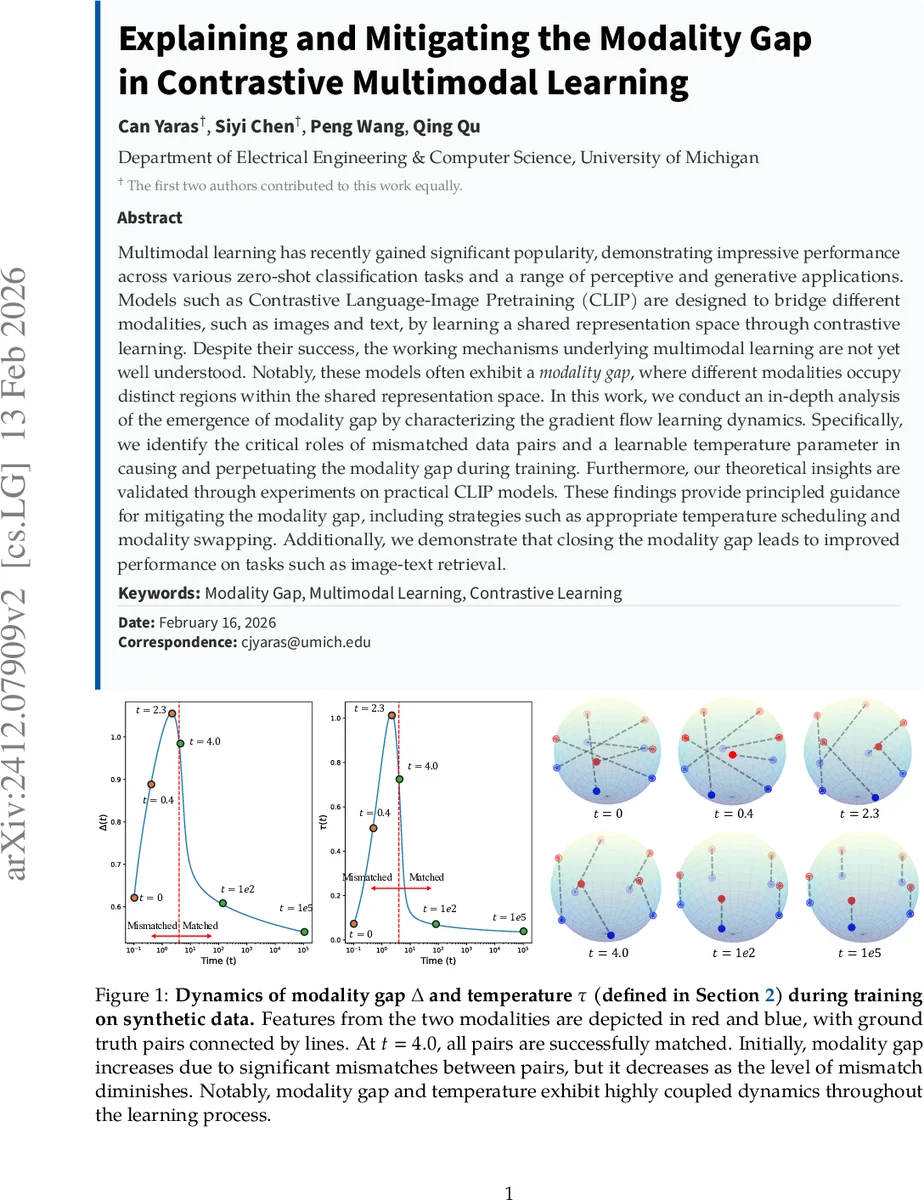
Multimodal learning has recently gained significant popularity, demonstrating impressive performance across various zero-shot classification tasks and a range of perceptive and generative applications. Models such as Contrastive Language-Image Pretraining (CLIP) are designed to bridge different modalities, such as images and text, by learning a shared representation space through contrastive learning. Despite their success, the working mechanisms underlying multimodal learning are not yet well understood. Notably, these models often exhibit a modality gap, where different modalities occupy distinct regions within the shared representation space. In this work, we conduct an in-depth analysis of the emergence of modality gap by characterizing the gradient flow learning dynamics. Specifically, we identify the critical roles of mismatched data pairs and a learnable temperature parameter in causing and perpetuating the modality gap during training. Furthermore, our theoretical insights are validated through experiments on practical CLIP models. These findings provide principled guidance for mitigating the modality gap, including strategies such as appropriate temperature scheduling and modality swapping. Additionally, we demonstrate that closing the modality gap leads to improved performance on tasks such as image-text retrieval.
💡 Research Summary
This paper investigates the persistent “modality gap” observed in contrastive multimodal models such as CLIP, where image and text embeddings occupy distinct regions of a shared representation space despite being trained to align. The authors adopt a rigorous theoretical approach based on continuous‑time gradient flow to dissect the learning dynamics of the vision encoder θ, the language encoder ϕ, a learnable temperature parameter ν (with inverse temperature β = exp(ν)), and a parallelism coefficient γ that measures how parallel the two modality embeddings are.
First, the problem is formalized: paired data {(x_i, y_i)} are embedded, ℓ₂‑normalized, and fed into a symmetric cross‑entropy loss that maximizes diagonal entries of β Hₓ H_yᵀ while minimizing off‑diagonal ones. By imposing a parallel‑embedding constraint (˜Hₓ =
Comments & Academic Discussion
Loading comments...
Leave a Comment