Gaia2: Benchmarking LLM Agents on Dynamic and Asynchronous Environments
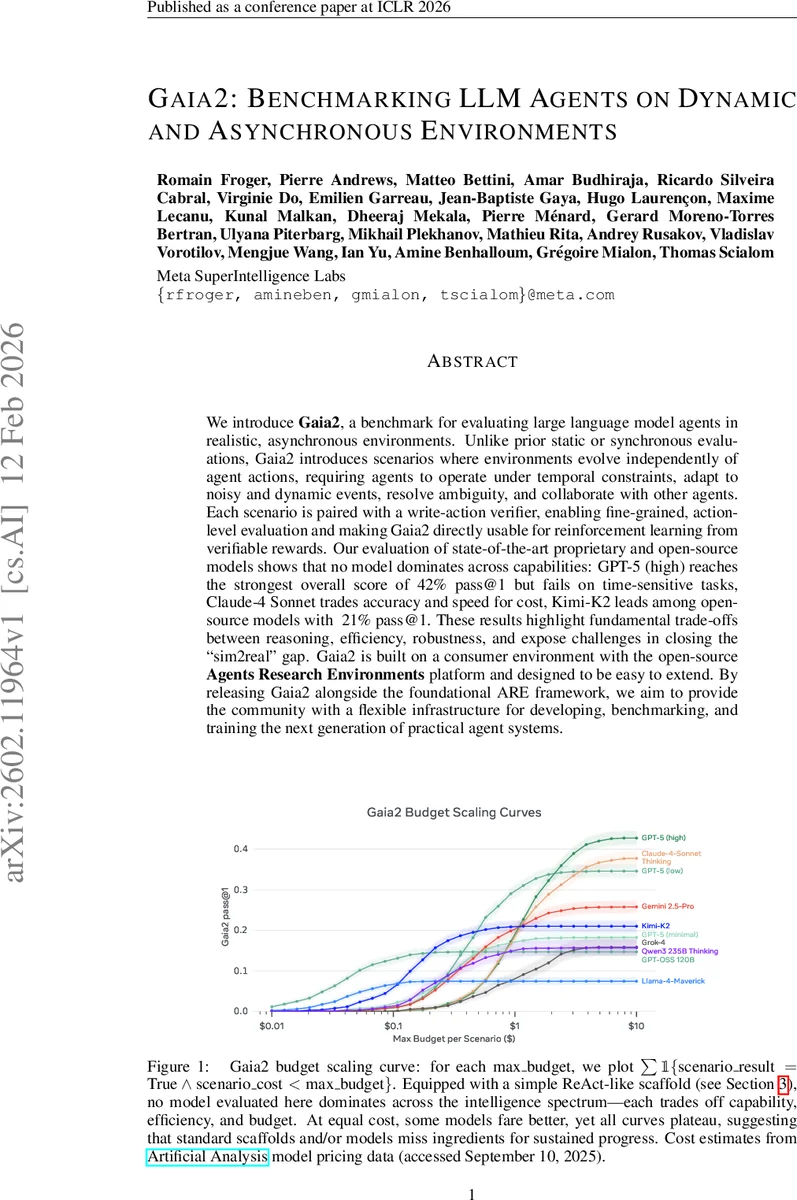
We introduce Gaia2, a benchmark for evaluating large language model agents in realistic, asynchronous environments. Unlike prior static or synchronous evaluations, Gaia2 introduces scenarios where environments evolve independently of agent actions, requiring agents to operate under temporal constraints, adapt to noisy and dynamic events, resolve ambiguity, and collaborate with other agents. Each scenario is paired with a write-action verifier, enabling fine-grained, action-level evaluation and making Gaia2 directly usable for reinforcement learning from verifiable rewards. Our evaluation of state-of-the-art proprietary and open-source models shows that no model dominates across capabilities: GPT-5 (high) reaches the strongest overall score of 42% pass@1 but fails on time-sensitive tasks, Claude-4 Sonnet trades accuracy and speed for cost, Kimi-K2 leads among open-source models with 21% pass@1. These results highlight fundamental trade-offs between reasoning, efficiency, robustness, and expose challenges in closing the “sim2real” gap. Gaia2 is built on a consumer environment with the open-source Agents Research Environments platform and designed to be easy to extend. By releasing Gaia2 alongside the foundational ARE framework, we aim to provide the community with a flexible infrastructure for developing, benchmarking, and training the next generation of practical agent systems.
💡 Research Summary
**
The paper introduces Gaia2, a benchmark designed to evaluate large language model (LLM) agents in realistic, asynchronous environments. Existing agent benchmarks are largely static or synchronous: the environment only changes when the agent acts, and evaluation typically focuses on final outcomes. This design fails to capture challenges that arise in real deployments, such as handling events that occur while the model is reasoning, operating under strict temporal constraints, coping with noisy inputs, resolving ambiguous instructions, and collaborating with other agents.
To address these gaps, the authors build two core contributions. First, they release the Agents Research Environments (ARE) framework, a general‑purpose platform for constructing event‑driven, time‑advancing simulations that run independently of the agent. ARE models each application (e.g., messaging, email, calendar) as a stateful API with read‑only and write tools. A time manager advances the simulated clock continuously, so external events can happen while the model is generating a response. This enables precise measurement of temporal awareness and reactivity, which are impossible in synchronous setups.
Second, they construct Gaia2 on top of ARE, providing a mobile‑phone‑like environment with twelve apps and 101 tools. Human annotators authored 1,120 scenarios across ten “universes,” each scenario paired with a write‑action verifier. The verifier checks every state‑changing action against oracle annotations, allowing fine‑grained, reproducible credit assignment and making the benchmark directly usable for reinforcement learning from verifiable rewards (RL‑VR). Scenarios are organized into seven capability splits: Execution, Search, Ambiguity, Adaptability, Time, Noise, and Agent‑to‑Agent (A2A). The Noise split injects tool failures and irrelevant events; the A2A split replaces apps with “app‑agents” that the main agent must coordinate with, testing robustness and multi‑agent collaboration.
The evaluation pipeline uses a ReAct‑style loop where the model emits a single structured tool call per step. Pre‑step hooks inject pending notifications into the model’s context, and post‑step hooks check termination conditions. A parallel‑tool‑calling variant was tested and found to improve wall‑clock efficiency but not overall success rates, indicating that bottlenecks are model‑intrinsic rather than orchestration‑related.
Results on a suite of proprietary (GPT‑5‑high, GPT‑5‑low, Claude‑4‑Sonnet) and open‑source models (Kimi‑K2, Llama‑4‑Maverick, Qwen3‑235B, etc.) show that no single model dominates across all capabilities. GPT‑5‑high achieves the highest overall pass@1 of 42 % but performs poorly on time‑sensitive tasks (≈18 %). Claude‑4‑Sonnet balances accuracy, speed, and cost, while Kimi‑K2 is the best open‑source performer at 21 % pass@1. The trade‑offs observed—reasoning strength versus speed, robustness versus cost—highlight the “sim2real” gap: current agents excel at isolated reasoning but struggle when environmental dynamics, latency, and noise are introduced.
The paper emphasizes that Gaia2’s action‑level verification enables direct reward signals for RL‑VR, opening a path toward training agents that can learn from fine‑grained feedback rather than coarse preference models. Moreover, the authors demonstrate that ARE can faithfully re‑implement existing benchmarks (τ‑bench, VendingBench, MultiAgentBench), proving its extensibility to other domains such as desktop automation, customer‑support bots, or web browsing.
Limitations include reliance on human‑written annotations for scenario creation and the added complexity of evaluating asynchronous behavior. Future work suggested includes automated scenario generation, meta‑reward learning, standardized multi‑agent communication protocols, and more cost‑effective RL‑VR algorithms.
In summary, Gaia2 and the ARE platform together provide a flexible, verifiable, and dynamically rich testbed that pushes LLM agents beyond static reasoning toward the robust, time‑aware, collaborative systems needed for real‑world deployment.
Comments & Academic Discussion
Loading comments...
Leave a Comment