Gradient Compression May Hurt Generalization: A Remedy by Synthetic Data Guided Sharpness Aware Minimization
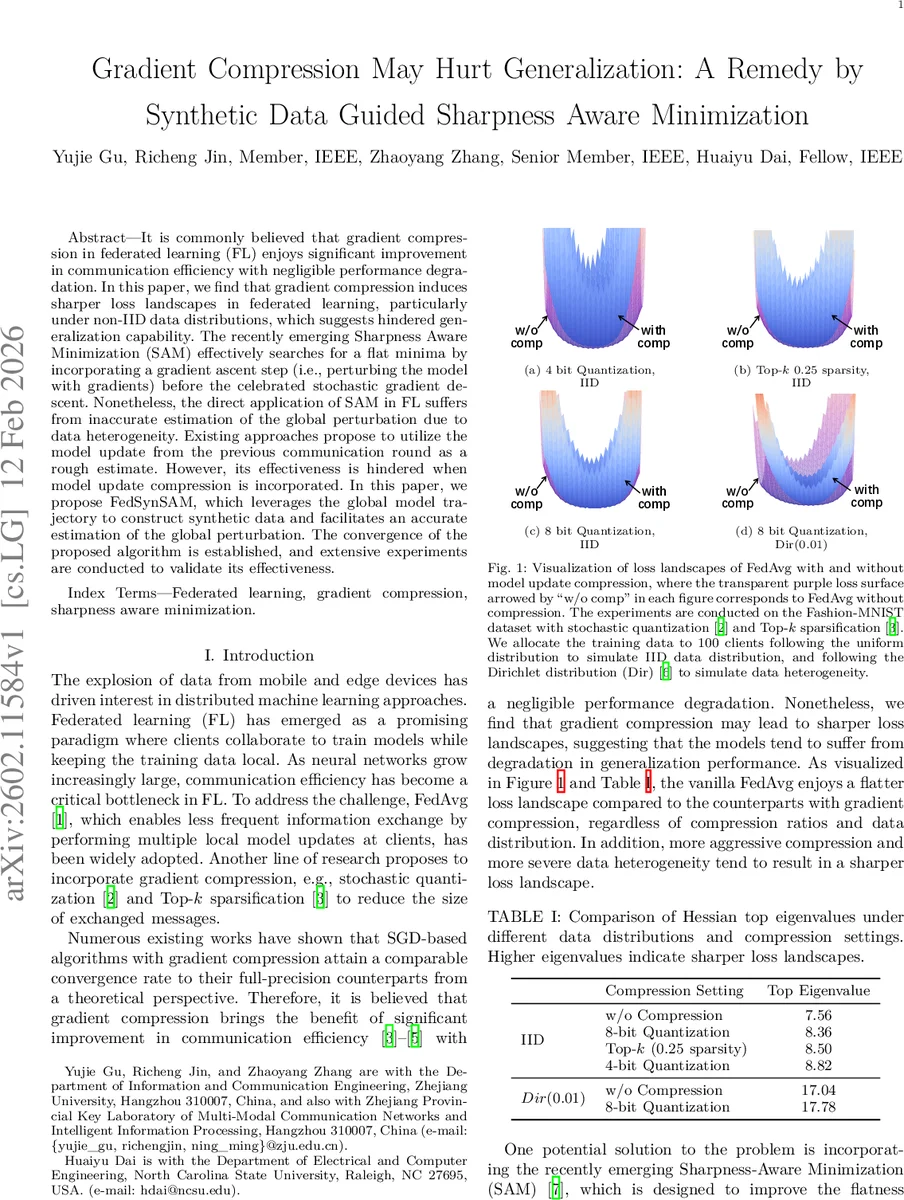
It is commonly believed that gradient compression in federated learning (FL) enjoys significant improvement in communication efficiency with negligible performance degradation. In this paper, we find that gradient compression induces sharper loss landscapes in federated learning, particularly under non-IID data distributions, which suggests hindered generalization capability. The recently emerging Sharpness Aware Minimization (SAM) effectively searches for a flat minima by incorporating a gradient ascent step (i.e., perturbing the model with gradients) before the celebrated stochastic gradient descent. Nonetheless, the direct application of SAM in FL suffers from inaccurate estimation of the global perturbation due to data heterogeneity. Existing approaches propose to utilize the model update from the previous communication round as a rough estimate. However, its effectiveness is hindered when model update compression is incorporated. In this paper, we propose FedSynSAM, which leverages the global model trajectory to construct synthetic data and facilitates an accurate estimation of the global perturbation. The convergence of the proposed algorithm is established, and extensive experiments are conducted to validate its effectiveness.
💡 Research Summary
This paper investigates the often‑overlooked impact of gradient compression on the generalization ability of federated learning (FL) systems. While compression techniques such as stochastic quantization and Top‑k sparsification are widely adopted to reduce communication overhead, prior work mainly focuses on convergence speed and assumes negligible effect on model performance. Through extensive empirical analysis, the authors demonstrate that compression systematically increases the sharpness of the loss landscape—measured by the top eigenvalue of the Hessian—especially under non‑IID data distributions. Sharper minima are known to correlate with poorer generalization, indicating that compression can indeed degrade test accuracy.
To mitigate this issue, the paper revisits Sharpness‑Aware Minimization (SAM), a recent optimization framework that seeks flat minima by first perturbing the model parameters in the direction of the gradient (the “ascent” step) and then performing a descent step on the perturbed model. Directly applying SAM in FL (FedSAM) replaces the global gradient with each client’s local gradient for the ascent step. However, in heterogeneous settings the local gradient can deviate substantially from the true global gradient, leading to an inaccurate perturbation and reduced effectiveness of SAM. Existing remedies—FedLESAM, which uses the previous round’s model update as a proxy for the global perturbation, and FedSMOO, which adds a dynamic regularizer via ADMM—either suffer from large estimation errors when compression is present or double the uplink communication cost.
The authors propose FedSynSAM, a novel method that constructs a synthetic dataset from the trajectory of the global model across communication rounds. The synthetic data is optimized so that training the global model on it reproduces the observed parameter trajectory (trajectory matching). Formally, they solve a bi‑level problem: minimize over synthetic inputs X and label distribution α the expected discrepancy between the gradient computed on the synthetic data, ∇F(w_t, D_syn), and the true global gradient ∇F(w_t). Since the true global gradient is unavailable, the trajectory of the model (the sequence {w_t, …, w_{t+s}}) serves as a surrogate; the synthetic data is adjusted so that after s local SGD steps on D_syn, the model reaches a point close to w_{t+s}. Once D_syn is obtained, each client can compute an accurate estimate of the global perturbation ϵ̂_t = ρ ∇F(w_t, D_syn)/‖∇F(w_t, D_syn)‖ and use it in the SAM ascent step, eliminating the need for extra communication.
Theoretical analysis shows that if the perturbation estimation error is bounded by ε, the convergence rate of FedSynSAM degrades only by O(ε), preserving the favorable properties of SAM. Moreover, the authors quantify how compression error (modeled as unbiased stochastic noise) influences the overall convergence bound, demonstrating robustness to both compression and data heterogeneity.
Empirical evaluation spans CIFAR‑10, Fashion‑MNIST, and SVHN with 100 clients, employing both Dirichlet‑based non‑IID splits (α = 0.01) and pathological label distributions. Compression settings include 4‑bit stochastic quantization and Top‑k sparsity of 0.25. FedSynSAM consistently outperforms FedAvg, FedAvg with compression, FedSAM, FedLESAM, and FedSMOO in test accuracy, especially when compression is aggressive. It also achieves lower Hessian top eigenvalues, confirming flatter minima. Cosine similarity between the true global perturbation and the estimated one is above 0.9 for FedSynSAM versus around 0.7 for FedLESAM, indicating a much more accurate perturbation estimate. Importantly, the synthetic dataset is generated solely on the server; no additional uplink traffic is required, keeping communication overhead comparable to existing SAM‑based FL methods.
In conclusion, FedSynSAM offers a practical solution to the trade‑off between communication efficiency and generalization in federated learning. By leveraging the global model trajectory to synthesize data that faithfully captures the aggregate gradient information, it enables precise SAM perturbations even under severe compression and data heterogeneity. Future work may explore lightweight synthetic data generation, asynchronous FL scenarios, and integration with other regularization techniques to further enhance scalability and robustness.
Comments & Academic Discussion
Loading comments...
Leave a Comment