SnapMLA: Efficient Long-Context MLA Decoding via Hardware-Aware FP8 Quantized Pipelining
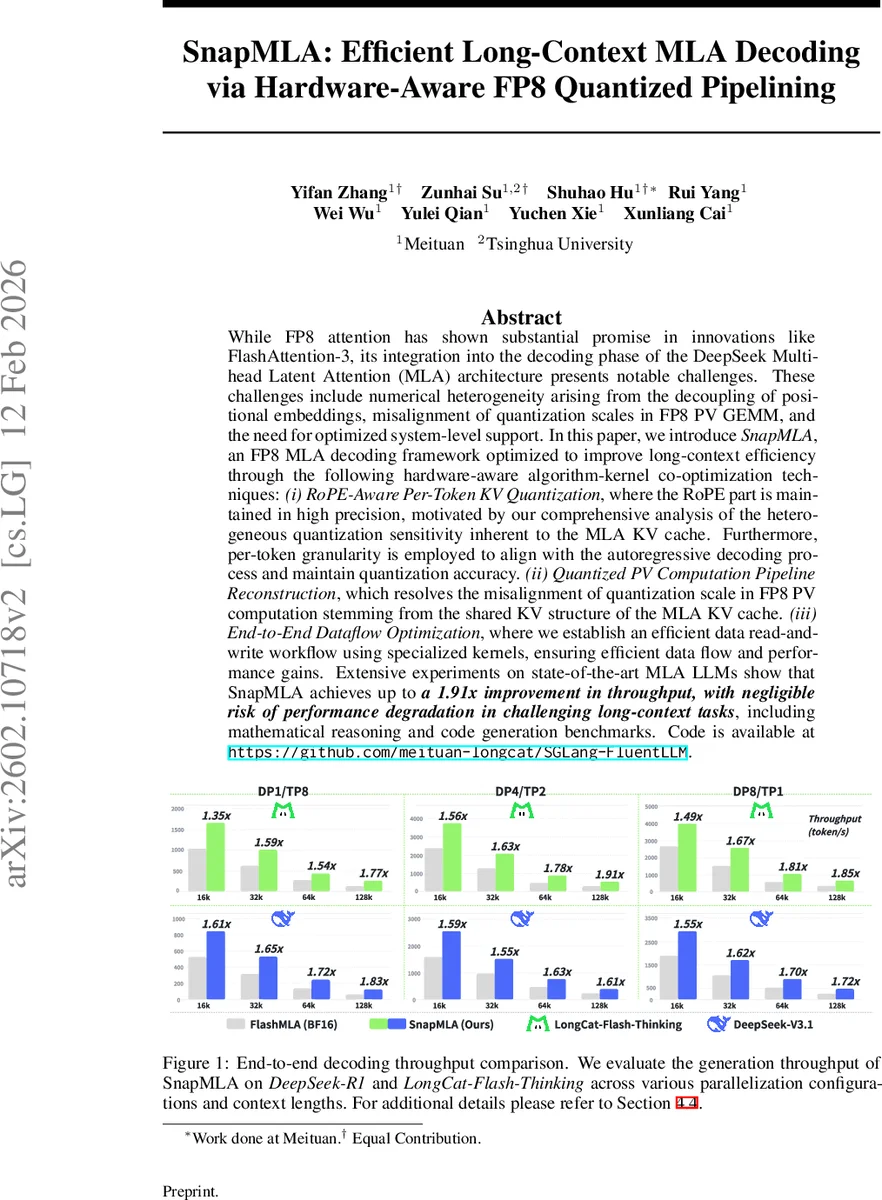
While FP8 attention has shown substantial promise in innovations like FlashAttention-3, its integration into the decoding phase of the DeepSeek Multi-head Latent Attention (MLA) architecture presents notable challenges. These challenges include numerical heterogeneity arising from the decoupling of positional embeddings, misalignment of quantization scales in FP8 PV GEMM, and the need for optimized system-level support. In this paper, we introduce SnapMLA, an FP8 MLA decoding framework optimized to improve long-context efficiency through the following hardware-aware algorithm-kernel co-optimization techniques: (i) RoPE-Aware Per-Token KV Quantization, where the RoPE part is maintained in high precision, motivated by our comprehensive analysis of the heterogeneous quantization sensitivity inherent to the MLA KV cache. Furthermore, per-token granularity is employed to align with the autoregressive decoding process and maintain quantization accuracy. (ii) Quantized PV Computation Pipeline Reconstruction, which resolves the misalignment of quantization scale in FP8 PV computation stemming from the shared KV structure of the MLA KV cache. (iii) End-to-End Dataflow Optimization, where we establish an efficient data read-and-write workflow using specialized kernels, ensuring efficient data flow and performance gains. Extensive experiments on state-of-the-art MLA LLMs show that SnapMLA achieves up to a 1.91x improvement in throughput, with negligible risk of performance degradation in challenging long-context tasks, including mathematical reasoning and code generation benchmarks. Code is available at https://github.com/meituan-longcat/SGLang-FluentLLM.
💡 Research Summary
SnapMLA presents a comprehensive solution for accelerating the decoding phase of Large Language Models (LLMs) that employ the Multi‑head Latent Attention (MLA) architecture, by leveraging FP8 quantization in a hardware‑aware manner. The authors first identify three fundamental obstacles that prevent straightforward FP8 deployment in MLA decoding. The first obstacle is numerical heterogeneity: MLA splits each token’s KV cache into a low‑dimensional compressed content vector and a high‑precision Rotational Position Embedding (RoPE) vector. Empirical analysis on the LongCat‑Flash‑Thinking model shows that the RoPE component spans a dynamic range up to ±10³, while the content component stays within ±10¹. Uniform FP8 quantization dramatically increases the mean‑squared error of RoPE, jeopardizing positional accuracy. To address this, SnapMLA introduces RoPE‑Aware Per‑Token KV Quantization, which quantizes only the content part to FP8, keeps RoPE in BF16, and operates at token granularity. This eliminates the “tail buffer” problem that arises with block‑wise quantization during autoregressive generation and simplifies integration with existing inference frameworks such as vLLM and SGLang.
The second obstacle concerns the FP8 PV (Projection‑Value) GEMM on NVIDIA Hopper Tensor Cores. Hopper requires a k‑major memory layout for the V matrix, but MLA’s shared KV structure aligns V’s per‑token quantization scales along the reduction dimension, breaking the conventional post‑GEMM dequantization workflow. SnapMLA resolves this with a Scale‑Fusion PV Quantization pipeline. It fuses the V scaling factor (S_V) directly into the attention probability matrix P, forming P′ = P ⊙ S_V. Because this fusion expands the dynamic range of P, the authors apply block‑wise dynamic quantization with a block size matching the PV GEMM tiling parameter (64). The quantization scales are then implicitly handled inside the Softmax operation, providing automatic dequantization without extra arithmetic. This four‑stage pipeline (Normalization → Scale Fusion → Quantization → Computation) respects hardware constraints while eliminating costly scale‑mismatch handling.
The third obstacle is system‑level inefficiency. To support the new quantization scheme, the authors develop custom CUDA kernels that pre‑scale the BF16 RoPE components by the inverse of the content quantization scale, effectively mapping RoPE into the FP8 domain before the QK GEMM. This “Pre‑Scaled Domain Alignment” allows the existing highly‑optimized QK GEMM kernel to run without mixed‑precision accumulation or synchronization barriers, preserving pipeline depth and throughput. Additionally, they streamline data movement by constructing an end‑to‑end read‑write workflow that overlaps memory transfers with computation, reducing kernel launch latency and memory bandwidth pressure.
Experimental evaluation covers two state‑of‑the‑art MLA models: DeepSeek‑R1 and LongCat‑Flash‑Thinking. Benchmarks span context lengths from 2 K to 32 K tokens, various batch sizes, and multiple parallel configurations. SnapMLA achieves up to 1.91× higher token‑generation throughput compared with baseline FP16/FP8 implementations, while maintaining negligible degradation on challenging long‑context tasks such as mathematical reasoning (MATH) and code generation (CodeXGLUE). Memory consumption drops by over 30 % thanks to the combined effect of latent compression and FP8 KV storage.
In summary, SnapMLA demonstrates that a careful analysis of MLA’s numerical characteristics, coupled with hardware‑conscious algorithmic redesign, can unlock the full potential of FP8 quantization for long‑context decoding. The work not only provides immediate performance gains for current NVIDIA Hopper GPUs but also offers a blueprint for extending low‑bit quantization techniques to other formats (e.g., INT4) and hardware platforms. The authors release their implementation at https://github.com/meituan‑longcat/SGLang‑FluentLLM, facilitating reproducibility and future research.
Comments & Academic Discussion
Loading comments...
Leave a Comment