Spend Search Where It Pays: Value-Guided Structured Sampling and Optimization for Generative Recommendation
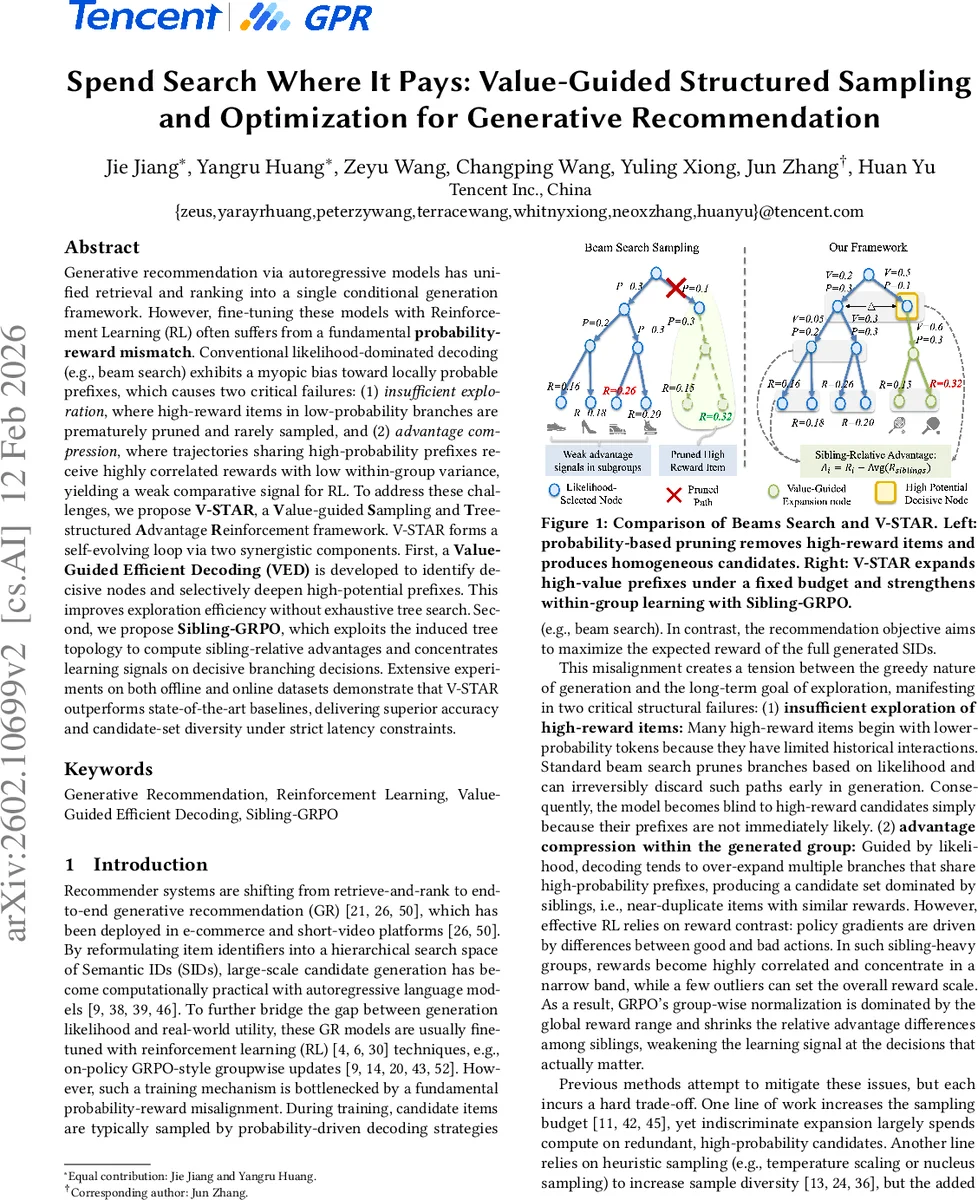
Generative recommendation via autoregressive models has unified retrieval and ranking into a single conditional generation framework. However, fine-tuning these models with Reinforcement Learning (RL) often suffers from a fundamental probability-reward mismatch. Conventional likelihood-dominated decoding (e.g., beam search) exhibits a myopic bias toward locally probable prefixes, which causes two critical failures: (1) insufficient exploration, where high-reward items in low-probability branches are prematurely pruned and rarely sampled, and (2) advantage compression, where trajectories sharing high-probability prefixes receive highly correlated rewards with low within-group variance, yielding a weak comparative signal for RL. To address these challenges, we propose V-STAR, a Value-guided Sampling and Tree-structured Advantage Reinforcement framework. V-STAR forms a self-evolving loop via two synergistic components. First, a Value-Guided Efficient Decoding (VED) is developed to identify decisive nodes and selectively deepen high-potential prefixes. This improves exploration efficiency without exhaustive tree search. Second, we propose Sibling-GRPO, which exploits the induced tree topology to compute sibling-relative advantages and concentrates learning signals on decisive branching decisions. Extensive experiments on both offline and online datasets demonstrate that V-STAR outperforms state-of-the-art baselines, delivering superior accuracy and candidate-set diversity under strict latency constraints.
💡 Research Summary
This paper tackles a fundamental mismatch between model probability and downstream reward that hampers reinforcement‑learning (RL) fine‑tuning of autoregressive generative recommendation systems. Conventional decoding methods such as beam search prioritize locally probable prefixes, which leads to two intertwined problems: (1) insufficient exploration, because high‑reward items that start with low‑probability tokens are pruned early and rarely sampled; and (2) advantage compression, where candidates sharing high‑probability prefixes form homogeneous groups, resulting in a narrow reward range and weak gradient signals for policy updates.
To remedy these issues, the authors propose V‑STAR (Value‑guided Structured Sampling and Optimization for generative recommendation), a self‑evolving framework that couples a novel decoding strategy with a tree‑structured policy‑gradient objective. The first component, Value‑Guided Efficient Decoding (VED), first runs a shallow beam search to expose the prefix tree, then evaluates each prefix with a lightweight value network Vφ and an uncertainty measure (e.g., policy entropy). Nodes that are both high‑value and high‑ambiguity are deemed “decisive” and receive additional compute: the decoder expands these nodes deeper and with larger branching factors while respecting a strict budget. This targeted expansion rescues low‑probability but high‑reward branches without performing exhaustive tree search.
The value network is trained with dense semantic supervision. Instead of waiting for sparse terminal rewards, the authors construct intermediate returns by averaging frozen text‑encoder embeddings of all sampled items that share a given prefix. The return for a prefix is a weighted combination of a monotonic step weight and the cosine similarity between the prefix embedding and the ground‑truth item embedding. This provides informative feedback for every intermediate state, enabling fast and accurate value estimation.
The second component, Sibling‑GRPO, addresses advantage compression. It groups candidates that share the same parent prefix into sibling sets and computes advantages relative to the mean and standard deviation within each set, rather than across the whole candidate pool. By normalizing locally, the method amplifies reward differences among competing branches, reduces gradient variance, and aligns with list‑wise ranking principles.
VED and Sibling‑GRPO form a positive feedback loop: better sampling yields more diverse and high‑value candidates, which in turn produces stronger relative advantages for the policy update; the updated policy improves the value estimates, leading to even more focused exploration in the next iteration.
Experiments on both offline benchmark datasets and a large‑scale online A/B test demonstrate consistent gains. V‑STAR outperforms strong baselines—including beam‑search + GRPO, temperature‑scaled sampling, and Monte‑Carlo tree search variants—by 4–7 % on CTR, NDCG, and diversity metrics while staying within a 30 ms latency budget. Notably, exposure of long‑tail items more than doubles, and the variance of policy gradients drops by roughly 35 % when using sibling‑GRPO, indicating improved training stability.
In summary, V‑STAR introduces (1) a value‑guided decoding that allocates compute to the most reward‑relevant parts of the generation tree, and (2) a tree‑structured sibling advantage objective that restores informative learning signals. Together they resolve the probability‑reward misalignment that has limited generative recommendation systems, offering a practical solution for real‑time, large‑scale recommendation platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment