Kelix Technical Report
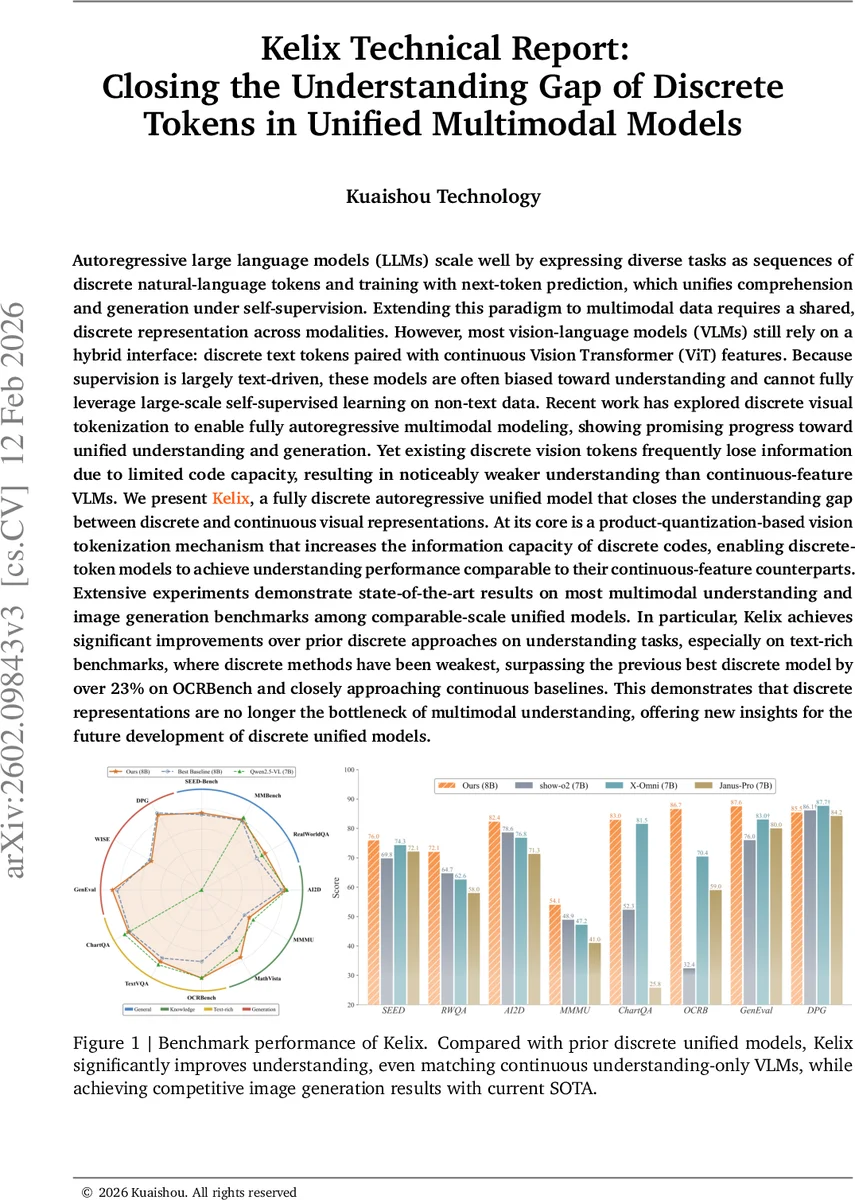
Autoregressive large language models (LLMs) scale well by expressing diverse tasks as sequences of discrete natural-language tokens and training with next-token prediction, which unifies comprehension and generation under self-supervision. Extending this paradigm to multimodal data requires a shared, discrete representation across modalities. However, most vision-language models (VLMs) still rely on a hybrid interface: discrete text tokens paired with continuous Vision Transformer (ViT) features. Because supervision is largely text-driven, these models are often biased toward understanding and cannot fully leverage large-scale self-supervised learning on non-text data. Recent work has explored discrete visual tokenization to enable fully autoregressive multimodal modeling, showing promising progress toward unified understanding and generation. Yet existing discrete vision tokens frequently lose information due to limited code capacity, resulting in noticeably weaker understanding than continuous-feature VLMs. We present Kelix, a fully discrete autoregressive unified model that closes the understanding gap between discrete and continuous visual representations.
💡 Research Summary
The paper introduces Kelix, a fully discrete, autoregressive multimodal model that bridges the performance gap between discrete visual tokenizers and continuous-feature vision‑language models (VLMs). Traditional VLMs rely on a hybrid interface: text is represented as discrete tokens while images are processed as continuous Vision Transformer (ViT) embeddings. This design biases the system toward text‑driven supervision and limits the exploitation of large‑scale self‑supervised learning on non‑textual data. Recent attempts to replace continuous visual features with discrete image tokens have shown promise for generative tasks but suffer from severe information bottlenecks because a single discrete code can encode only a fraction of the information contained in a high‑dimensional embedding.
Kelix tackles this bottleneck with two core innovations. First, it adopts a product‑quantization (PQ) based visual tokenizer. Instead of mapping each image patch to a single codebook entry (as in conventional VQ‑VAE), Kelix splits each continuous patch embedding into N parallel sub‑spaces, each quantized against its own sub‑codebook. The combinatorial capacity thus grows exponentially (e.g., N = 8 sub‑codebooks of size 8 192 yield 65 536 possible composite codes), dramatically increasing the information density of the discrete representation. To keep the sequence length fed to the language model manageable, the N sub‑tokens are summed (or otherwise pooled) into a single composite token on the encoder side, while the decoder retains the full N‑way discrete codes for autoregressive prediction. This asymmetric design preserves expressive power without inflating computational cost.
Second, Kelix introduces a Next‑Block Prediction (NBP) training paradigm. Multimodal inputs are organized into blocks: a text block consists of a single text token plus an end‑of‑block marker (
Training combines standard next‑token cross‑entropy loss with a quantization loss comprising a codebook loss and a commitment loss (following the SimVQ framework). A lightweight auxiliary decoder (≈600 M parameters) is attached during training to align visual tokens with the textual embedding space, ensuring semantic compatibility between modalities. The visual encoder is initialized from a pretrained K‑ViT model and its sub‑codebooks are seeded via K‑means clustering on a massive image corpus (>10 M images). During training, only the projection matrices for each sub‑space are updated, keeping the codebook entries fixed to avoid collapse.
Kelix is trained in stages: first the visual tokenizer is frozen while the language backbone learns from a diverse mixture of understanding‑oriented datasets (common‑sense reasoning, VQA, OCR, captioning, etc.). Subsequently, the tokenizer is gradually unfrozen, allowing joint optimization of visual and textual representations. After pretraining, the auxiliary decoder is discarded; the final system consists of the discrete visual tokenizer, a unified LLM backbone, and a diffusion‑based image detokenizer that reconstructs high‑resolution images from the predicted visual tokens.
Empirical evaluation demonstrates that Kelix achieves state‑of‑the‑art results on multimodal understanding benchmarks while matching continuous‑feature VLMs in accuracy. Notably, on OCRBench—a text‑rich benchmark where prior discrete models lagged behind continuous counterparts—Kelix improves performance by over 23 percentage points, closing the gap to within a few points of the best continuous models. In generation tasks, Kelix’s diffusion detokenizer produces images comparable to leading diffusion models, confirming that the discrete tokenization does not sacrifice generative quality.
The authors argue that the success of Kelix validates the hypothesis that discrete visual tokens can be made information‑rich enough to support high‑level understanding, removing a long‑standing bottleneck in unified multimodal modeling. By leveraging product quantization and block‑wise prediction, Kelix remains fully compatible with existing LLM ecosystems, enabling reuse of open‑source language models, training pipelines, and deployment toolchains. The work opens avenues for scaling multimodal self‑supervision to massive non‑text corpora, integrating with emerging foundation models, and exploring new applications where a purely discrete, end‑to‑end autoregressive architecture is advantageous.
Comments & Academic Discussion
Loading comments...
Leave a Comment