Inspiration Seeds: Learning Non-Literal Visual Combinations for Generative Exploration
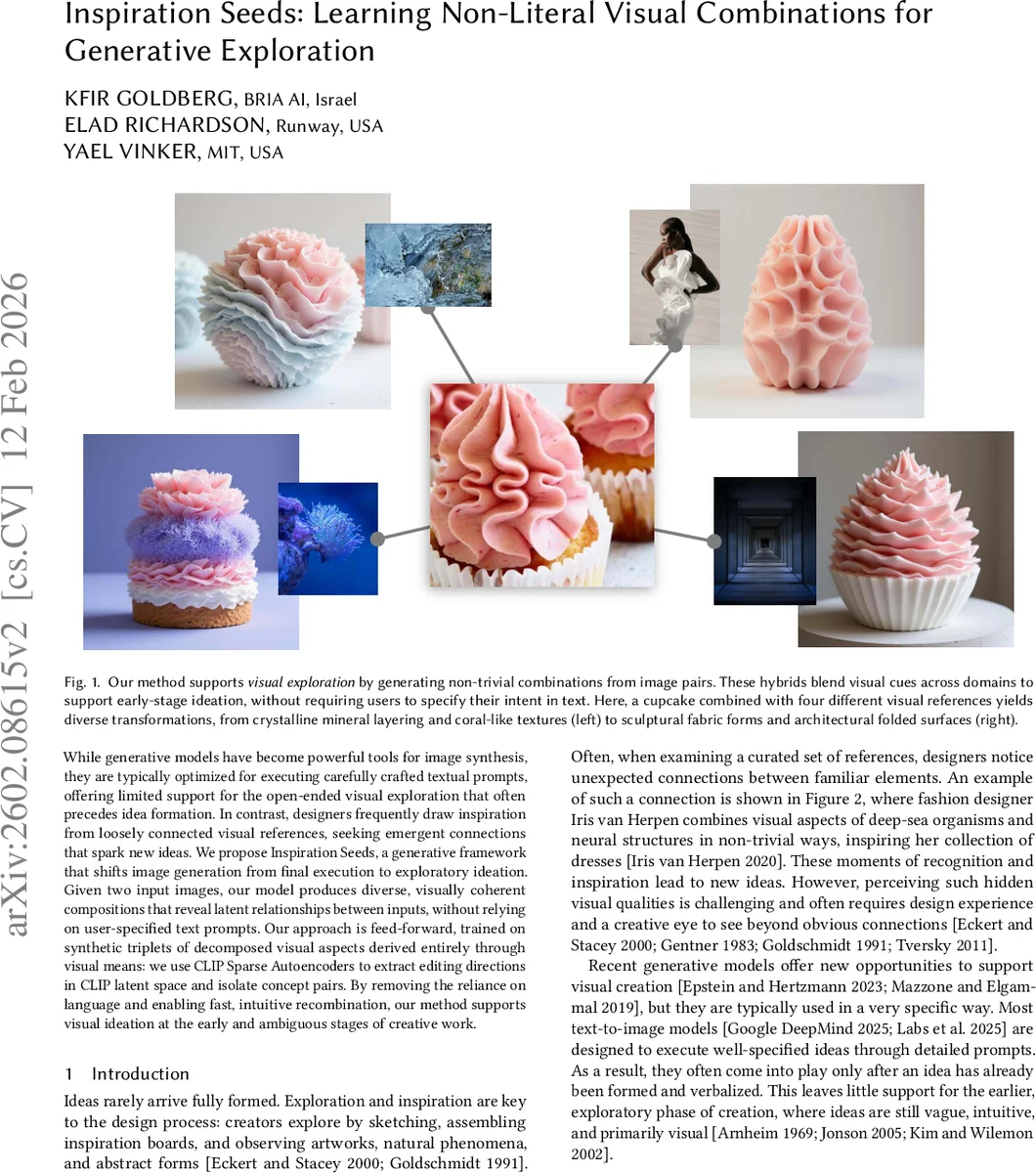
While generative models have become powerful tools for image synthesis, they are typically optimized for executing carefully crafted textual prompts, offering limited support for the open-ended visual exploration that often precedes idea formation. In contrast, designers frequently draw inspiration from loosely connected visual references, seeking emergent connections that spark new ideas. We propose Inspiration Seeds, a generative framework that shifts image generation from final execution to exploratory ideation. Given two input images, our model produces diverse, visually coherent compositions that reveal latent relationships between inputs, without relying on user-specified text prompts. Our approach is feed-forward, trained on synthetic triplets of decomposed visual aspects derived entirely through visual means: we use CLIP Sparse Autoencoders to extract editing directions in CLIP latent space and isolate concept pairs. By removing the reliance on language and enabling fast, intuitive recombination, our method supports visual ideation at the early and ambiguous stages of creative work.
💡 Research Summary
Inspiration Seeds tackles a fundamental gap in current generative AI: the lack of support for early‑stage, non‑verbal visual ideation. While most text‑to‑image models excel at executing well‑specified prompts, they offer little help when designers are still exploring vague, intuitive concepts and rely on loosely related visual references. The authors propose a feed‑forward framework that takes two images as input and produces multiple, visually coherent hybrids that expose latent relationships between the inputs, all without any textual supervision.
The technical backbone consists of three parts: (1) CLIP Sparse Autoencoders (SAE) are used to decompose a single image into a small set of sparse, monosemantic visual factors. An image is encoded with CLIP, passed through the SAE encoder, and the top‑k activations are selected, decoded back to CLIP space, and clustered into two groups via k‑means. The difference between the cluster centroids defines an editing direction that isolates two complementary visual aspects of the original image. Moving the original CLIP embedding along this direction in opposite signs yields two embeddings that, when decoded by a diffusion model, generate two “aspect‑emphasized” images (I_A and I_B). (2) Synthetic triplet generation: each original image (I_comb) serves as the ground‑truth combination of its two decomposed aspects (I_A, I_B). To obtain a large and diverse pool of such images, the authors employ two strategies: (a) templated prompts that explicitly request multiple visual attributes (material, color, shape, context) and (b) vague prompts expanded by large language models into richer descriptions, then rendered by a text‑to‑image model. This yields a dataset of millions of (I_A, I_B, I_comb) triples without any human annotation. (3) Model fine‑tuning: The authors fine‑tune Flux.1 Kontext, a state‑of‑the‑art image‑to‑image diffusion model, to map the pair (I_A, I_B) to the target I_comb. The loss combines pixel‑wise L2 reconstruction, CLIP embedding alignment, and a regularization term that encourages the output to retain visual coherence with both inputs.
Evaluation is performed on a variety of image pairs, comparing against leading text‑guided editors such as Nano Banana. Quantitative metrics include a newly introduced Description‑Complexity score (measuring the linguistic complexity of LLM‑generated captions for the outputs) and human judgments of “hidden relationship discovery”. Results show that Inspiration Seeds consistently produces non‑trivial, texture‑ and structure‑rich blends (e.g., decay patterns of a leaf transferred to a portrait’s skin, crystalline layering on a cupcake) that are judged more surprising and conceptually rich than the literal swaps generated by baseline models. Random seed variation leads to diverse outputs, confirming the system’s capacity for open‑ended exploration.
The paper also discusses limitations: SAE‑derived factors are not always perfectly disentangled, occasionally causing over‑mixing; the current system only handles two inputs, leaving multi‑reference composition as future work; and output quality is bounded by the underlying diffusion model’s resolution. Nonetheless, the work demonstrates that visual‑only decomposition and recombination can serve as a powerful ideation aid, shifting generative AI from an execution tool to a partner in the creative discovery process. Future directions include extending the clustering pipeline to more than two aspects, integrating interactive user‑in‑the‑loop feedback, and exploring multimodal reinforcement to further enrich the space of emergent visual metaphors.
Comments & Academic Discussion
Loading comments...
Leave a Comment