Deriving Neural Scaling Laws from the statistics of natural language
Despite the fact that experimental neural scaling laws have substantially guided empirical progress in large-scale machine learning, no existing theory can quantitatively predict the exponents of these important laws for any modern LLM trained on any natural language dataset. We provide the first such theory in the case of data-limited scaling laws. We isolate two key statistical properties of language that alone can predict neural scaling exponents: (i) the decay of pairwise token correlations with time separation between token pairs, and (ii) the decay of the next-token conditional entropy with the length of the conditioning context. We further derive a simple formula in terms of these statistics that predicts data-limited neural scaling exponents from first principles without any free parameters or synthetic data models. Our theory exhibits a remarkable match with experimentally measured neural scaling laws obtained from training GPT-2 and LLaMA style models from scratch on two qualitatively different benchmarks, TinyStories and WikiText.
💡 Research Summary
The paper tackles a long‑standing gap in the theory of neural scaling laws for large language models (LLMs): while empirical power‑law relationships between test loss and dataset size are well documented, no existing framework can predict the actual scaling exponent for a given language and model in the data‑limited regime. The authors propose a first‑principles theory that derives the data‑limited scaling exponent solely from two measurable statistical properties of the training corpus: (i) the decay of token‑to‑token correlations with temporal lag, characterized by an exponent β, and (ii) the decay of the next‑token conditional entropy with context length, characterized by an exponent γ.
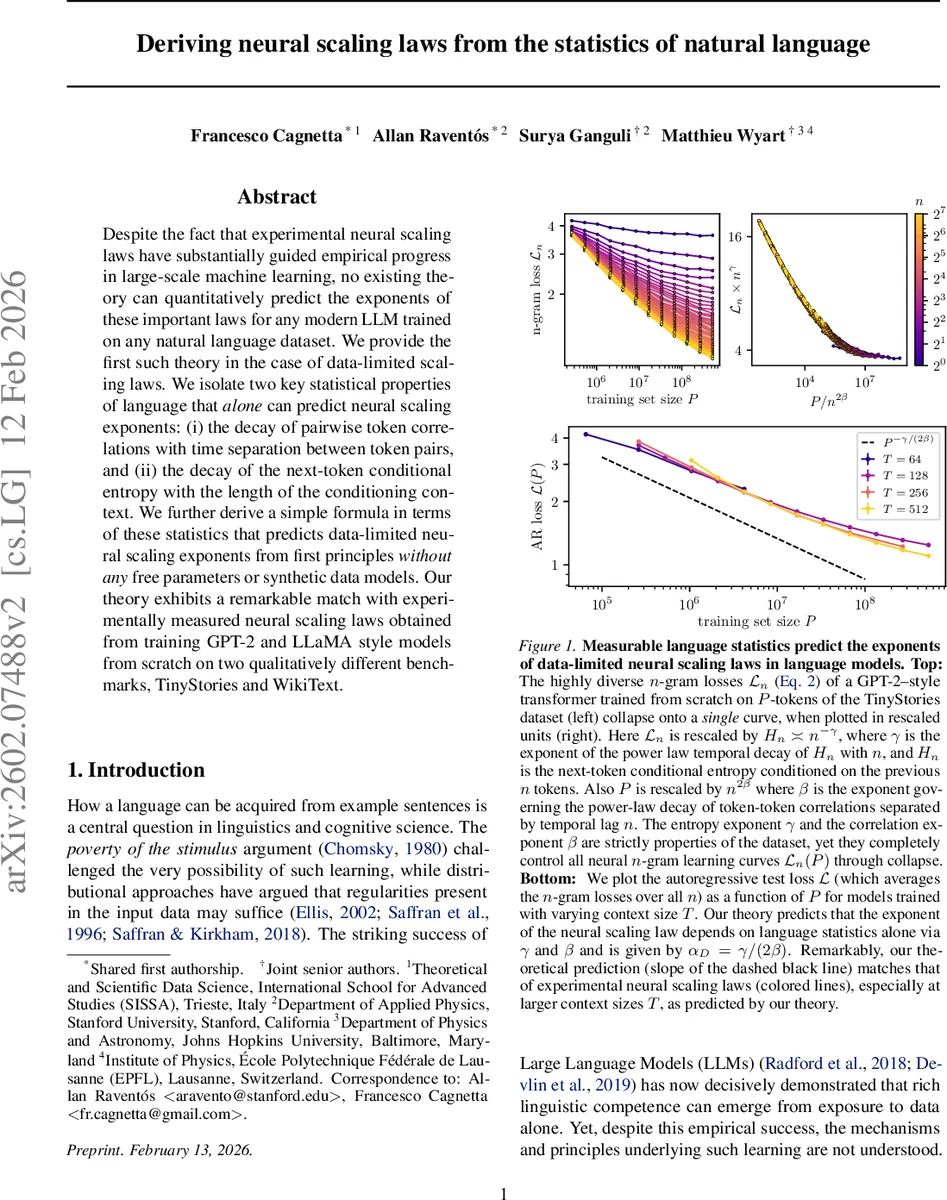
The key insight is that, for a given amount of training data P, a model can only reliably exploit dependencies up to a maximal effective context length n∗(P). This “prediction horizon” is determined by a signal‑to‑noise argument on the top singular value of the token‑token covariance matrix C(n). When the signal ∥C(n)∥_op falls to the order of the sampling noise O(P⁻¹/²), the model can no longer detect correlations at lag n. Assuming a power‑law decay ∥C(n)∥_op ∝ n⁻ᵝ, solving ∥C(n)∥_op ≈ P⁻¹/² yields n∗(P) ≈ P^{1/(2β)}.
The total autoregressive loss L_AR(P) can be decomposed into two contributions: the irreducible entropy H_{n∗(P)} associated with the best possible predictor that uses only the n∗‑step context, and an error term accounting for sub‑optimal use of tokens within that horizon. If the sub‑optimal error decays sufficiently fast (an assumption justified empirically for deep transformer models), the dominant excess loss over the infinite‑context entropy H_∞ scales as
L_AR(P) – H_∞ ≈ P^{‑γ/(2β)}.
Thus the data‑limited scaling exponent α_D is simply
α_D = γ / (2β).
Crucially, this formula contains no free parameters and requires only empirical estimates of β and γ from the raw text.
To validate the theory, the authors measure β and γ on two very different corpora: TinyStories (synthetically generated short stories) and WikiText‑103 (real Wikipedia articles). Using a straightforward estimator for β based on the top singular value of the lag‑n covariance matrix, and a neural‑network‑based estimator for conditional entropy H_n, they obtain β≈0.33–0.38 and γ≈0.66–0.72, leading to predicted α_D≈1.0 for both datasets.
They then train GPT‑2‑style and LLaMA‑style transformers from scratch on each corpus, varying the context window T (64, 128, 256, 512 tokens) and the total number of training tokens P across several orders of magnitude (10⁴–10⁸). Empirical learning curves for the autoregressive loss closely follow the predicted power law, especially for larger T where the assumption T≫n∗(P) holds. The measured exponents from the log‑log plots match the theoretical α_D within statistical error.
A further striking confirmation comes from the collapse of individual n‑gram learning curves. The theory predicts that each n‑gram loss L_n(P) should obey the scaling form
L_n(P) = n^{‑γ} ℓ(P / n^{2β}),
where ℓ(·) is a universal master curve. When the authors re‑plot the empirical L_n(P) using the rescaled axes (P / n^{2β} on the horizontal axis and L_n / n^{‑γ} on the vertical), all curves for different n collapse onto a single function, confirming the predicted universality.
The paper discusses limitations: the assumption that intra‑horizon error E_n(P) decays rapidly may fail for shallow networks, kernel methods, or n‑gram models, which suffer from the curse of dimensionality. The reduction of the full covariance structure to a single singular value may overlook richer linguistic dependencies. Moreover, the theory addresses only the data‑limited regime; model‑size‑limited or compute‑limited regimes likely involve different exponents.
Nevertheless, the work provides a concrete, testable link between language statistics and LLM scaling, offering practical guidance for data collection and model design. By measuring β and γ on a new corpus, practitioners can forecast the returns of additional data without costly experiments. Future directions include extending the framework to account for model‑size scaling, incorporating hierarchical linguistic structures (syntax trees, semantic graphs), and testing the approach on multimodal datasets. Overall, the paper delivers a compelling, parameter‑free theory that demystifies why and how the amount of data governs the performance of modern language models.
Comments & Academic Discussion
Loading comments...
Leave a Comment