Three factor delay learning rules for spiking neural networks
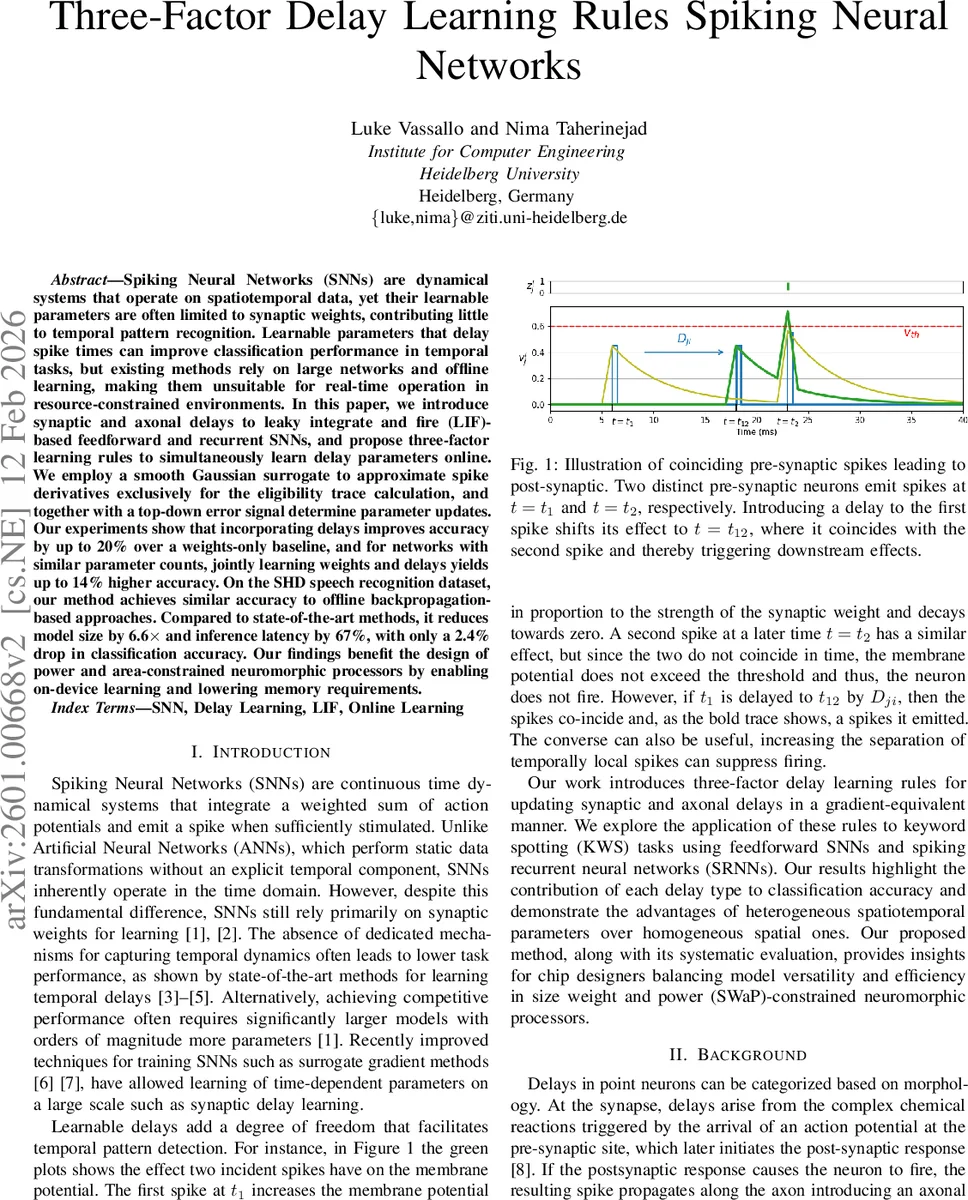
Spiking Neural Networks (SNNs) are dynamical systems that operate on spatiotemporal data, yet their learnable parameters are often limited to synaptic weights, contributing little to temporal pattern recognition. Learnable parameters that delay spike times can improve classification performance in temporal tasks, but existing methods rely on large networks and offline learning, making them unsuitable for real-time operation in resource-constrained environments. In this paper, we introduce synaptic and axonal delays to leaky integrate and fire (LIF)-based feedforward and recurrent SNNs, and propose three-factor learning rules to simultaneously learn delay parameters online. We employ a smooth Gaussian surrogate to approximate spike derivatives exclusively for the eligibility trace calculation, and together with a top-down error signal determine parameter updates. Our experiments show that incorporating delays improves accuracy by up to 20% over a weights-only baseline, and for networks with similar parameter counts, jointly learning weights and delays yields up to 14% higher accuracy. On the SHD speech recognition dataset, our method achieves similar accuracy to offline backpropagation-based approaches. Compared to state-of-the-art methods, it reduces model size by 6.6x and inference latency by 67%, with only a 2.4% drop in classification accuracy. Our findings benefit the design of power and area-constrained neuromorphic processors by enabling on-device learning and lowering memory requirements.
💡 Research Summary
The paper tackles a fundamental limitation of spiking neural networks (SNNs): most existing training approaches only adjust synaptic weights, leaving the temporal dimension under‑exploited. To address this, the authors augment leaky‑integrate‑and‑fire (LIF) based feed‑forward and recurrent SNNs with two learnable delay parameters – synaptic delays (the time a spike is delayed before reaching a synapse) and axonal delays (the time a spike is delayed while traveling along an axon). Both types of delays are represented as integer timesteps bounded by a maximum delay Dmax.
The core contribution is a set of three‑factor online learning rules that enable simultaneous gradient‑equivalent learning of weights and delays without the need for back‑propagation through time (BPTT). The three factors are: (1) a top‑down error signal derived from the cross‑entropy loss at the read‑out layer, (2) an eligibility trace that captures the recent pre‑ and post‑synaptic activity, and (3) the derivative of the neuron’s output with respect to the delay parameter. The eligibility trace is computed recursively, mirroring the e‑prop framework, but the derivative with respect to delay is undefined for discrete spike times. The authors resolve this by approximating each spike with a smooth Gaussian kernel; this surrogate makes the spike train differentiable with respect to the delay, allowing the required gradient term to be calculated analytically.
The learning rule can be applied online: as each input sample arrives, the eligibility traces and error signals are updated, and the parameters are immediately adjusted. This eliminates the “update‑locking” of BPTT and reduces memory complexity from O(n · T) to O(n), where n is the number of neurons and T the sequence length. The Gaussian surrogate is non‑causal, which necessitates a ring buffer for implementation, but experiments show it yields more stable and faster convergence than causal alternatives such as exponential kernels.
Experiments are conducted on two spiking speech datasets: Spiking Heidelberg Digits (SHD) and Spiking Speech Commands (SSC). The authors evaluate three network sizes (large 128‑unit fully connected, 80 % sparse, and small 16‑unit) and compare against weight‑only baselines (32 and 64 hidden units) as well as a state‑of‑the‑art offline method (DCLS) that uses BPTT with learned temporal convolutions. Delays are added to input synapses for feed‑forward SNNs and also to recurrent connections for spiking recurrent neural networks (SRNNs). Axonal delays are applied to virtual input neurons and, in SRNNs, to both input and recurrent neurons.
Key findings include: (i) incorporating learnable delays improves classification accuracy by 12–20 % over weight‑only models; (ii) jointly learning weights and delays yields up to a 14 % accuracy gain compared to models with a similar number of parameters trained with BPTT; (iii) on the SHD benchmark, the proposed online method matches the accuracy of offline BPTT‑based DCLS while using 6.6× fewer parameters and achieving a 67 % reduction in inference latency, with only a 2.4 % drop in accuracy. Sparse networks also benefit from delay learning, confirming that the approach is robust to weight pruning.
The paper discusses limitations: the Gaussian surrogate’s non‑causal nature introduces implementation overhead, and representing delays as integer timesteps limits temporal resolution. Moreover, the evaluation focuses on speech data; generalization to other time‑series domains remains to be demonstrated. Future work is suggested on causal surrogate kernels, hardware‑friendly quantization of delays, and extending the method to multimodal spiking data.
In summary, the authors present a biologically inspired, hardware‑compatible three‑factor learning scheme that endows SNNs with learnable temporal delays. By enabling online, low‑memory training, the approach paves the way for on‑device learning in power‑ and area‑constrained neuromorphic processors, offering a practical route to compact, low‑latency spiking models with competitive performance.
Comments & Academic Discussion
Loading comments...
Leave a Comment