Understanding Generalization in Diffusion Distillation via Probability Flow Distance
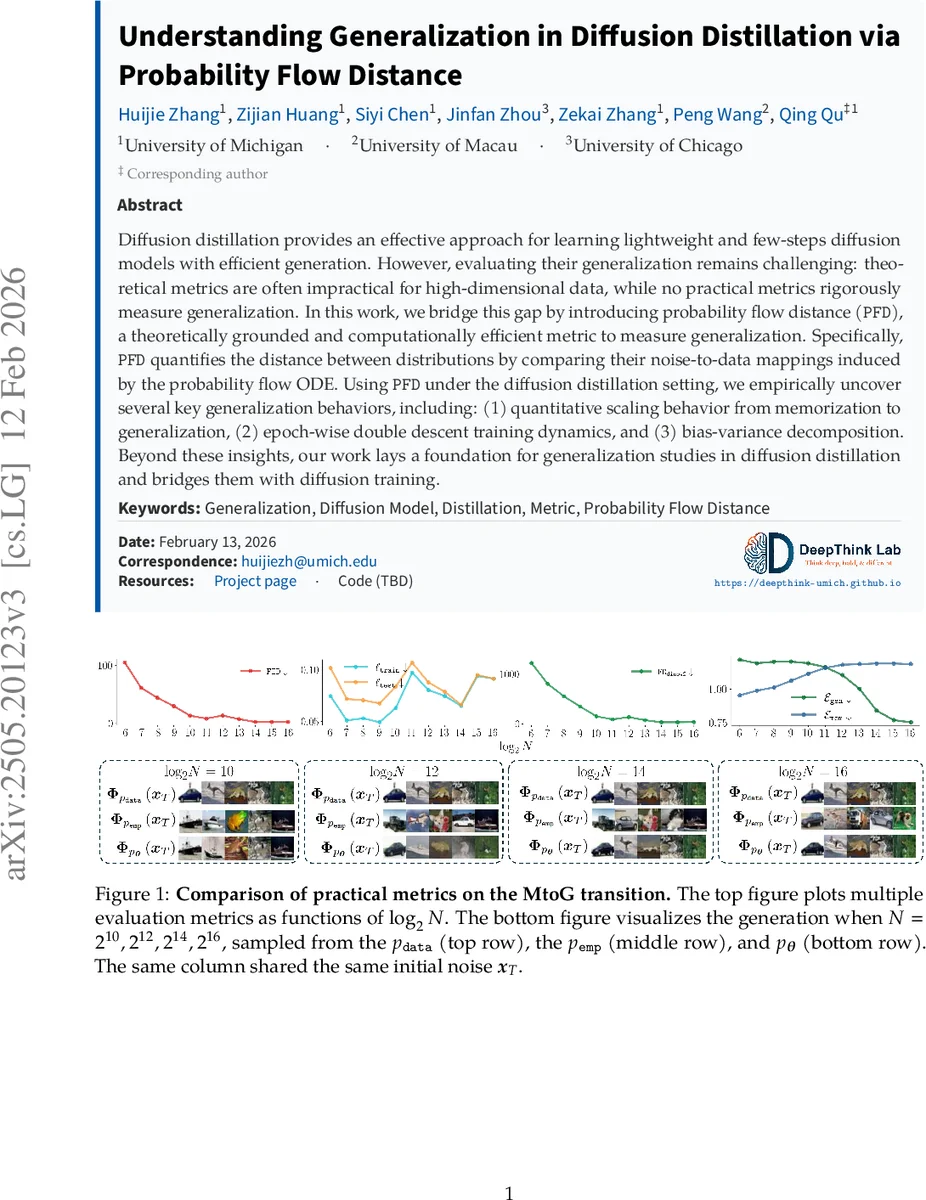
Diffusion distillation provides an effective approach for learning lightweight and few-steps diffusion models with efficient generation. However, evaluating their generalization remains challenging: theoretical metrics are often impractical for high-dimensional data, while no practical metrics rigorously measure generalization. In this work, we bridge this gap by introducing probability flow distance (\texttt{PFD}), a theoretically grounded and computationally efficient metric to measure generalization. Specifically, \texttt{PFD} quantifies the distance between distributions by comparing their noise-to-data mappings induced by the probability flow ODE. Using \texttt{PFD} under the diffusion distillation setting, we empirically uncover several key generalization behaviors, including: (1) quantitative scaling behavior from memorization to generalization, (2) epoch-wise double descent training dynamics, and (3) bias-variance decomposition. Beyond these insights, our work lays a foundation for generalization studies in diffusion distillation and bridges them with diffusion training.
💡 Research Summary
This paper addresses a critical gap in the evaluation of diffusion model distillation: the lack of a practical yet theoretically sound metric that can distinguish memorization from genuine generalization. Existing metrics such as FID or IS only assess sample quality and cannot tell whether a student model is simply reproducing training data. Classical distributional distances (KL, TV, Wasserstein) are either computationally prohibitive in high‑dimensional image spaces or require dense sampling, making them unsuitable for the distillation setting.
To solve this problem, the authors introduce Probability Flow Distance (PFD), a metric built on the probability flow ordinary differential equation (PF‑ODE) that underlies diffusion sampling. The PF‑ODE defines a deterministic mapping ϕₚ from a high‑dimensional Gaussian noise vector x_T to a clean data sample, given a target distribution p. For two distributions p and q, PFD measures the expected L₂ distance between the two mapped samples when the same noise x_T is fed through both mappings, optionally after passing through an image descriptor ψ (e.g., a pretrained vision encoder). Formally:
PFD(p,q)=E_{x_T∼N(0,T²I)}
Comments & Academic Discussion
Loading comments...
Leave a Comment