Latent Forcing: Reordering the Diffusion Trajectory for Pixel-Space Image Generation
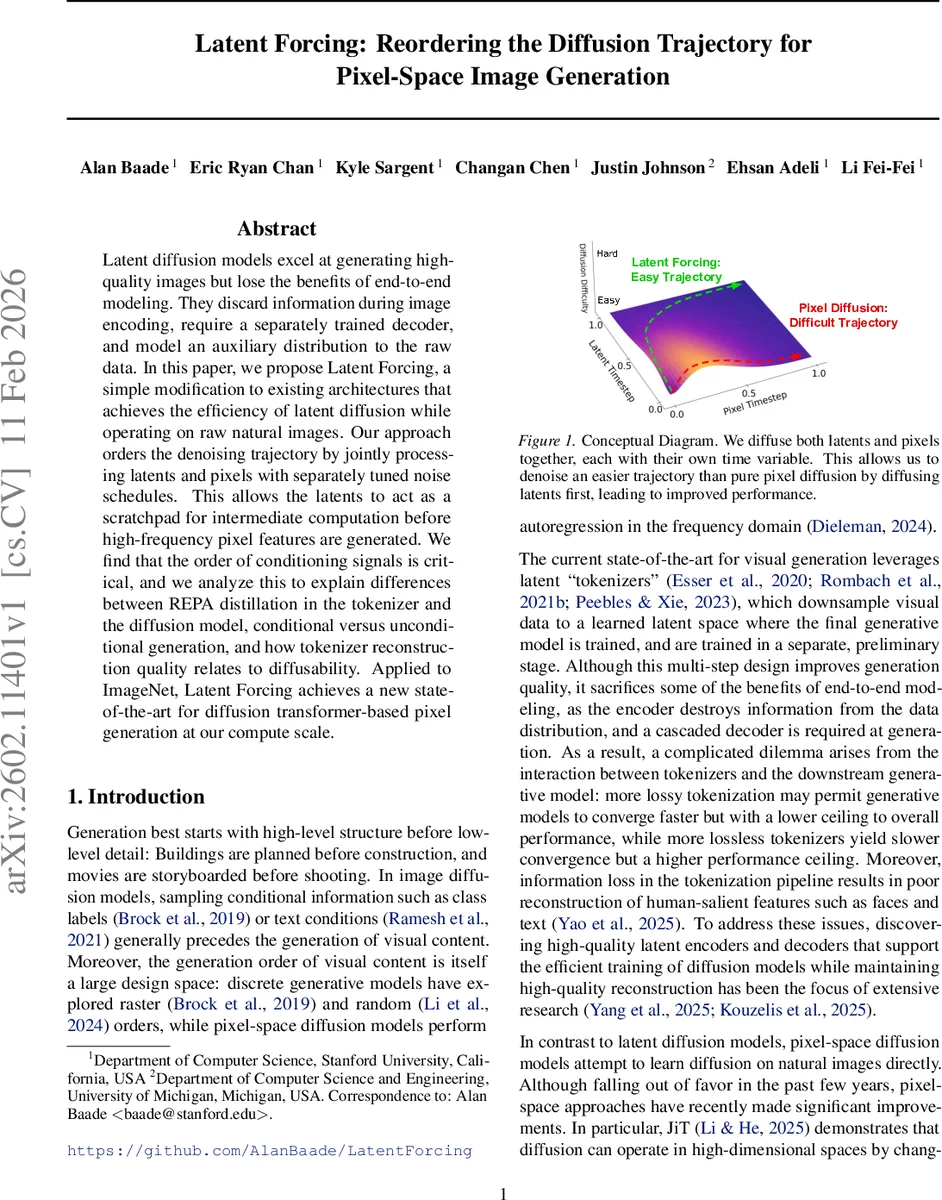
Latent diffusion models excel at generating high-quality images but lose the benefits of end-to-end modeling. They discard information during image encoding, require a separately trained decoder, and model an auxiliary distribution to the raw data. In this paper, we propose Latent Forcing, a simple modification to existing architectures that achieves the efficiency of latent diffusion while operating on raw natural images. Our approach orders the denoising trajectory by jointly processing latents and pixels with separately tuned noise schedules. This allows the latents to act as a scratchpad for intermediate computation before high-frequency pixel features are generated. We find that the order of conditioning signals is critical, and we analyze this to explain differences between REPA distillation in the tokenizer and the diffusion model, conditional versus unconditional generation, and how tokenizer reconstruction quality relates to diffusability. Applied to ImageNet, Latent Forcing achieves a new state-of-the-art for diffusion transformer-based pixel generation at our compute scale.
💡 Research Summary
The paper introduces Latent Forcing, a novel modification to diffusion models that combines the efficiency of latent diffusion with the end‑to‑end nature of pixel‑space diffusion. Traditional latent diffusion models first compress images into a learned latent space using a tokenizer (often a VQ‑GAN or VAE) and then train a diffusion model on these latents. While this reduces computational cost, it introduces information loss because the encoder discards details and a separate decoder must reconstruct the image. Pure pixel‑space diffusion avoids these losses but suffers from high dimensionality, slower convergence, and higher memory requirements.
Latent Forcing addresses these issues by jointly diffusing two modalities—latent representations and raw pixels—each with its own time variable. The latent stream (e.g., DINOv2 or Data2Vec2 embeddings) is assigned a fast‑decaying noise schedule, so its signal‑to‑noise ratio (SNR) becomes high early in the generation process. Consequently, the model quickly recovers a coarse, semantic scaffold that serves as a “scratchpad”. The pixel stream follows a slower schedule, allowing high‑frequency details to be added conditioned on the already‑recovered latents. This ordering is formalized through an information‑theoretic metric O(t) that tracks the SNR of each modality across a global time axis; non‑overlapping schedules factor the joint distribution as P(Y)·P(X|Y), where Y is the deterministic latent and X is the final image.
The authors adopt a diffusion transformer (DiT) architecture with minimal changes: latent and pixel tokens are concatenated at the same spatial positions, AdaLN receives two time embeddings, and the final transformer layers can be split into separate experts for each modality. Training minimizes a weighted sum of L2 losses for both streams, while inference proceeds by stepping a global time variable and mapping it to modality‑specific times via monotonic functions (e.g., the α‑shift schedule). At the end of generation, the latent tokens are discarded, leaving only the denoised pixel output.
Experiments on ImageNet‑1k (256×256) demonstrate that Latent Forcing outperforms the state‑of‑the‑art pixel‑space DiT models both in conditional and unconditional settings, achieving a notable reduction in Fréchet Inception Distance (FID). Ablation studies reveal that the ordering of conditioning signals is crucial: when latents are presented later or with a similar schedule to pixels, performance degrades, confirming the hypothesis that early semantic scaffolding eases the learning of high‑frequency details. The paper also analyzes the relationship between latent reconstruction quality (PSNR/SSIM) and “diffusability” (SNR‑based metric), showing that higher‑quality latents lead to more efficient pixel denoising.
Beyond empirical gains, the work provides a theoretical perspective on generation order in diffusion models, linking it to exponential differences in learnability and to the trade‑off between compression and generation speed observed in tokenizers. By treating the latent as a conditioning signal rather than a compressed representation, the method eliminates the need for a separate decoder and retains full image fidelity.
In conclusion, Latent Forcing offers a simple yet powerful framework that reorders the diffusion trajectory, leverages self‑supervised latent features as an early‑stage guide, and delivers state‑of‑the‑art results without sacrificing end‑to‑end training. The approach opens avenues for extending multi‑modal diffusion (e.g., text, audio) with independent schedules, and for further exploring how information‑theoretic ordering can improve generative modeling across domains.
Comments & Academic Discussion
Loading comments...
Leave a Comment