Finding the Cracks: Improving LLMs Reasoning with Paraphrastic Probing and Consistency Verification
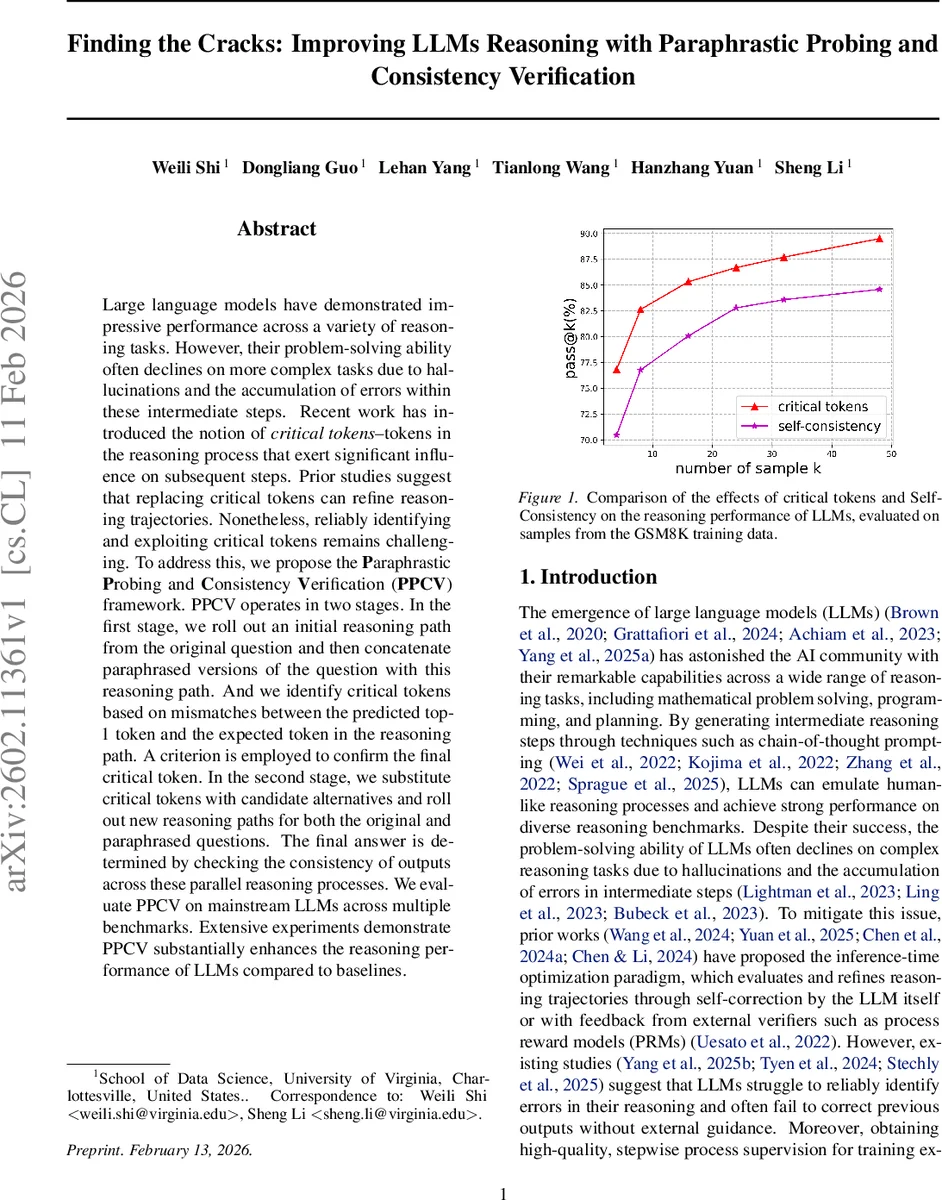
Large language models have demonstrated impressive performance across a variety of reasoning tasks. However, their problem-solving ability often declines on more complex tasks due to hallucinations and the accumulation of errors within these intermediate steps. Recent work has introduced the notion of critical tokens–tokens in the reasoning process that exert significant influence on subsequent steps. Prior studies suggest that replacing critical tokens can refine reasoning trajectories. Nonetheless, reliably identifying and exploiting critical tokens remains challenging. To address this, we propose the Paraphrastic Probing and Consistency Verification~(PPCV) framework. PPCV operates in two stages. In the first stage, we roll out an initial reasoning path from the original question and then concatenate paraphrased versions of the question with this reasoning path. And we identify critical tokens based on mismatches between the predicted top-1 token and the expected token in the reasoning path. A criterion is employed to confirm the final critical token. In the second stage, we substitute critical tokens with candidate alternatives and roll out new reasoning paths for both the original and paraphrased questions. The final answer is determined by checking the consistency of outputs across these parallel reasoning processes. We evaluate PPCV on mainstream LLMs across multiple benchmarks. Extensive experiments demonstrate PPCV substantially enhances the reasoning performance of LLMs compared to baselines.
💡 Research Summary
The paper addresses a persistent problem in large language model (LLM) reasoning: intermediate steps often contain hallucinations or subtle errors that cascade, leading to incorrect final answers, especially on complex tasks. While recent work has identified “critical tokens” – specific tokens whose presence dramatically influences downstream reasoning – reliably locating and exploiting these tokens remains difficult.
To solve this, the authors propose the Paraphrastic Probing and Consistency Verification (PPCV) framework, a two‑stage inference‑time optimization method.
Stage 1 – Paraphrastic Probing. An initial chain‑of‑thought (CoT) reasoning trace is generated for the original question. The question is then paraphrased in multiple ways and each paraphrase is concatenated with the original reasoning trace, forming a set of synthetic inputs. These inputs are fed back into the LLM, and token‑level logits are examined. Positions where the model’s top‑1 predicted token diverges from the token that actually appeared in the original trace are flagged as “potential pivotal points.” The authors apply two empirical criteria: (i) the probability gap Δ between the expected token and the top‑1 token must exceed a preset threshold, and (ii) subsequent tokens must continue to show low correctness scores. Tokens satisfying both criteria are declared critical. This process requires only the LLM’s own logits, avoiding external supervision.
Stage 2 – Consistency Verification. For each identified critical token, the top‑K candidate replacements (including the original token) are sampled. New CoT traces are generated for both the original question and all paraphrased versions, each time inserting one of the candidate tokens at the critical position. The key observation is that correct reasoning paths tend to be robust to paraphrastic perturbations. Therefore, the final answer is selected by measuring “paraphrase consistency”: the answer that appears most consistently across the original and paraphrased runs is chosen. Instead of simple majority voting, the authors weight consistency by semantic similarity between the paraphrase and the original question, yielding a similarity‑weighted consistency score.
The framework is evaluated on mainstream LLMs (Llama‑3.1‑8B‑Instruct, GPT‑3.5‑Turbo, Claude‑2) across a suite of benchmarks: GSM8K, MathQA, CommonsenseQA, LogicalDeduction, among others. Metrics include Pass@k, raw accuracy, and average token count. PPCV consistently outperforms strong baselines such as Self‑Consistency (which samples multiple CoT traces and votes) and recent self‑correction methods. Gains are especially pronounced on multi‑step problems where error propagation is severe; PPCV reduces the error cascade by 30‑40 % relative to Self‑Consistency. Ablation studies show that both paraphrastic probing and the consistency‑based selection contribute significantly, and that modest values of K (5–10) balance performance with computational cost.
Strengths.
- Self‑contained critical token detection – relies only on the model’s own logits, eliminating the need for external error detectors or labeled data.
- Robustness through paraphrase consistency – leverages the empirically observed stability of correct reasoning under surface‑form changes, providing a principled answer‑selection mechanism.
- Broad applicability – demonstrated across diverse model families and reasoning domains, indicating generality.
- Efficiency – compared to exhaustive search for critical tokens, the probing step is linear in the number of paraphrases, and the second stage reuses the same LLM without extra external modules.
Weaknesses and Limitations.
- The quality of paraphrase generation heavily influences token detection; low‑quality paraphrases can mask critical tokens or introduce spurious divergences.
- The method assumes access to token‑level logits, which may not be available for closed‑API models, limiting practical deployment.
- Critical token identification is token‑centric; complex logical errors that span multiple tokens or require structural changes may remain undetected.
- Hyper‑parameters (Δ threshold, K, similarity weighting) show dataset sensitivity, suggesting a need for automated tuning.
Future Directions. The authors suggest extending the probing to automatically optimize paraphrase diversity, integrating graph‑based context to capture multi‑token critical regions, and developing Bayesian confidence estimates that could replace explicit probability gaps. Additionally, adapting the framework to work with API‑only models via logit approximation or soft‑prompt tuning would broaden its impact.
In summary, PPCV offers a novel, inference‑time technique that identifies fragile points in an LLM’s reasoning via paraphrastic sensitivity, repairs them by exploring alternative tokens, and selects the most stable answer through a consistency check. The empirical results demonstrate that this approach yields measurable improvements over existing sampling‑based and self‑correction strategies, marking a meaningful step toward more reliable and trustworthy LLM reasoning.
Comments & Academic Discussion
Loading comments...
Leave a Comment