Bi-Level Prompt Optimization for Multimodal LLM-as-a-Judge
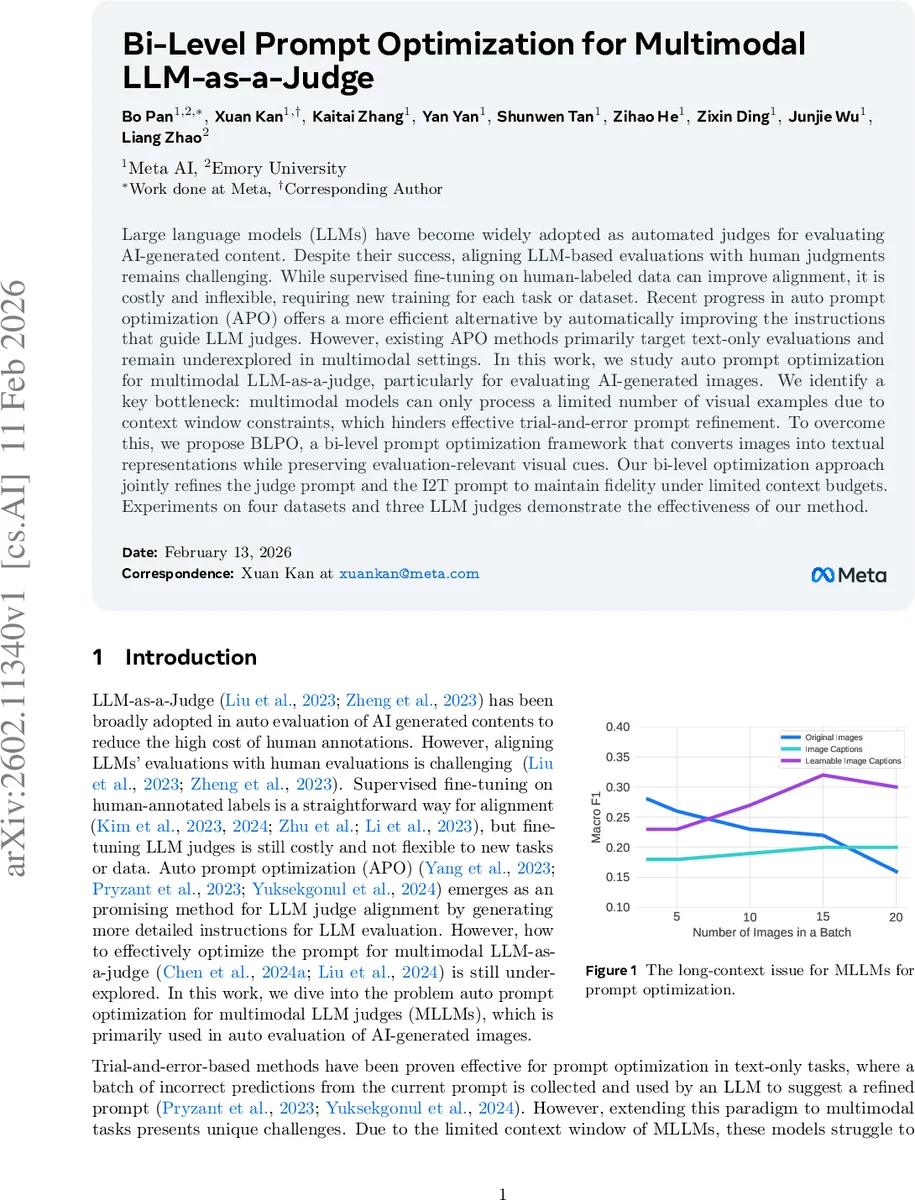
Large language models (LLMs) have become widely adopted as automated judges for evaluating AI-generated content. Despite their success, aligning LLM-based evaluations with human judgments remains challenging. While supervised fine-tuning on human-labeled data can improve alignment, it is costly and inflexible, requiring new training for each task or dataset. Recent progress in auto prompt optimization (APO) offers a more efficient alternative by automatically improving the instructions that guide LLM judges. However, existing APO methods primarily target text-only evaluations and remain underexplored in multimodal settings. In this work, we study auto prompt optimization for multimodal LLM-as-a-judge, particularly for evaluating AI-generated images. We identify a key bottleneck: multimodal models can only process a limited number of visual examples due to context window constraints, which hinders effective trial-and-error prompt refinement. To overcome this, we propose BLPO, a bi-level prompt optimization framework that converts images into textual representations while preserving evaluation-relevant visual cues. Our bi-level optimization approach jointly refines the judge prompt and the I2T prompt to maintain fidelity under limited context budgets. Experiments on four datasets and three LLM judges demonstrate the effectiveness of our method.
💡 Research Summary
This paper tackles the problem of automatically improving the prompts used by multimodal large language models (MLLMs) that act as judges for AI‑generated images. While LLM‑as‑a‑Judge has become a popular way to replace costly human annotations, aligning the model’s scores with human judgments remains difficult. Supervised fine‑tuning on human‑labeled data can help but is expensive and inflexible, requiring a new training run for each task or dataset. Recent work on automatic prompt optimization (APO) shows that the instructions given to a language model can be refined automatically, but existing APO methods focus on text‑only settings and do not address the unique challenges of multimodal evaluation.
The authors identify a critical bottleneck: multimodal models consume a large number of visual tokens per image, so their context windows (typically a few thousand tokens) quickly fill up when many images are presented together. In a trial‑and‑error APO loop, a larger batch of erroneous examples is needed to generate a robust prompt update, but the limited context prevents processing more than five to ten images at once, severely restricting the effectiveness of the optimization.
To overcome this, the paper proposes BLPO (Bi‑Level Prompt Optimization). The core idea is to replace raw images with textual representations generated by an image‑to‑text (I2T) module, thereby compressing the visual information into a token‑efficient format. However, naïve captions lose task‑specific details that are crucial for judging image quality (e.g., fine‑grained style, texture, or safety cues). Therefore, BLPO jointly learns an I2T prompt q that instructs the captioning model to verbalize exactly those aspects that matter for the downstream evaluation, alongside a judge prompt p that guides the MLLM’s scoring behavior.
Formally, the outer‑level objective minimizes the expected loss of the judge with respect to p, while the inner‑level objective selects the I2T prompt q that maximizes the expected loss reduction achieved after the outer‑level update. The inner loop uses an LLM (GPT‑3) as a “prompt optimizer”: given a history of past q values and their scores (computed as the difference in loss before and after applying q), the optimizer proposes a new q. After a few inner iterations, the best q* is chosen and fed into the outer update, which asks the LLM‑as‑a‑Judge to suggest a refined judge prompt p′ based on the textualized error set.
Algorithm 1 details the bi‑level procedure: for each outer iteration, a minibatch of erroneous examples is sampled; the inner loop iteratively refines q; the outer loop then updates p using the selected q*. The method is evaluated on four benchmark datasets—AGIN (human‑rated image quality 1‑7), SeeTRUE (binary image‑text alignment), ImageReward (human preference scores 1‑5), and UnsafeBench (safe vs. unsafe)—and three MLLM backbones (Meta’s Llama‑4‑Scout‑17B, Llama‑4‑Maverick‑17B, and Qwen2.5‑VL‑32B). Baselines include OPRO, APO‑image (APO with raw images), and TextGrad. All experiments use GPT‑3 as the optimizer, temperature 0.0, up to five optimization rounds, and a maximum error set of ten examples.
Results (Figure 3) show that BLPO consistently outperforms all baselines across macro‑F1, accuracy, and safety metrics. The performance gap widens as the number of images per batch increases, confirming that the textual compression and learnable captioning effectively mitigate the context‑window limitation. Qualitative analysis reveals that the learned I2T prompts produce captions emphasizing fine‑grained visual cues (e.g., “vivid color gradients”, “sharp facial details”) that are directly useful for the judge’s scoring.
Key insights include: (1) context‑window constraints are the primary obstacle for APO in multimodal settings; (2) converting images to task‑aware textual descriptions enables larger error batches without exceeding token limits; (3) jointly optimizing the I2T and judge prompts yields a synergistic effect that surpasses sequential or independent tuning; (4) leveraging an LLM as a prompt generator avoids the need for additional trainable parameters while still providing strong adaptability.
The paper acknowledges limitations: the I2T module itself relies on a pre‑trained multimodal model, so the approach is not completely parameter‑free; the study focuses solely on image evaluation, leaving video or audio‑centric tasks for future work. Nonetheless, BLPO offers a practical, low‑cost pathway to align multimodal LLM judges with human preferences, reducing reliance on expensive human labeling and paving the way for more reliable automated evaluation pipelines for generative AI.
Comments & Academic Discussion
Loading comments...
Leave a Comment