The Magic Correlations: Understanding Knowledge Transfer from Pretraining to Supervised Fine-Tuning
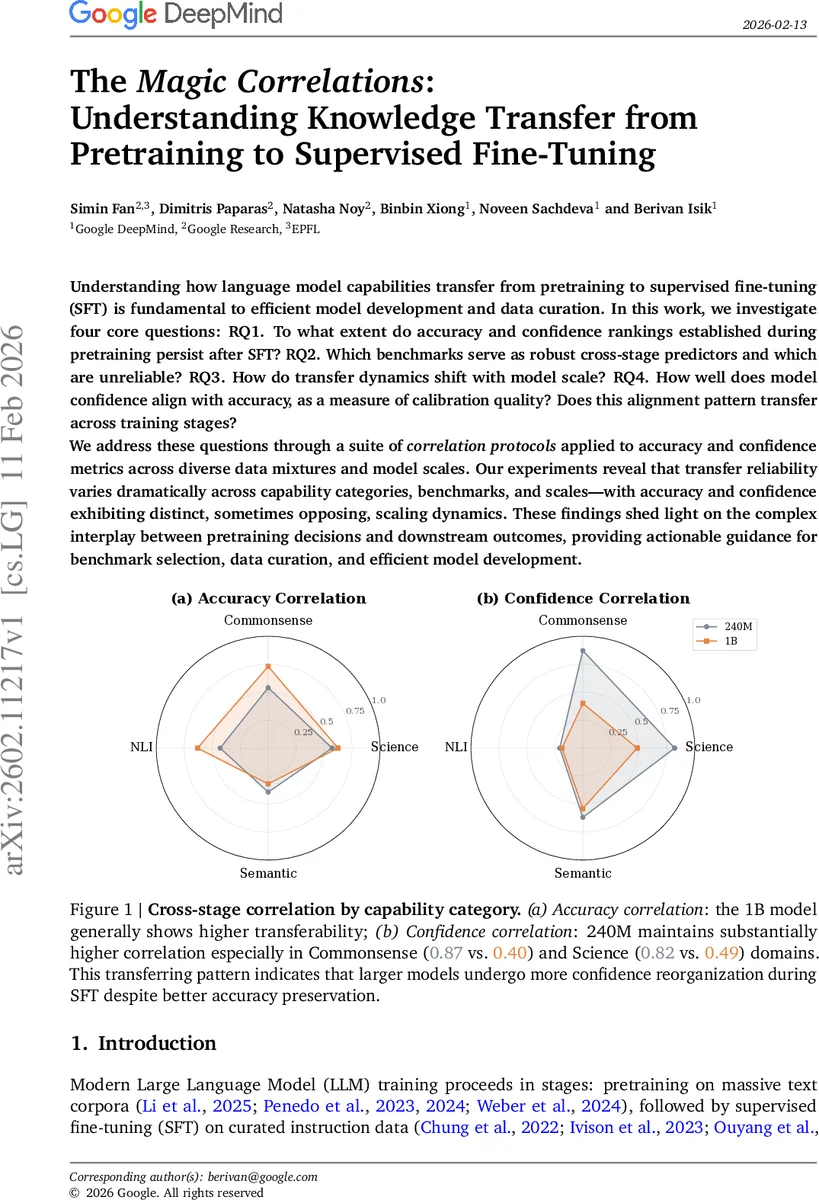
Understanding how language model capabilities transfer from pretraining to supervised fine-tuning (SFT) is fundamental to efficient model development and data curation. In this work, we investigate four core questions: RQ1. To what extent do accuracy and confidence rankings established during pretraining persist after SFT? RQ2. Which benchmarks serve as robust cross-stage predictors and which are unreliable? RQ3. How do transfer dynamics shift with model scale? RQ4. How well does model confidence align with accuracy, as a measure of calibration quality? Does this alignment pattern transfer across training stages? We address these questions through a suite of correlation protocols applied to accuracy and confidence metrics across diverse data mixtures and model scales. Our experiments reveal that transfer reliability varies dramatically across capability categories, benchmarks, and scales – with accuracy and confidence exhibiting distinct, sometimes opposing, scaling dynamics. These findings shed light on the complex interplay between pretraining decisions and downstream outcomes, providing actionable guidance for benchmark selection, data curation, and efficient model development.
💡 Research Summary
The paper investigates how capabilities learned during the pre‑training (PT) phase of large language models (LLMs) transfer to the supervised fine‑tuning (SFT) phase. The authors pose four research questions: (1) Do accuracy and confidence rankings established in PT persist after SFT? (2) Which benchmarks are reliable cross‑stage predictors and which are not? (3) How do transfer dynamics change with model scale? (4) How well does model confidence align with accuracy (calibration quality), and does this pattern transfer across stages?
To answer these questions, the authors train decoder‑only transformer models at two scales—240 M and 1 B parameters—on nine distinct data mixtures that vary the proportion of web, code, and curated knowledge sources. After pre‑training (12 B tokens for the 240 M model, 52 B tokens for the 1 B model), each checkpoint is fine‑tuned on the Tulu‑v2‑mix instruction dataset for five epochs.
The evaluation suite comprises 20 benchmarks grouped into four capability categories: Commonsense Reasoning, Scientific Reasoning, Natural Language Inference (NLI), and Semantic Understanding. For each benchmark the authors record two metrics: accuracy (fraction of correct answers) and confidence (average probability assigned to the chosen answer).
Five complementary correlation protocols are introduced:
- Cross‑Stage Accuracy Correlation (𝑟_stage_acc) – Pearson correlation of PT vs. SFT accuracy across the nine data mixtures for each benchmark.
- Cross‑Stage Confidence Correlation (𝑟_stage_conf) – Pearson correlation of PT vs. SFT confidence scores across mixtures.
- Intra‑Category Correlations – three measures (pre‑training coherence, SFT coherence, cross‑stage intra‑category coherence) that capture how improvements on one benchmark affect others within the same capability category, both before and after SFT.
- Performance‑Confidence Alignment (𝑟_align) – Pearson correlation between a model’s accuracy vector and its confidence vector across all benchmarks, serving as a proxy for overall calibration quality.
Key Findings
-
Inverse Scaling of Accuracy vs. Confidence Transfer – Larger models (1 B) show higher cross‑stage accuracy correlation (average 𝑟≈0.59) than smaller models (average 𝑟≈0.49), indicating that accuracy rankings are more stable at scale. Conversely, confidence correlation is stronger for the smaller model (average 𝑟≈0.66) than for the larger one (average 𝑟≈0.41). This suggests that as models grow, fine‑tuning reorganizes confidence patterns even while preserving accuracy.
-
Benchmark‑Dependent Transfer Reliability – Across the four categories, commonsense and scientific benchmarks maintain relatively high cross‑stage correlations, making them reliable early‑stage proxies. NLI and semantic benchmarks display weak or even negative correlations, marking them as poor predictors of downstream performance after SFT.
-
Scale‑Driven Shift in Intra‑Category Dynamics – At 240 M, many benchmark pairs within a category exhibit negative coherence during PT, implying competition: improving one task harms another. At 1 B, this competition largely disappears; most pairs become positively correlated after SFT, indicating that larger models develop shared representations that benefit multiple tasks simultaneously.
-
Calibration Quality Varies by Domain – Accuracy‑confidence alignment is strong for scientific reasoning (𝑟_align≈0.78) but modest for commonsense and semantic tasks (𝑟_align≈0.42). Importantly, SFT does not automatically improve alignment; over‑confidence on errors persists, especially in the latter domains, highlighting the need for explicit post‑hoc calibration (e.g., temperature scaling).
-
Data‑Mixture Trade‑offs – Using an education‑filtered web corpus (FineWeb‑Edu) improves scientific accuracy but degrades calibration alignment, demonstrating a trade‑off between task‑specific performance and overall confidence reliability.
Implications
The study provides actionable guidance for LLM development pipelines. First, benchmark selection for early‑stage model comparison should be category‑aware: commonsense and scientific benchmarks are dependable, while NLI/semantic benchmarks require caution. Second, scaling up models mitigates intra‑category competition, allowing more aggressive data‑mixture experimentation without sacrificing synergy. Third, confidence calibration does not naturally survive fine‑tuning; practitioners should incorporate dedicated calibration steps after SFT, especially for domains prone to over‑confidence. Fourth, data curation decisions must balance accuracy gains against calibration losses; strict filtering can boost specific capabilities but may harm the model’s uncertainty estimation.
Overall, the paper reveals that accuracy and confidence embody distinct transfer dynamics, that transfer reliability is highly benchmark‑ and scale‑dependent, and that calibration quality is not guaranteed to persist across training stages. These insights refine our understanding of how pre‑training choices influence downstream performance and inform more efficient, reliable LLM development strategies.
Comments & Academic Discussion
Loading comments...
Leave a Comment