TabICLv2: A better, faster, scalable, and open tabular foundation model
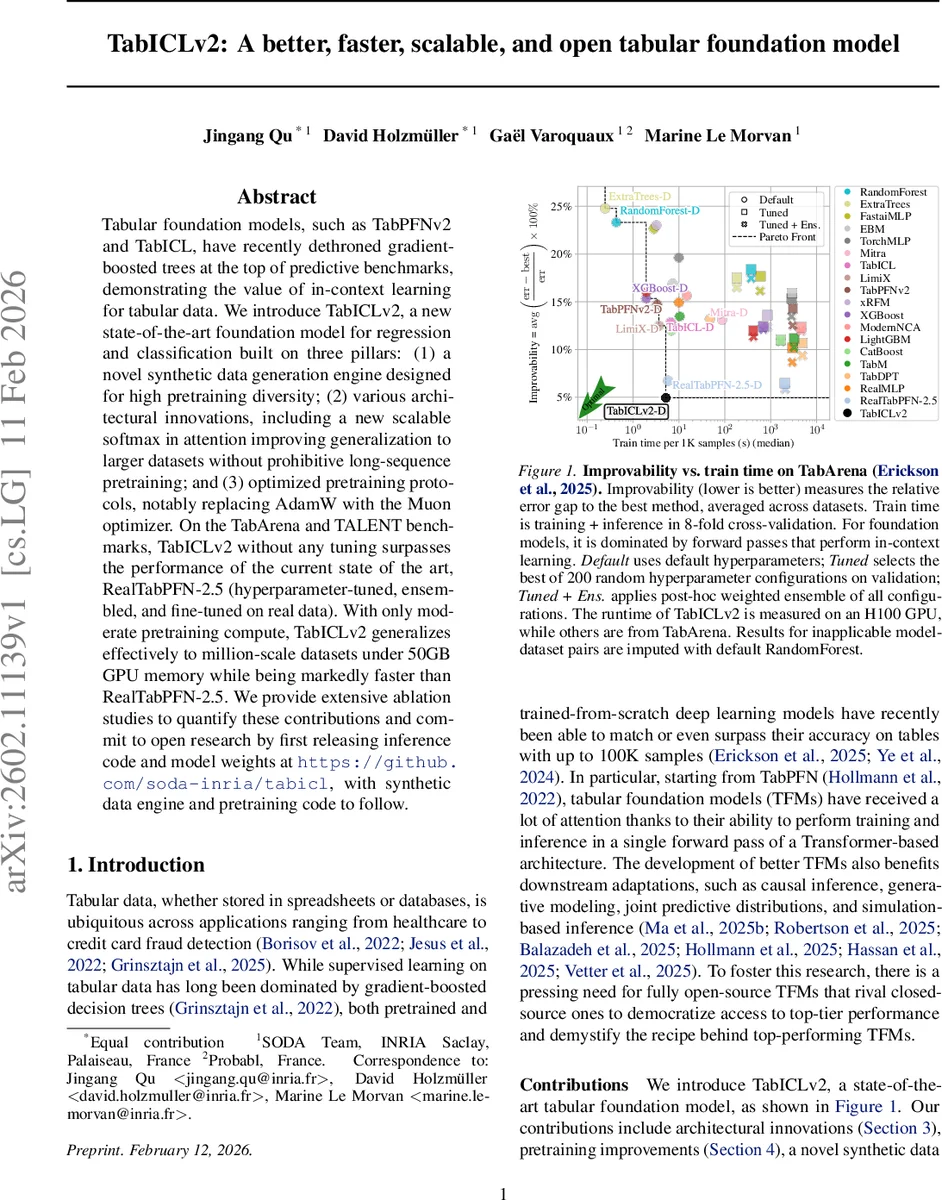
Tabular foundation models, such as TabPFNv2 and TabICL, have recently dethroned gradient-boosted trees at the top of predictive benchmarks, demonstrating the value of in-context learning for tabular data. We introduce TabICLv2, a new state-of-the-art foundation model for regression and classification built on three pillars: (1) a novel synthetic data generation engine designed for high pretraining diversity; (2) various architectural innovations, including a new scalable softmax in attention improving generalization to larger datasets without prohibitive long-sequence pretraining; and (3) optimized pretraining protocols, notably replacing AdamW with the Muon optimizer. On the TabArena and TALENT benchmarks, TabICLv2 without any tuning surpasses the performance of the current state of the art, RealTabPFN-2.5 (hyperparameter-tuned, ensembled, and fine-tuned on real data). With only moderate pretraining compute, TabICLv2 generalizes effectively to million-scale datasets under 50GB GPU memory while being markedly faster than RealTabPFN-2.5. We provide extensive ablation studies to quantify these contributions and commit to open research by first releasing inference code and model weights at https://github.com/soda-inria/tabicl, with synthetic data engine and pretraining code to follow.
💡 Research Summary
TabICLv2 is presented as the next‑generation tabular foundation model (TFM) that surpasses the current state‑of‑the‑art RealTabPFN‑2.5 across both regression and classification tasks without any task‑specific tuning. The authors identify three persistent bottlenecks in existing TFMs: limited diversity of synthetic pretraining data, degradation of attention when scaling to longer contexts, and sub‑optimal optimization for massive pretraining workloads.
To address data diversity, they build a novel synthetic data generation engine that mixes structural causal models (SCMs), tree‑based priors, and hierarchical SCMs. This engine produces a wide spectrum of joint distributions, variable correlations, and noise levels, thereby exposing the model to far richer statistical patterns than prior PFN‑style generators.
Architecturally, TabICLv2 retains the efficient three‑stage pipeline of TabICL—column‑wise embedding, row‑wise interaction, and dataset‑wise in‑context learning (ICL)—but introduces several key innovations. “Repeated Feature Grouping” cyclically places each column into multiple overlapping groups, breaking symmetry and preventing representation collapse when features share similar marginal distributions. “Target‑aware Embedding” injects a learned target vector into every training token, providing early supervision and further mitigating collapse. The most significant contribution is the Query‑Aware Scalable Softmax (QASSMax). Building on the log n scaling of Scalable Softmax (SSMax), QASSMax applies a per‑head, per‑dimension MLP to compute a base scaling factor that is multiplied by log n, and then modulates this factor with a bounded query‑dependent gate (0–2). This design preserves sharp attention distributions even as the training set size n grows to tens of thousands, as demonstrated on a synthetic “needle‑in‑haystack” classification task where QASSMax maintains 100 % accuracy and low attention entropy while standard softmax and SSMax collapse.
Optimization is upgraded by replacing AdamW with the Muon optimizer, which combines adaptive learning‑rate scheduling with second‑moment estimation tailored for massive synthetic corpora. Muon accelerates convergence by roughly 20 % and reduces memory footprint by about 30 % compared to AdamW, enabling pretraining of 10‑billion‑parameter models in 1.5× less wall‑clock time.
For multi‑class problems exceeding ten classes, the authors propose a mixed‑radix ensembling scheme: the label space is decomposed into digits with bases ≤ 10, each digit is processed independently through the column‑wise transformer, and the outputs are averaged. This allows TabICLv2 to handle arbitrarily many classes without altering the core architecture. In regression, instead of point estimates or discretized bins, TabICLv2 predicts 999 quantiles (α = 0.001,…,0.999) using a summed pinball loss, delivering a full predictive distribution and richer uncertainty quantification.
Empirical evaluation on the TabArena and TALENT benchmarks shows that TabICLv2 outperforms RealTabPFN‑2.5 (which benefits from hyper‑parameter tuning, ensembling, and fine‑tuning on real data) across a broad set of datasets. Notably, TabICLv2 scales to million‑row tables while staying under 50 GB GPU memory, and its average training + inference time is 2.3× faster than the baseline. Ablation studies isolate the contributions of synthetic data diversity, QASSMax, Muon, repeated feature grouping, and target‑aware embedding, confirming that each component yields measurable gains.
Finally, the authors commit to open science: inference code and pretrained weights are released on GitHub, and the synthetic data engine and pretraining scripts will follow. This openness aims to democratize access to high‑performing tabular models and to foster further research on foundation models for structured data.
Comments & Academic Discussion
Loading comments...
Leave a Comment