C-MOP: Integrating Momentum and Boundary-Aware Clustering for Enhanced Prompt Evolution
Automatic prompt optimization is a promising direction to boost the performance of Large Language Models (LLMs). However, existing methods often suffer from noisy and conflicting update signals. In this research, we propose C-MOP (Cluster-based Momentum Optimized Prompting), a framework that stabilizes optimization via Boundary-Aware Contrastive Sampling (BACS) and Momentum-Guided Semantic Clustering (MGSC). Specifically, BACS utilizes batch-level information to mine tripartite features–Hard Negatives, Anchors, and Boundary Pairs–to precisely characterize the typical representation and decision boundaries of positive and negative prompt samples. To resolve semantic conflicts, MGSC introduces a textual momentum mechanism with temporal decay that distills persistent consensus from fluctuating gradients across iterations. Extensive experiments demonstrate that C-MOP consistently outperforms SOTA baselines like PromptWizard and ProTeGi, yielding average gains of 1.58% and 3.35%. Notably, C-MOP enables a general LLM with 3B activated parameters to surpass a 70B domain-specific dense LLM, highlighting its effectiveness in driving precise prompt evolution. The code is available at https://github.com/huawei-noah/noah-research/tree/master/C-MOP.
💡 Research Summary
The paper introduces C‑MOP (Cluster‑based Momentum Optimized Prompting), a novel framework for automatic prompt optimization in large language models (LLMs). Existing gradient‑based prompt tuning methods suffer from noisy and conflicting update signals, especially when scaling batch size. C‑MOP addresses two core challenges: (1) incomplete characterization of decision boundaries and (2) instability caused by contradictory textual gradients.
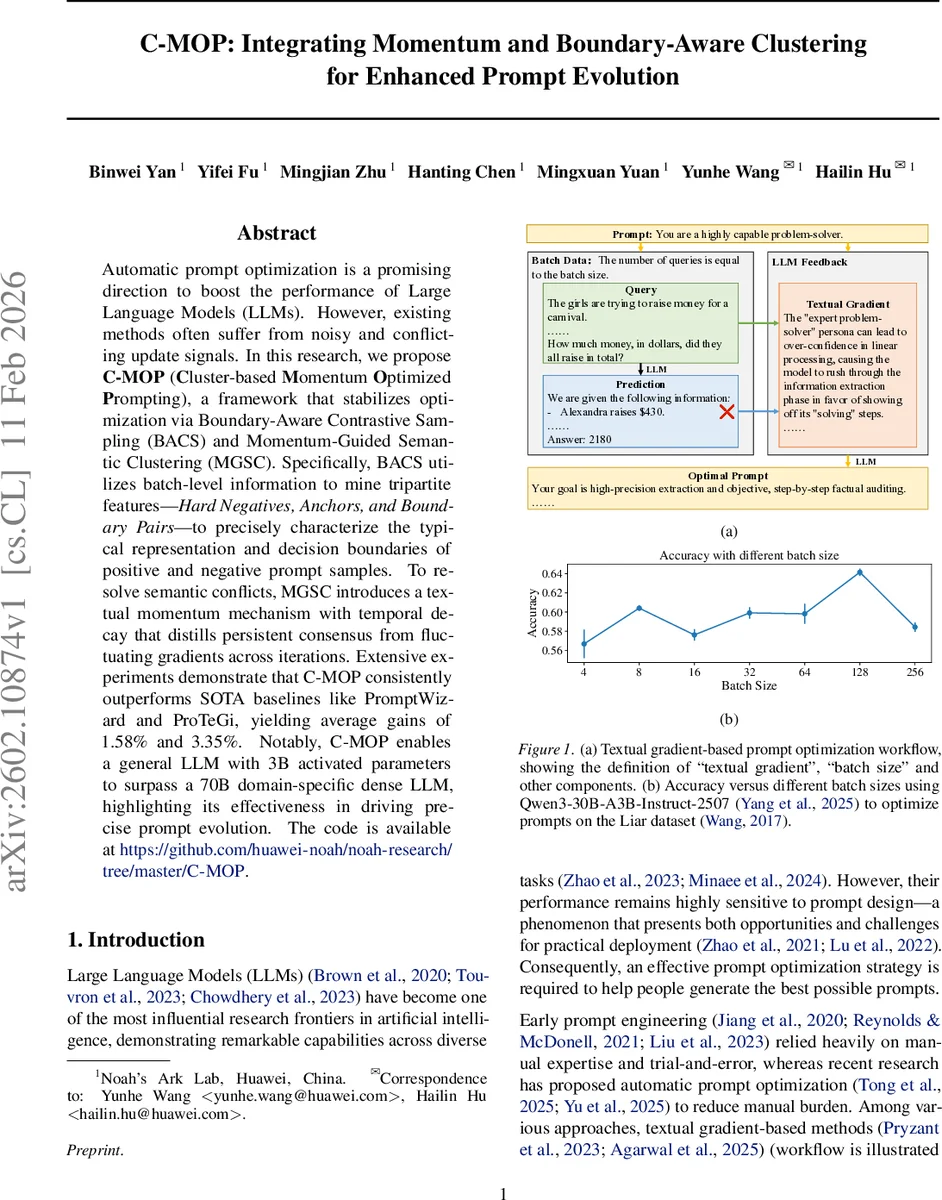
The first component, Boundary‑Aware Contrastive Sampling (BACS), replaces random sampling with a systematic extraction of three types of samples from each batch: Hard Negatives (mis‑predicted examples closest to the cluster centroid), Anchors (correct examples closest to the centroid), and Boundary Pairs (positive‑negative pairs with minimal semantic distance). The process begins by embedding every (query, answer, prediction) triple using a pretrained encoder, then clustering the batch with K‑means. Error rates per cluster determine a quota of samples to draw, ensuring that clusters with higher failure rates receive more attention. By focusing on these tripartite structures, BACS generates high‑contrast textual gradients that precisely locate the linguistic triggers causing classification flips.
The second component, Momentum‑Guided Semantic Clustering (MGSC), mitigates gradient conflict by maintaining a historical gradient pool with exponential decay γ. After each iteration, newly computed gradients are added to the pool, which is then re‑clustered to identify consistent directions across time. Within each gradient cluster, weighted averages produce representative gradients, and the top‑weighted gradients are selected for prompt updating. This temporal momentum smooths out batch‑specific noise and amplifies persistent optimization signals.
C‑MOP integrates these refined gradients into a candidate generation step using an optimizer model (F_opt). A set of candidate prompts is produced, and an Upper Confidence Bound (UCB) strategy balances exploration and exploitation to pick the most promising prompt for the next iteration. The full algorithm iterates through full‑batch prediction, BACS, MGSC, gradient‑guided evolution, and UCB selection.
Empirical evaluation on four benchmarks—BBH, GSM8K, CFinBench, and Liar—shows consistent improvements over state‑of‑the‑art baselines such as PromptWizard and ProTeGi, with average gains ranging from 1.58% to 3.35% in accuracy or task‑specific metrics. Notably, a 3‑billion‑parameter general LLM equipped with C‑MOP surpasses a 70‑billion‑parameter domain‑specific dense model, highlighting the method’s efficiency. Ablation studies confirm that both BACS and MGSC contribute substantially; removing either component leads to marked performance drops.
The authors discuss limitations, including sensitivity to hyper‑parameters (cluster count K, number of boundary pairs, decay factor γ) and the constraint of context length when scaling batch size. Future work aims to develop adaptive clustering and memory‑efficient sampling to further alleviate these issues.
In summary, C‑MOP provides a principled way to harness large‑batch textual gradients while controlling noise and conflict, delivering a stable and effective solution for prompt evolution in modern LLMs.
Comments & Academic Discussion
Loading comments...
Leave a Comment