Dual-End Consistency Model
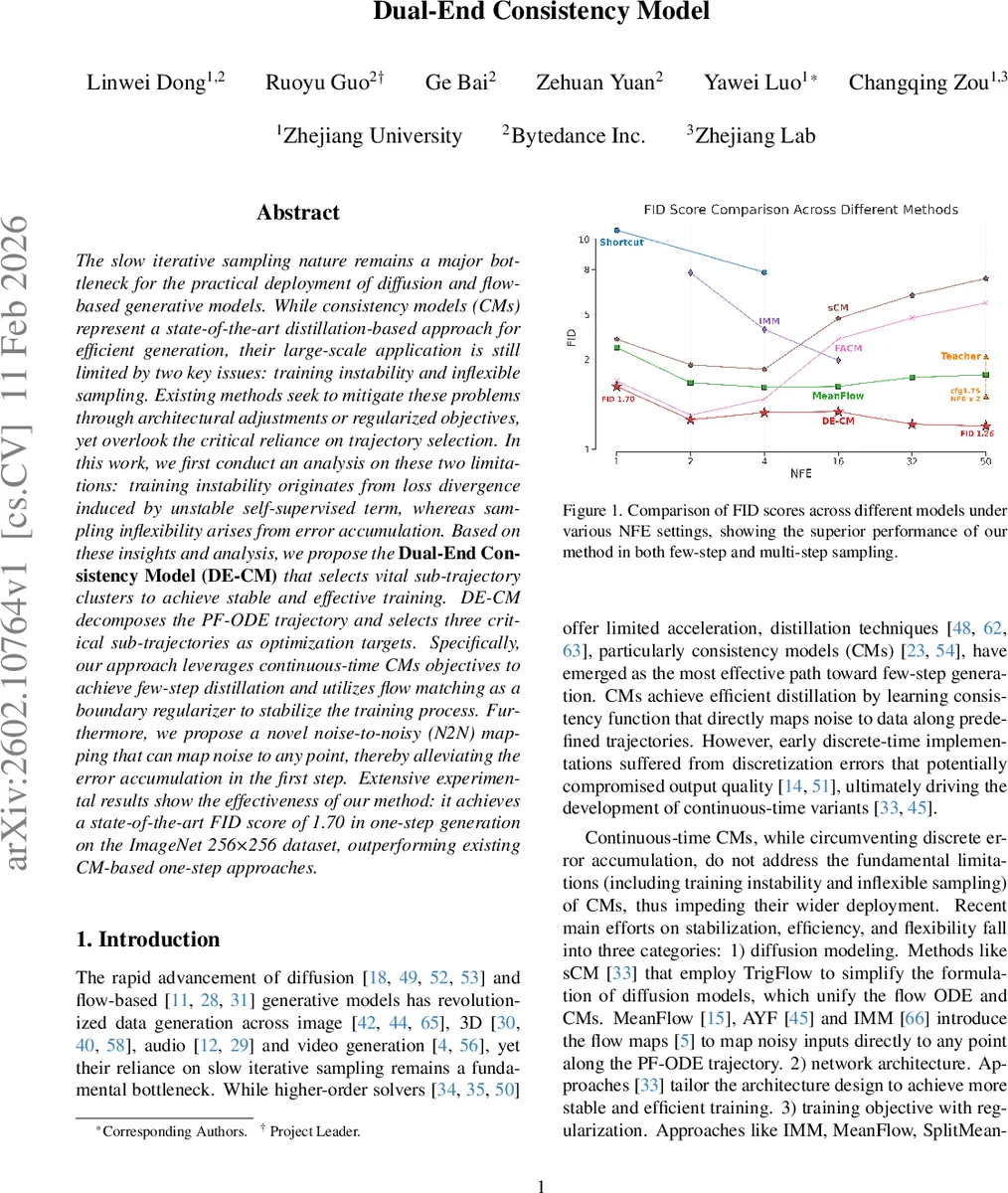
The slow iterative sampling nature remains a major bottleneck for the practical deployment of diffusion and flow-based generative models. While consistency models (CMs) represent a state-of-the-art distillation-based approach for efficient generation, their large-scale application is still limited by two key issues: training instability and inflexible sampling. Existing methods seek to mitigate these problems through architectural adjustments or regularized objectives, yet overlook the critical reliance on trajectory selection. In this work, we first conduct an analysis on these two limitations: training instability originates from loss divergence induced by unstable self-supervised term, whereas sampling inflexibility arises from error accumulation. Based on these insights and analysis, we propose the Dual-End Consistency Model (DE-CM) that selects vital sub-trajectory clusters to achieve stable and effective training. DE-CM decomposes the PF-ODE trajectory and selects three critical sub-trajectories as optimization targets. Specifically, our approach leverages continuous-time CMs objectives to achieve few-step distillation and utilizes flow matching as a boundary regularizer to stabilize the training process. Furthermore, we propose a novel noise-to-noisy (N2N) mapping that can map noise to any point, thereby alleviating the error accumulation in the first step. Extensive experimental results show the effectiveness of our method: it achieves a state-of-the-art FID score of 1.70 in one-step generation on the ImageNet 256x256 dataset, outperforming existing CM-based one-step approaches.
💡 Research Summary
The paper tackles two fundamental bottlenecks that have limited the practical deployment of diffusion and flow‑based generative models: (1) training instability and (2) inflexible sampling. While consistency models (CMs) have emerged as a state‑of‑the‑art distillation technique for accelerating generation, existing continuous‑time variants still suffer from loss divergence caused by an unstable self‑supervised term and from error accumulation during multi‑step sampling.
The authors first conduct a systematic analysis of these problems. By expanding the continuous‑time CM loss, they show that the objective decomposes into a fully supervised component that tries to match the instantaneous velocity v ϕ of the underlying probability‑flow ODE, and a self‑supervised consistency component that forces the model’s prediction at time t to equal its prediction at a nearby time t + Δt. When the model has not yet converged, these two terms diverge, leading to exploding gradients and training collapse. Moreover, because standard CMs only learn a mapping “any xₜ → x₁”, any early prediction error propagates directly to the final output, and the practice of injecting fresh noise at each step further amplifies errors, making multi‑step sampling brittle.
Motivated by this analysis, the paper proposes the Dual‑End Consistency Model (DE‑CM). The key insight is that the full PF‑ODE trajectory {(t, s) | t < s} need not be optimized uniformly. Instead, three critical sub‑trajectory clusters are identified and treated as separate learning targets:
-
Consistency Trajectory (t → 1) – the classic CM objective that maps any intermediate noisy state directly to the data point. Optimizing this sub‑trajectory enables few‑step (even one‑step) distillation.
-
Instantaneous Trajectory (t → t) – a boundary regularizer that enforces the model to reproduce the true instantaneous velocity of the PF‑ODE. This is achieved by a flow‑matching loss that uses Jacobian‑vector‑product (JVP) to compute the time derivative dFθ/dt on‑the‑fly, and by weighting the term with hyper‑parameters λ and γ. The boundary condition fθ(x₁, 1) = x₁ is thus explicitly respected, stabilizing training.
-
Noise‑to‑Noisy (N2N) Trajectory (0 → t) – a novel mapping that learns to transform pure Gaussian noise into any intermediate noisy state. By resetting the left endpoint of the trajectory to r → 0 while keeping the right endpoint at t, the authors derive a self‑supervised loss (Eq. 12‑15) that encourages the model to reuse the initial noise instead of drawing fresh noise at each step. This dramatically reduces error accumulation in multi‑step sampling.
Mathematically, the unified formulation is based on the generalized consistency function
fθ(xₜ, t, s) = xₜ + (s − t) Fθ(xₜ, t, s).
When s = 1, Eq. (10) yields the consistency loss L_cm; when s = t, the flow‑matching term provides a stable boundary; and when r → 0, s = t, Eq. (15) defines the N2N loss L_n2n. The total training objective is a weighted sum of these three losses, allowing the model to simultaneously learn accurate data mapping, correct instantaneous dynamics, and robust noise‑to‑noise transitions.
Experimental evaluation focuses on ImageNet at 256 × 256 resolution. DE‑CM achieves an FID of 1.70 with a single function evaluation (1‑NFE), surpassing prior one‑step CM baselines by a large margin. Moreover, the method retains competitive performance when more steps are allowed, demonstrating its flexibility. Ablation studies confirm that each of the three trajectory components contributes uniquely: removing the flow‑matching boundary leads to unstable training; omitting the N2N term causes error buildup in multi‑step runs; and discarding the consistency trajectory degrades few‑step quality. Gradient norm analyses (Fig. 4) illustrate how the flow‑matching regularizer tames the otherwise exploding gradients caused by the self‑supervised term.
In summary, DE‑CM reframes the training of consistency models from “optimizing the entire PF‑ODE trajectory” to “selecting and supervising vital sub‑trajectory clusters”. This strategic reduction eliminates loss divergence, enforces proper boundary conditions, and mitigates error accumulation, thereby delivering both stable training and state‑of‑the‑art few‑step generation. The approach opens a clear path toward deploying diffusion and flow‑based generators in real‑time applications such as high‑resolution image synthesis, video generation, and 3D content creation. Future work may explore automated sub‑trajectory selection, extension to conditional generation tasks, and integration with other acceleration techniques such as higher‑order ODE solvers.
Comments & Academic Discussion
Loading comments...
Leave a Comment