From Representational Complementarity to Dual Systems: Synergizing VLM and Vision-Only Backbones for End-to-End Driving
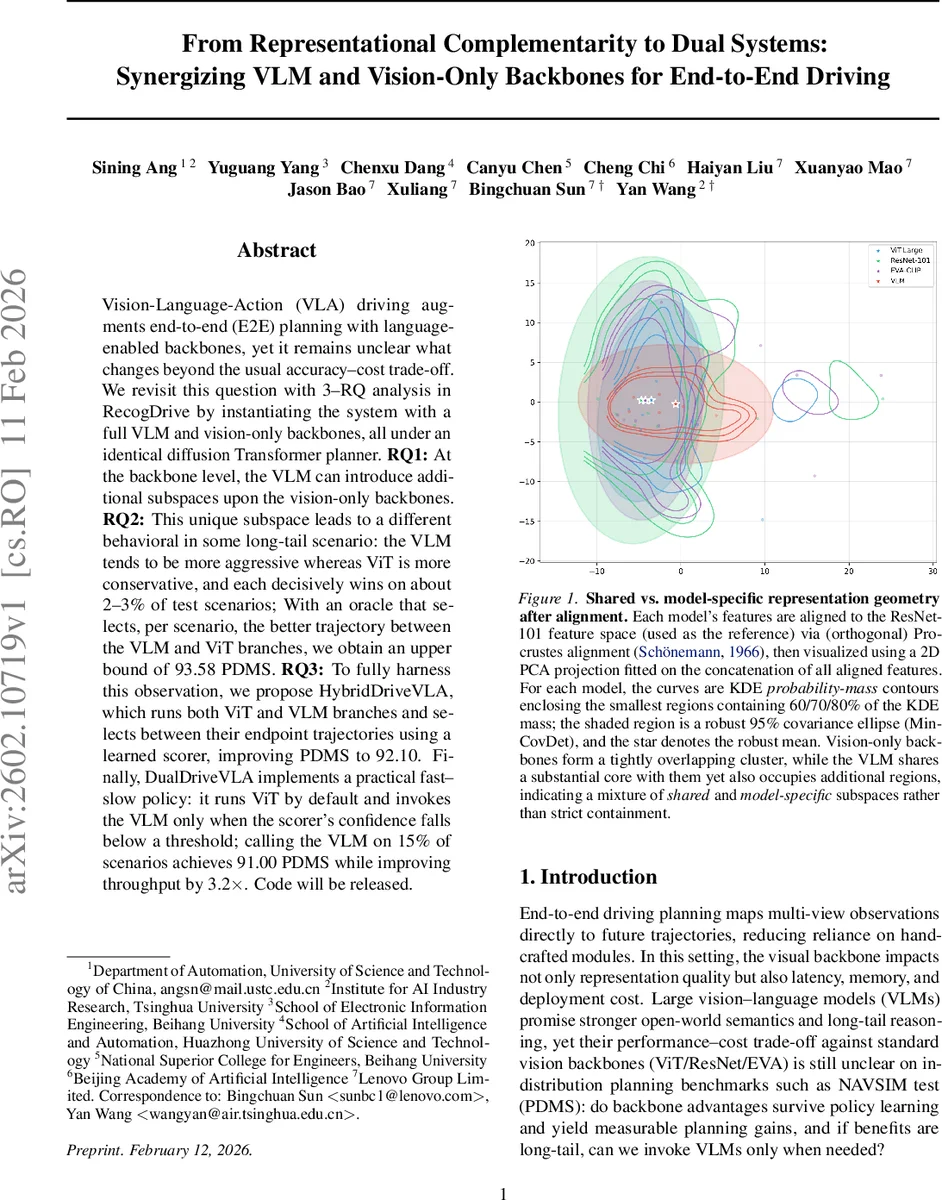
Vision-Language-Action (VLA) driving augments end-to-end (E2E) planning with language-enabled backbones, yet it remains unclear what changes beyond the usual accuracy–cost trade-off. We revisit this question with 3–RQ analysis in RecogDrive by instantiating the system with a full VLM and vision-only backbones, all under an identical diffusion Transformer planner. RQ1: At the backbone level, the VLM can introduce additional subspaces upon the vision-only backbones. RQ2: This unique subspace leads to a different behavioral in some long-tail scenario: the VLM tends to be more aggressive whereas ViT is more conservative, and each decisively wins on about 2–3% of test scenarios; With an oracle that selects, per scenario, the better trajectory between the VLM and ViT branches, we obtain an upper bound of 93.58 PDMS. RQ3: To fully harness this observation, we propose HybridDriveVLA, which runs both ViT and VLM branches and selects between their endpoint trajectories using a learned scorer, improving PDMS to 92.10. Finally, DualDriveVLA implements a practical fast–slow policy: it runs ViT by default and invokes the VLM only when the scorer’s confidence falls below a threshold; calling the VLM on 15% of scenarios achieves 91.00 PDMS while improving throughput by 3.2x. Code will be released.
💡 Research Summary
The paper investigates how large vision‑language models (VLMs) compare to conventional vision‑only backbones (ViT, ResNet, EVA‑CLIP) when both are plugged into the same end‑to‑end autonomous driving stack, RecogDrive, which uses a diffusion Transformer (DiT) planner. Three research questions (RQs) guide the study.
RQ1 examines representation similarity at two levels: the visual backbone and the DiT decision feature. Linear CKA shows low similarity (≈0.22) between VLM and vision‑only backbones, and Procrustes‑aligned PCA visualizations reveal that the VLM occupies both the shared core of vision‑only features and additional exclusive regions. After the planner, CKA rises to ≈0.54, and PCA‑whitened CCA indicates a substantial expansion of high‑correlation directions, suggesting the planner compresses heterogeneous visual cues into a more unified decision space. To probe functional interchangeability, the authors train a Shared‑Unique Sparse Autoencoder (SAE) that decomposes each representation into shared and branch‑specific latents. The SAE’s cross‑reconstruction R² gap (Δcross) shrinks after policy learning, confirming that a larger fraction of decision features become transferable across backbones.
RQ2 asks whether these representational differences translate into scenario‑specific performance. Empirical results on the NA‑VSIM benchmark show that the VLM‑based policy tends to be more aggressive (higher speed, earlier lane changes) while the ViT‑based policy is more conservative. Each side decisively outperforms the other on roughly 2–3 % of test scenarios (≈1.5 % when ΔPDMS > 50 %). Thus, the complementarity is confined to a long‑tail of challenging cases rather than a simple containment relationship.
RQ3 explores how to turn this complementarity into practical gains. Two systems are proposed. HybridDriveVLA runs both branches in parallel, generates interpolated trajectories, and selects the final output with a learned scorer. Without retraining the planner, HybridDriveVLA lifts PDMS from 90.80 to 92.10. DualDriveVLA adopts a fast‑slow scheme: the cheap ViT policy runs by default, and the expensive VLM is invoked only when the scorer’s confidence falls below a threshold. By calling the VLM on only ~15 % of scenarios, DualDriveVLA reaches 91.00 PDMS while improving throughput by 3.2×.
The authors also report a negative result: gating decisions based solely on global representation similarity (e.g., CKA) yields only marginal improvements, indicating that fine‑grained behavioral cues are needed for effective per‑scenario selection. Overall, the work provides a thorough analysis‑to‑mechanism pipeline: it quantifies representation isomorphism, demonstrates behavioral complementarity, and designs efficient dual‑system architectures that exploit the strengths of both VLMs and vision‑only backbones for autonomous driving.
Comments & Academic Discussion
Loading comments...
Leave a Comment