Gated Removal of Normalization in Transformers Enables Stable Training and Efficient Inference
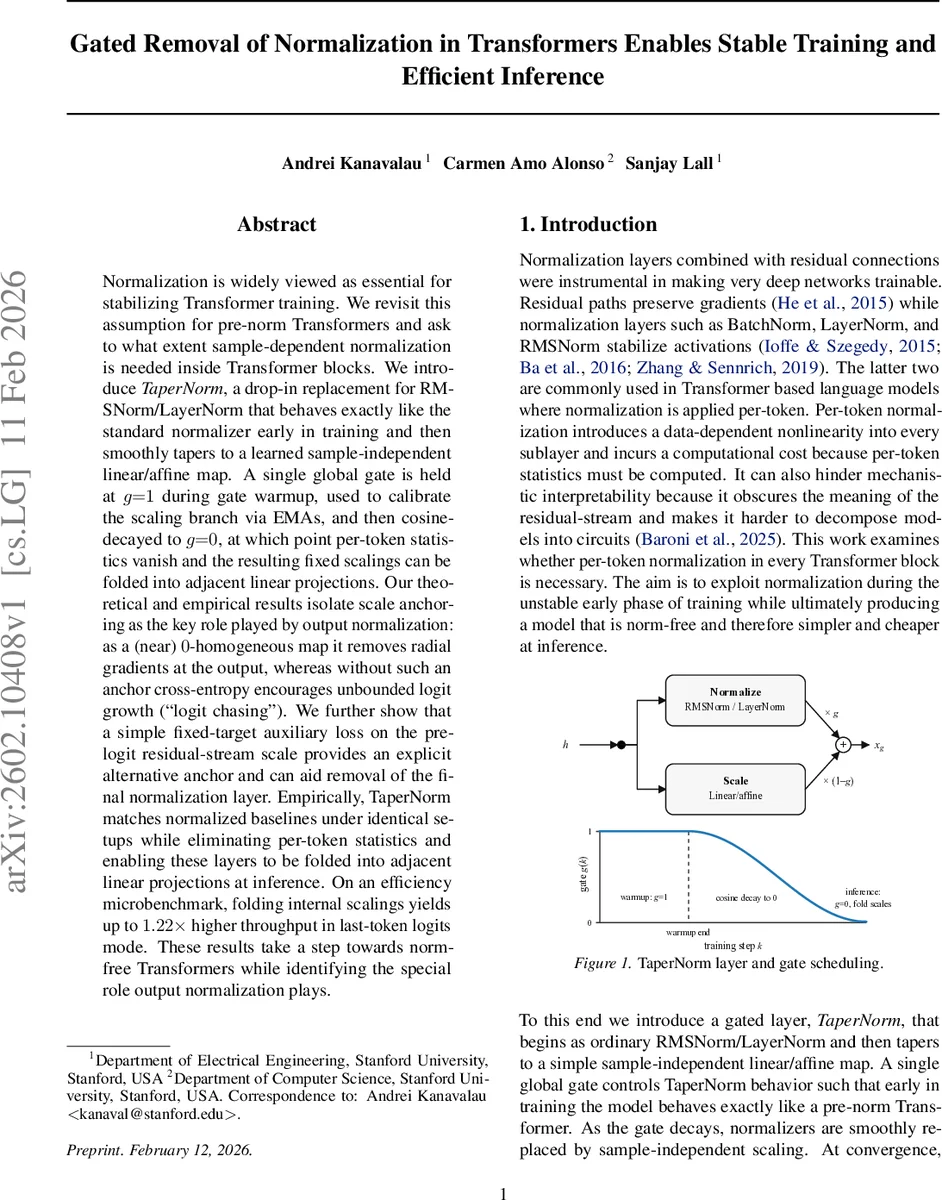
Normalization is widely viewed as essential for stabilizing Transformer training. We revisit this assumption for pre-norm Transformers and ask to what extent sample-dependent normalization is needed inside Transformer blocks. We introduce TaperNorm, a drop-in replacement for RMSNorm/LayerNorm that behaves exactly like the standard normalizer early in training and then smoothly tapers to a learned sample-independent linear/affine map. A single global gate is held at $g{=}1$ during gate warmup, used to calibrate the scaling branch via EMAs, and then cosine-decayed to $g{=}0$, at which point per-token statistics vanish and the resulting fixed scalings can be folded into adjacent linear projections. Our theoretical and empirical results isolate scale anchoring as the key role played by output normalization: as a (near) $0$-homogeneous map it removes radial gradients at the output, whereas without such an anchor cross-entropy encourages unbounded logit growth (``logit chasing’’). We further show that a simple fixed-target auxiliary loss on the pre-logit residual-stream scale provides an explicit alternative anchor and can aid removal of the final normalization layer. Empirically, TaperNorm matches normalized baselines under identical setups while eliminating per-token statistics and enabling these layers to be folded into adjacent linear projections at inference. On an efficiency microbenchmark, folding internal scalings yields up to $1.22\times$ higher throughput in last-token logits mode. These results take a step towards norm-free Transformers while identifying the special role output normalization plays.
💡 Research Summary
This paper revisits the long‑standing belief that per‑token normalization (LayerNorm or RMSNorm) is indispensable for training deep Transformers. Focusing on the pre‑norm architecture, the authors ask whether the sample‑dependent normalization is only needed during the early, unstable phase of training. To answer this, they introduce TaperNorm, a drop‑in replacement for RMSNorm/LayerNorm that smoothly transitions from a conventional token‑wise normalizer to a fixed, sample‑independent linear (or affine) map.
TaperNorm computes a convex combination of two branches: (1) the standard normalization branch, which scales the input token h by r(h)·Dγ (or Dβ for LayerNorm), and (2) a scaling branch that multiplies h by a learned scalar c and a per‑feature gain \tildeγ. A single global gate g∈
Comments & Academic Discussion
Loading comments...
Leave a Comment