Advancing Block Diffusion Language Models for Test-Time Scaling
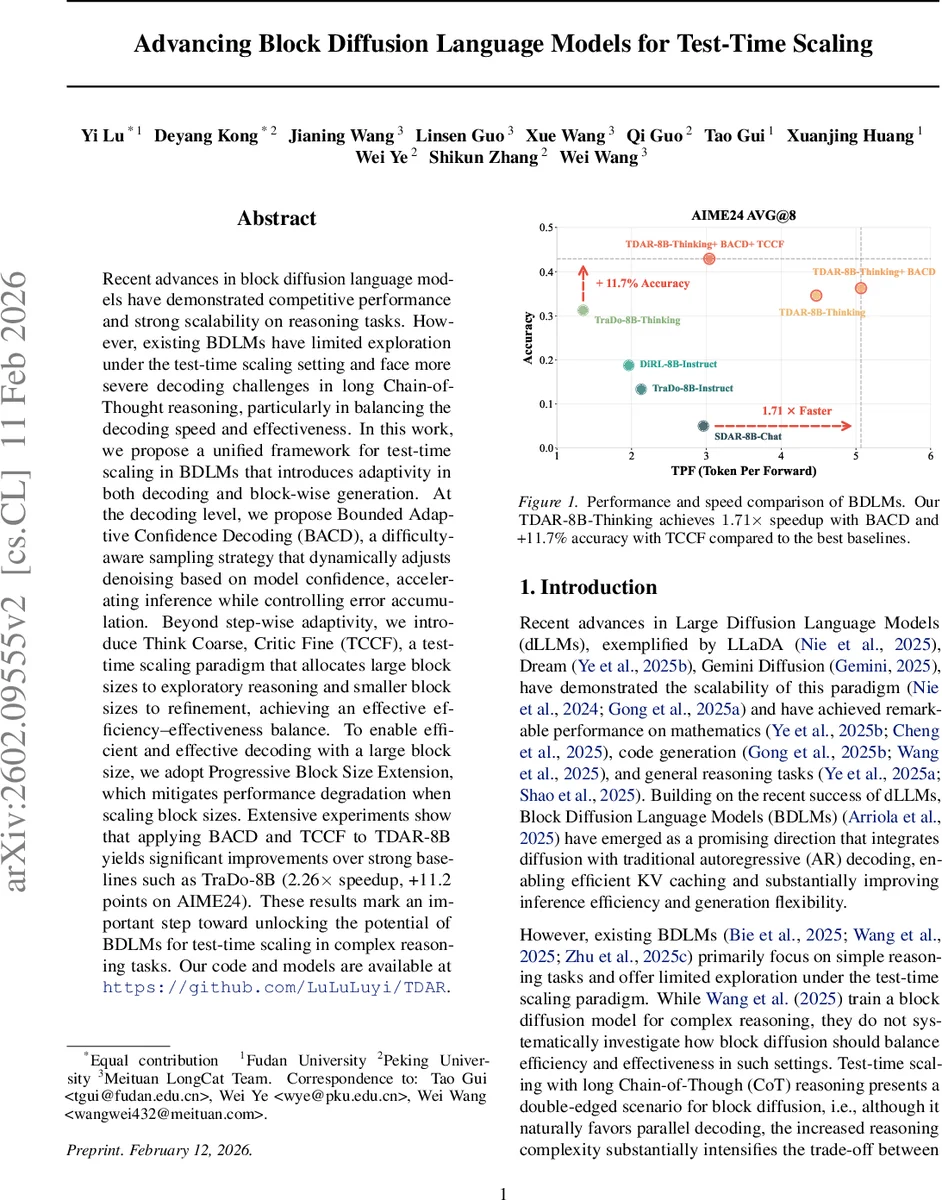
Recent advances in block diffusion language models have demonstrated competitive performance and strong scalability on reasoning tasks. However, existing BDLMs have limited exploration under the test-time scaling setting and face more severe decoding challenges in long Chain-of-Thought reasoning, particularly in balancing the decoding speed and effectiveness. In this work, we propose a unified framework for test-time scaling in BDLMs that introduces adaptivity in both decoding and block-wise generation. At the decoding level, we propose Bounded Adaptive Confidence Decoding (BACD), a difficulty-aware sampling strategy that dynamically adjusts denoising based on model confidence, accelerating inference while controlling error accumulation. Beyond step-wise adaptivity, we introduce Think Coarse, Critic Fine (TCCF), a test-time scaling paradigm that allocates large block sizes to exploratory reasoning and smaller block sizes to refinement, achieving an effective efficiency-effectiveness balance. To enable efficient and effective decoding with a large block size, we adopt Progressive Block Size Extension, which mitigates performance degradation when scaling block sizes. Extensive experiments show that applying BACD and TCCF to TDAR-8B yields significant improvements over strong baselines such as TraDo-8B (2.26x speedup, +11.2 points on AIME24). These results mark an important step toward unlocking the potential of BDLMs for test-time scaling in complex reasoning tasks.
💡 Research Summary
The paper tackles the efficiency‑effectiveness trade‑off that arises when applying Block Diffusion Language Models (BDLMs) to long Chain‑of‑Thought (CoT) reasoning under a test‑time scaling scenario. While BDLMs already combine diffusion‑based parallel token generation with the caching benefits of autoregressive models, they struggle when a single reasoning trajectory contains heterogeneous difficulty: large blocks speed up generation but can amplify errors, and small blocks improve accuracy but increase latency. To address this, the authors introduce a unified framework that adds adaptivity at two levels: decoding‑time and reasoning‑phase.
Bounded Adaptive Confidence Decoding (BACD) replaces static confidence thresholds or fixed‑token‑per‑step schemes with a dynamic threshold that is bounded between a lower and an upper limit. At each denoising step the model computes confidence scores for all masked tokens, averages the scores of tokens decoded so far, and clips this average to the predefined bounds, producing the current threshold τₜ. Tokens whose confidence exceeds τₜ are unmasked; if none qualify, the token with the highest confidence is forced open to guarantee convergence. This bounded adaptivity prevents the decoder from becoming overly conservative (slow) when confidence is high, or overly aggressive (error‑prone) when confidence is low, thereby stabilizing quality while allowing much larger blocks to be used. Experiments show that BACD alone yields 1.3‑3.4× speedups with modest (1‑5%) absolute accuracy gains across six benchmarks.
Think Coarse, Critic Fine (TCCF) exploits the observation that long CoT reasoning naturally splits into an exploratory phase and a refinement phase. In the “Think Coarse” stage the model generates an initial reasoning trajectory using a large block size (Bₜₕᵢₙₖ), maximizing parallelism. In the subsequent “Critic Fine” stage the same model re‑examines the trajectory with a smaller block size (B_critic < Bₜₕᵢₙₖ), allowing finer‑grained verification, correction, and summarization. No extra parameters are introduced; only the block size changes between stages.
Because large blocks can degrade performance if the model has never been trained with them, the authors also propose Progressive Block Size Extension. Starting from a small block (B = 4) they fine‑tune the model on long CoT data while gradually increasing the block size to 16, 32, and finally 64. This multi‑stage supervised fine‑tuning mitigates the “block‑size‑gap” problem and prepares the model for the coarse‑thinking stage.
The experimental setup builds an 8‑billion‑parameter BDLM (TDAR‑8B‑Thinking) from the Qwen‑3‑8B‑base checkpoint. After progressive block‑size training, the model is evaluated on six reasoning benchmarks covering mathematics (Math500, AIME‑24/25, AMC‑23), code generation (LiveCodeBench v5), and STEM (GPQA‑diamond). Baselines include state‑of‑the‑art open‑source BDLMs (Fast‑dLLM‑v2, SDAR‑8B‑Chat, DiRL‑8B‑Instruct, TraDo‑8B‑Instruct/Thinking) and an autoregressive counterpart.
Results (Table 1) demonstrate that TDAR‑8B‑Thinking already outperforms prior BDLMs in both speed and accuracy. Adding BACD further improves speed (up to 3.37× faster than standard autoregressive decoding) while raising accuracy by up to 5 points on individual tasks. Incorporating TCCF on top of BACD yields the best overall trade‑off: a modest speed reduction relative to BACD‑only (≈1.75×) but a notable accuracy boost, achieving 85.6 % on AIME‑24 (vs. 84.0 % for the strongest baseline) and the highest scores across all six benchmarks.
In summary, the paper makes three key contributions:
- BACD, a bounded, confidence‑driven adaptive decoding algorithm that stabilizes quality when using large blocks.
- TCCF, a two‑stage test‑time scaling paradigm that allocates coarse‑grained blocks for exploration and fine‑grained blocks for verification, effectively balancing speed and reasoning fidelity.
- Progressive Block Size Extension, a training recipe that equips BDLMs to handle large blocks without sacrificing performance.
These innovations collectively push BDLMs toward practical deployment in resource‑constrained settings where fast, accurate, long‑form reasoning is required, opening a path for future research on adaptive block‑size strategies and confidence‑aware diffusion decoding.
Comments & Academic Discussion
Loading comments...
Leave a Comment