City Navigation in the Wild: Exploring Emergent Navigation from Web-Scale Knowledge in MLLMs
Leveraging multimodal large language models (MLLMs) to develop embodied agents offers significant promise for addressing complex real-world tasks. However, current evaluation benchmarks remain predominantly language-centric or heavily reliant on simulated environments, rarely probing the nuanced, knowledge-intensive reasoning essential for practical, real-world scenarios. To bridge this critical gap, we introduce the task of Sparsely Grounded Visual Navigation, explicitly designed to evaluate the sequential decision-making abilities of MLLMs in challenging, knowledge-intensive real-world environment. We operationalize this task with CityNav, a comprehensive benchmark encompassing four diverse global cities, specifically constructed to assess raw MLLM-driven agents in city navigation. Agents are required to rely solely on visual inputs and internal multimodal reasoning to sequentially navigate 50+ decision points without additional environmental annotations or specialized architectural modifications. Crucially, agents must autonomously achieve localization through interpreting city-specific cues and recognizing landmarks, perform spatial reasoning, and strategically plan and execute routes to their destinations. Through extensive evaluations, we demonstrate that current state-of-the-art MLLMs, reasoning techniques (e.g., GEPA, chain-of-thought, reflection) and competitive baseline PReP significantly underperform in this challenging setting. To address this, we propose Verbalization of Path(VoP), which explicitly grounds the agent’s internal reasoning by probing city-scale cognitive maps (key landmarks and directions toward the destination) from the MLLM, substantially enhancing navigation success. Project Webpage: https://dwipddalal.github.io/AgentNav/
💡 Research Summary
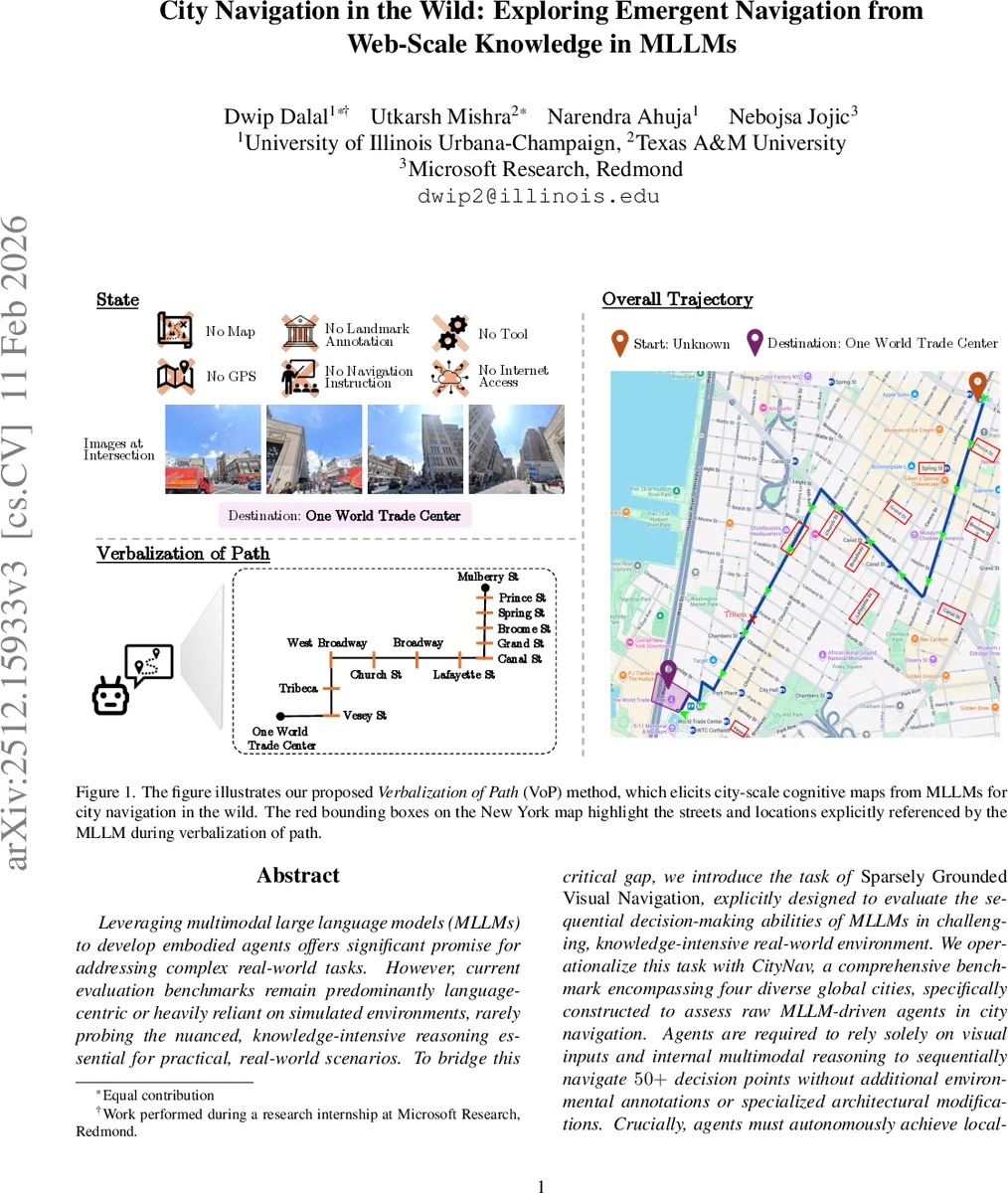
The paper tackles the problem of using multimodal large language models (MLLMs) as autonomous agents for real‑world city navigation without any external map, GPS, or landmark annotations. Existing embodied benchmarks focus on indoor or simulated environments and provide rich textual instructions, which do not test a model’s ability to draw on its internal world knowledge for sequential decision‑making. To fill this gap, the authors define a new task called Sparsely Grounded Visual Navigation and introduce CityNav, a benchmark built from Google Street View panoramas of four globally diverse cities: New York, São Paulo, Tokyo, and Vienna. Each route averages about 2 km and contains 50–80 intersections, with only raw intersection images supplied to the agent; no map or navigation instructions are given. The task is formalized as a partially observable Markov decision process (POMDP) where the state is the current intersection, actions are the outgoing street segments, and observations are the set of images for those segments.
Baseline experiments use state‑of‑the‑art MLLMs (e.g., GPT‑4V, LLaVA) together with popular reasoning augmentations such as Chain‑of‑Thought, GEPA, and Reflection, as well as a multimodal path‑prediction model called PReP. All baselines achieve very low success rates (under 10 %) and poor SPL scores, demonstrating that static reasoning techniques do not transfer well to an embodied, sequential setting where the model must constantly re‑localize from sparse visual cues.
To overcome this limitation, the authors propose Verbalization of Path (VoP), a two‑step prompting strategy. First, the model is asked to verbalize a high‑level “cognitive map” of the route—listing key landmarks and directional cues toward the destination. This forces the model to surface its internal city‑scale knowledge in natural language. Second, the agent uses this verbalized path as a memory to compare against the current visual observations and selects the next action that best aligns with the described direction. In effect, VoP turns latent world knowledge into an explicit guide that can be consulted at each decision point.
When VoP is applied, success rates rise to roughly 22 % (a 3–4× improvement over the best baseline), with the most pronounced gains in Tokyo where multilingual signage poses an additional challenge. Ablation studies show that removing the verbalization step collapses performance back to baseline levels, confirming that the extracted “path memory” is the critical component. Error analysis reveals remaining difficulties with abrupt viewpoint changes, visual noise, and complex intersections that still cause localization drift.
The paper also details extensive engineering work to clean the underlying Street View graph: dead‑ends are pruned, asymmetric links are fixed, and a temperature‑controlled edge‑selection policy with exponential revisit penalties is used to avoid loops during dataset generation.
In summary, the authors make four key contributions: (1) they introduce a novel, knowledge‑intensive navigation task and the CityNav benchmark; (2) they present VoP, a zero‑shot prompting technique that explicitly extracts and leverages a model’s internal city‑scale knowledge; (3) they demonstrate that current MLLMs possess enough structured world knowledge to navigate complex urban environments when guided appropriately; and (4) they show that reasoning methods effective for static tasks (e.g., chain‑of‑thought) do not directly benefit embodied navigation. The work opens a new evaluation paradigm for MLLM‑driven agents, highlights the importance of eliciting latent knowledge, and suggests future directions such as integrating more sophisticated memory architectures, external map APIs, and real‑robot deployments.
Comments & Academic Discussion
Loading comments...
Leave a Comment