Accelerating Streaming Video Large Language Models via Hierarchical Token Compression
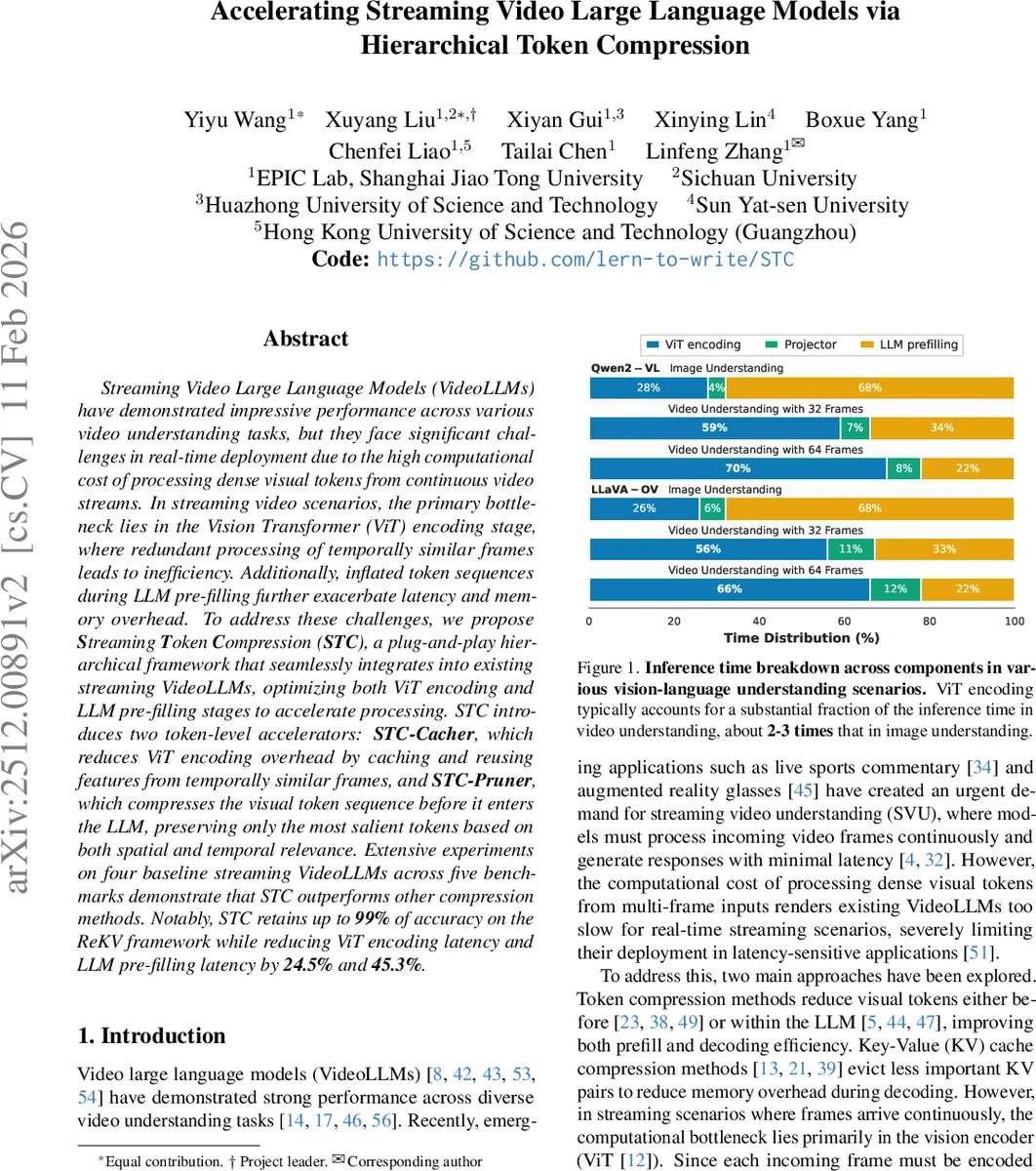
Streaming Video Large Language Models (VideoLLMs) have demonstrated impressive performance across various video understanding tasks, but they face significant challenges in real-time deployment due to the high computational cost of processing dense visual tokens from continuous video streams. In streaming video scenarios, the primary bottleneck lies in the Vision Transformer (ViT) encoding stage, where redundant processing of temporally similar frames leads to inefficiency. Additionally, inflated token sequences during LLM pre-filling further exacerbate latency and memory overhead. To address these challenges, we propose \textbf{S}treaming \textbf{T}oken \textbf{C}ompression (\textbf{STC}), a plug-and-play hierarchical framework that seamlessly integrates into existing streaming VideoLLMs, optimizing both ViT encoding and LLM pre-filling stages to accelerate processing. STC introduces two token-level accelerators: \textbf{STC-Cacher}, which reduces ViT encoding overhead by caching and reusing features from temporally similar frames, and \textbf{STC-Pruner}, which compresses the visual token sequence before it enters the LLM, preserving only the most salient tokens based on both spatial and temporal relevance. Extensive experiments on four baseline streaming VideoLLMs across five benchmarks demonstrate that STC outperforms other compression methods. Notably, STC retains up to \textbf{99%} of accuracy on the ReKV framework while reducing ViT encoding latency and LLM pre-filling latency by \textbf{24.5%} and \textbf{45.3%}.
💡 Research Summary
The paper tackles a critical bottleneck in streaming video large language models (VideoLLMs): the high computational cost of processing dense visual tokens from continuously arriving video frames. In streaming scenarios, the Vision Transformer (ViT) encoder dominates inference time because each new frame is fully encoded even when adjacent frames contain largely redundant visual information. Moreover, the resulting long sequence of visual tokens inflates the pre‑filling stage of the large language model (LLM), leading to quadratic self‑attention costs and large KV‑cache memory usage. Existing token‑compression methods either focus solely on the LLM side or assume access to the entire video, making them unsuitable for causal, real‑time streaming.
To address both sources of redundancy, the authors propose Streaming Token Compression (STC), a plug‑and‑play hierarchical framework that can be attached to any off‑the‑shelf VideoLLM without retraining. STC consists of two orthogonal modules:
-
STC‑Cacher – a cache‑aware selective computation mechanism for the ViT encoder.
- A reference frame is fully processed every N frames; all intermediate representations (keys, values, attention maps, MLP outputs) are cached per layer.
- For subsequent non‑reference frames, the cosine similarity between the current key projections and the cached reference keys is computed. Tokens with high similarity are deemed static and their values are directly reused from the cache, bypassing the expensive query‑value recomputation.
- Only the dynamically changing tokens (those with low similarity) have their query and value vectors recomputed, after which they are merged back into the cached attention matrices, effectively performing a low‑rank update.
- Two hyper‑parameters control the behavior: the cache interval N (how often a new reference frame is selected) and the reuse ratio R_Cacher (the proportion of tokens that are treated as static). In experiments, a setting of N = 4 and R_Cacher ≈ 75 % yields a 24.5 % reduction in ViT latency with negligible loss of visual fidelity.
-
STC‑Pruner – a causal token‑pruning stage applied after ViT encoding but before feeding tokens to the LLM.
- Each token receives a spatio‑temporal saliency score that combines (a) its activation magnitude, (b) its similarity to tokens in neighboring frames, and (c) a lightweight relevance estimate with respect to the current textual prompt.
- A lightweight scoring network (a few‑layer MLP) runs in real time, producing a ranking of tokens.
- Tokens below a configurable compression ratio (e.g., keep the top 30‑50 % most salient tokens) are discarded, shortening the sequence that the LLM must pre‑fill.
- Because the scoring uses only past visual information, the method is instruction‑agnostic and respects the causal constraints of streaming inference.
The combined effect of STC‑Cacher and STC‑Pruner is a two‑stage reduction of redundancy: the ViT encoder avoids recomputing static visual content, and the LLM receives a compact, high‑information token stream. The authors integrate STC into four representative streaming VideoLLMs (including Qwen2‑VL, LLaVA‑OV, ReKV, and a baseline model) and evaluate on five benchmarks covering video question answering, video captioning, and multimodal reasoning. Key results include:
- Accuracy preservation – On the ReKV framework, STC retains up to 99 % of the original accuracy despite aggressive token reduction.
- Latency gains – ViT encoding latency drops by an average of 24.5 % across models, while LLM pre‑filling latency is cut by 45.3 %.
- Memory savings – KV‑cache size is reduced by roughly 30 %, easing GPU memory pressure.
The paper also provides a thorough analysis of why prior methods fall short in streaming contexts. Token‑merging approaches like ToMe operate within ViT layers but disrupt the encoder’s representation learning and cannot be applied causally. KV‑cache compression methods (e.g., Sparse‑VLM, DyCoke) only address memory during decoding and ignore the dominant ViT cost. TimeChat‑Online drops tokens based on short‑range similarity but fails to capture longer‑range redundancy and often discards useful content. In contrast, STC’s design explicitly exploits temporal redundancy during encoding and performs a principled, saliency‑driven pruning before the LLM, all while remaining agnostic to future user instructions.
Limitations discussed include the reliance on cosine similarity for static token detection, which may be less effective for fast‑moving scenes, and the relatively simple saliency scoring network that could miss complex inter‑object relationships. Future work is suggested in adaptive reference‑frame selection via reinforcement learning, long‑range temporal modeling for token importance, and extending the framework to multimodal streams that include audio or sensor data.
In summary, Streaming Token Compression (STC) offers a practical, model‑agnostic solution that simultaneously accelerates the vision encoder and reduces LLM pre‑fill overhead in streaming video understanding. By preserving near‑original accuracy while cutting latency by nearly half, STC paves the way for deploying VideoLLMs in latency‑critical applications such as augmented‑reality glasses, live sports commentary, and real‑time robotic perception.
Comments & Academic Discussion
Loading comments...
Leave a Comment