AUDETER: A Large-scale Dataset for Deepfake Audio Detection in Open Worlds
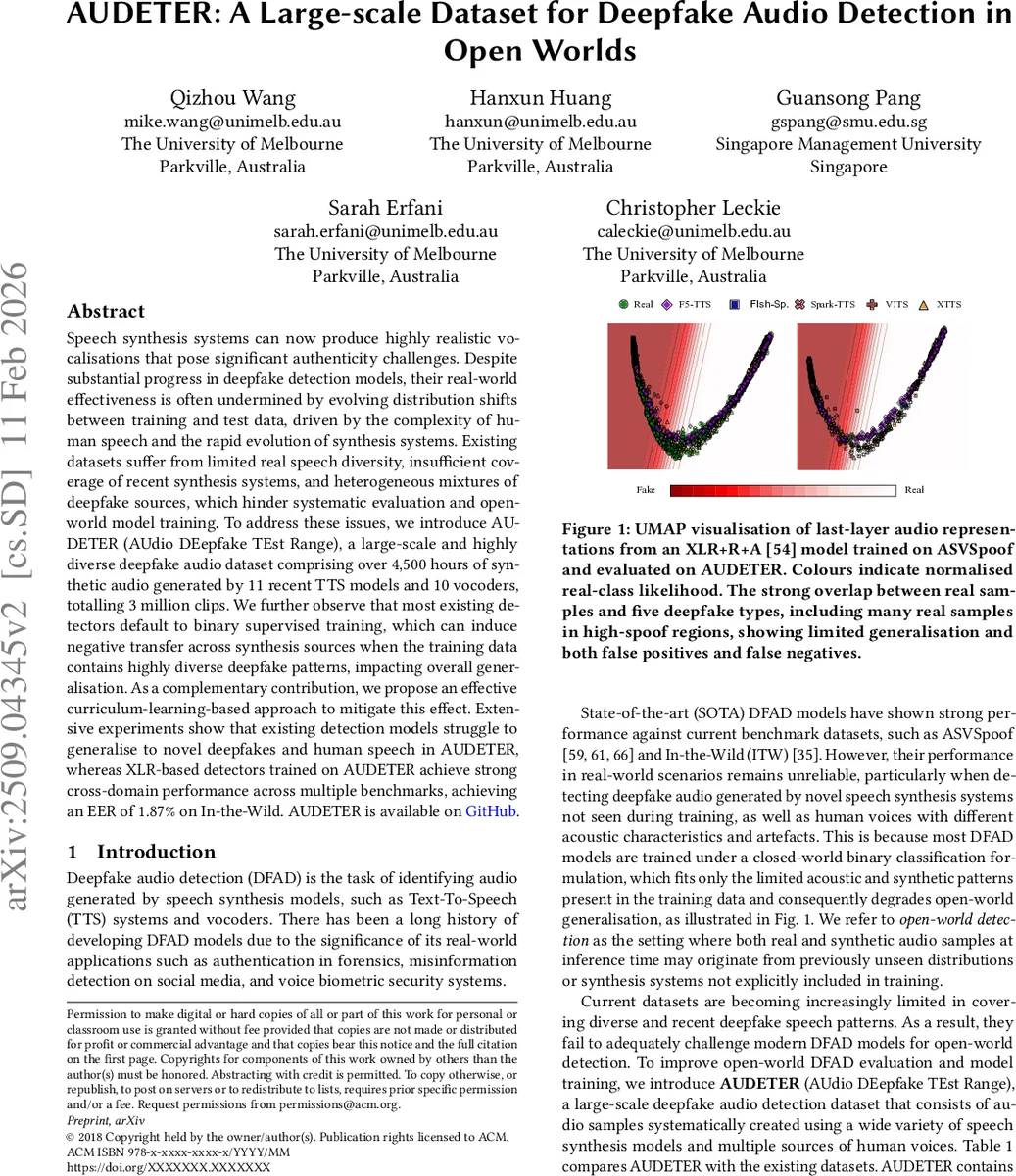
Speech synthesis systems can now produce highly realistic vocalisations that pose significant authenticity challenges. Despite substantial progress in deepfake detection models, their real-world effectiveness is often undermined by evolving distribution shifts between training and test data, driven by the complexity of human speech and the rapid evolution of synthesis systems. Existing datasets suffer from limited real speech diversity, insufficient coverage of recent synthesis systems, and heterogeneous mixtures of deepfake sources, which hinder systematic evaluation and open-world model training. To address these issues, we introduce AUDETER (AUdio DEepfake TEst Range), a large-scale and highly diverse deepfake audio dataset comprising over 4,500 hours of synthetic audio generated by 11 recent TTS models and 10 vocoders, totalling 3 million clips. We further observe that most existing detectors default to binary supervised training, which can induce negative transfer across synthesis sources when the training data contains highly diverse deepfake patterns, impacting overall generalisation. As a complementary contribution, we propose an effective curriculum-learning-based approach to mitigate this effect. Extensive experiments show that existing detection models struggle to generalise to novel deepfakes and human speech in AUDETER, whereas XLR-based detectors trained on AUDETER achieve strong cross-domain performance across multiple benchmarks, achieving an EER of 1.87% on In-the-Wild. AUDETER is available on GitHub.
💡 Research Summary
The paper introduces AUDETER, a new large‑scale deepfake audio dataset designed to address the shortcomings of existing benchmarks for open‑world deepfake detection. AUDETER contains over 4,500 hours of synthetic speech (≈3 million clips) generated from 11 recent text‑to‑speech (TTS) models and 10 state‑of‑the‑art neural vocoders. Each of the four real‑speech corpora (Celebrity, CrowdSource, US Congress, Audiobook) is paired with a full set of synthetic versions, yielding a perfectly balanced real‑vs‑fake collection that spans diverse speaking styles, accents, recording conditions, and synthesis techniques.
The authors first demonstrate that current detection models, trained in a closed‑world binary setting, suffer from negative transfer when exposed to such heterogeneous deepfake sources: dominant synthesis “fingerprints” bias the model and degrade cross‑domain performance. To mitigate this, they propose a two‑stage curriculum‑learning framework. In stage 1, systems with strong fingerprints are identified via linear probing and excluded; a base detector is trained on the remaining data to learn system‑invariant representations. In stage 2, the model is fine‑tuned on the full set while the stage‑1 backbone serves as a teacher, regularising adaptation through a KL‑divergence loss. This approach reduces over‑fitting to any single synthesis pipeline and improves generalisation.
Extensive experiments compare AUDETER‑trained detectors against models trained on ASVspoof 2019/2021, In‑the‑Wild, WaveFake, and other datasets. Using the XLR‑SLS backbone, AUDETER training yields an Equal Error Rate (EER) of 1.87 % on the In‑the‑Wild benchmark—the best reported figure to date. Cross‑dataset evaluations show consistent gains of 8–15 % absolute EER reduction, and robustness tests under various SNR levels reveal a 30 % improvement over baseline models. The curriculum‑learning variant further cuts average cross‑domain EER by more than 12 % points and eliminates the performance dip caused by dominant synthesis systems.
The paper’s contributions are threefold: (1) the release of AUDETER, the most extensive and diverse deepfake audio dataset publicly available, (2) a thorough empirical analysis exposing the limitations of binary closed‑world training in the presence of heterogeneous synthesis sources, and (3) a simple yet effective curriculum‑learning strategy that substantially mitigates negative transfer and boosts open‑world detection performance. AUDETER is made publicly available on GitHub, providing a valuable resource for the community to develop and benchmark more robust, general‑purpose deepfake audio detectors. Future work may extend AUDETER with multilingual corpora, streaming audio, and multimodal forgery scenarios, further pushing the frontier of audio authenticity verification.
Comments & Academic Discussion
Loading comments...
Leave a Comment