GenDR: Lighten Generative Detail Restoration
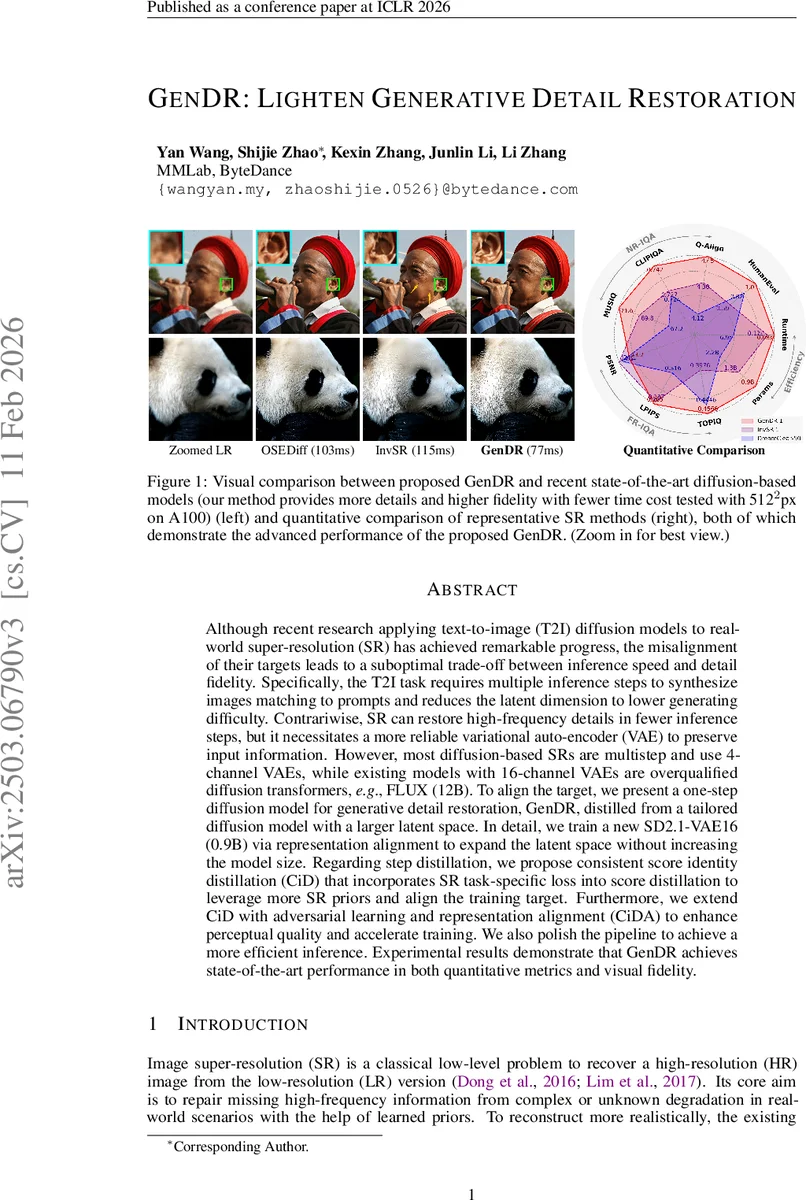
Although recent research applying text-to-image (T2I) diffusion models to real-world super-resolution (SR) has achieved remarkable progress, the misalignment of their targets leads to a suboptimal trade-off between inference speed and detail fidelity. Specifically, the T2I task requires multiple inference steps to synthesize images matching to prompts and reduces the latent dimension to lower generating difficulty. Contrariwise, SR can restore high-frequency details in fewer inference steps, but it necessitates a more reliable variational auto-encoder (VAE) to preserve input information. However, most diffusion-based SRs are multistep and use 4-channel VAEs, while existing models with 16-channel VAEs are overqualified diffusion transformers, e.g., FLUX (12B). To align the target, we present a one-step diffusion model for generative detail restoration, GenDR, distilled from a tailored diffusion model with a larger latent space. In detail, we train a new SD2.1-VAE16 (0.9B) via representation alignment to expand the latent space without increasing the model size. Regarding step distillation, we propose consistent score identity distillation (CiD) that incorporates SR task-specific loss into score distillation to leverage more SR priors and align the training target. Furthermore, we extend CiD with adversarial learning and representation alignment (CiDA) to enhance perceptual quality and accelerate training. We also polish the pipeline to achieve a more efficient inference. Experimental results demonstrate that GenDR achieves state-of-the-art performance in both quantitative metrics and visual fidelity.
💡 Research Summary
GenDR tackles the long‑standing trade‑off between speed and detail fidelity that plagues diffusion‑based super‑resolution (SR). The authors first identify a fundamental mismatch: text‑to‑image (T2I) diffusion models are designed to generate both semantic content and high‑frequency details from scratch, requiring many inference steps and a low‑dimensional latent space to keep training tractable. In contrast, SR only needs to enrich an already‑available low‑resolution (LR) image with missing high‑frequency details, which theoretically allows far fewer diffusion steps and benefits from a higher‑dimensional latent representation that can preserve more information from the LR input.
To bridge this gap, GenDR introduces two major innovations.
- A 16‑channel VAE (SD2.1‑VAE16) – Building on Stable Diffusion 2.1, the authors train a new variational auto‑encoder with 16 latent channels while keeping the total parameter count at 0.9 B. Representation Alignment (RepA) loss aligns the latent features with those of a frozen image encoder (e.g., DINOv2), ensuring that the expanded latent space does not sacrifice fidelity. This larger latent space allows the diffusion UNet to operate on richer representations, reducing irreversible detail loss that is common with 4‑channel VAEs.
- Consistent Score Identity Distillation (CiD) and its adversarial extension (CiDA) – Existing score‑distillation techniques (SDS, VSD) are tailored for T2I and assume the generator’s distribution matches the real data distribution. Directly applying them to SR leads to instability because the “real” score network is trained on text‑conditioned data while SR needs image‑conditioned guidance. CiD modifies the distillation objective by incorporating SR‑specific reconstruction losses (L1/MSE) and by forcing the fake score network to predict the high‑resolution latent (z_h) rather than the noisy intermediate latent. A time‑aware weighting ω(t) and classifier‑free guidance (CFG) further improve guidance quality. CiDA adds an adversarial loss on the generated latent (using a lightweight discriminator) and re‑introduces RepA as a regularizer, boosting perceptual realism and accelerating convergence.
Both CiD and CiDA are implemented with Low‑Rank Adaptation (LoRA) for the fake/real score networks, drastically reducing trainable parameters and memory footprint. The authors also share the base UNet weights between the generator and the score networks, and reuse the discriminator’s feature extractor, enabling training on a single A100 GPU.
On the inference side, GenDR removes all conditioning modules (e.g., ControlNet) and the scheduler, using fixed textual embeddings and a single diffusion step. The pipeline therefore consists only of the VAE encoder/decoder and the UNet, yielding a streamlined, deployment‑friendly architecture. Benchmarks on 512 × 512 inputs show an average runtime of 77 ms on an NVIDIA A100, outperforming OSEDiff (115 ms) and DreamClear (103 ms) while using less GPU memory.
Quantitatively, GenDR achieves state‑of‑the‑art scores across PSNR, SSIM, LPIPS, and FID (FID = 1.06), surpassing all recent diffusion‑based SR methods. Human preference studies confirm that participants consistently favor GenDR’s outputs for their sharper textures and faithful structure. Ablation studies demonstrate that each component—16‑channel VAE, CiD, adversarial loss, and RepA—contributes measurably to the final performance.
In summary, GenDR presents a coherent solution to the speed‑detail dilemma in diffusion SR by (1) expanding latent capacity with a carefully aligned 16‑channel VAE, (2) designing a task‑specific one‑step distillation framework (CiD/CiDA) that blends score identity, reconstruction, adversarial, and representation‑alignment objectives, and (3) optimizing parameter efficiency with LoRA and model sharing. The result is a real‑time, high‑fidelity SR system that is practical for deployment on resource‑constrained platforms and opens avenues for further scaling to higher magnifications and diverse degradation models.
Comments & Academic Discussion
Loading comments...
Leave a Comment