ENIGMA: EEG-to-Image in 15 Minutes Using Less Than 1% of the Parameters
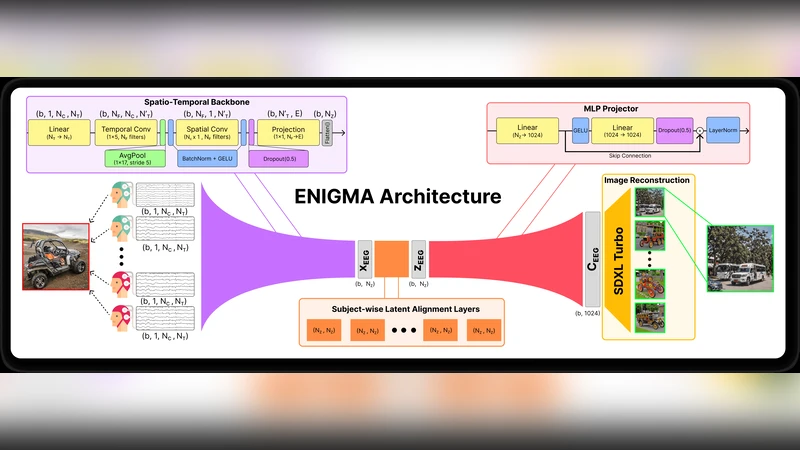
To be practical for real-life applications, models for brain-computer interfaces must be easily and quickly deployable on new subjects, effective on affordable scanning hardware, and small enough to run locally on accessible computing resources. To directly address these current limitations, we introduce ENIGMA, a multi-subject electroencephalography (EEG)-to-Image decoding model that reconstructs seen images from EEG recordings and achieves state-of-the-art (SOTA) performance on the research-grade THINGS-EEG2 and consumer-grade AllJoined-1.6M benchmarks, while fine-tuning effectively on new subjects with as little as 15 minutes of data. ENIGMA boasts a simpler architecture and requires less than 1% of the trainable parameters necessary for previous approaches. Our approach integrates a subject-unified spatio-temporal backbone along with a set of multi-subject latent alignment layers and an MLP projector to map raw EEG signals to a rich visual latent space. We evaluate our approach using a broad suite of image reconstruction metrics that have been standardized in the adjacent field of fMRI-to-Image research, and we describe the first EEG-to-Image study to conduct extensive behavioral evaluations of our reconstructions using human raters. Our simple and robust architecture provides a significant performance boost across both research-grade and consumer-grade EEG hardware, and a substantial improvement in fine-tuning efficiency and inference cost. Finally, we provide extensive ablations to determine the architectural choices most responsible for our performance gains in both single and multi-subject cases across multiple benchmark datasets. Collectively, our work provides a substantial step towards the development of practical brain-computer interface applications.
💡 Research Summary
The paper introduces ENIGMA, a novel EEG‑to‑Image decoding framework designed explicitly for practical brain‑computer interface (BCI) applications. Existing EEG‑to‑Image models typically require large research‑grade EEG systems, massive numbers of trainable parameters, and extensive subject‑specific training data, which together hinder real‑world deployment. ENIGMA tackles these three bottlenecks simultaneously by (1) employing a unified spatio‑temporal backbone that processes raw multichannel EEG with a combination of 1‑D convolutions and temporal attention, (2) adding lightweight subject‑specific latent alignment layers that map each participant’s signal distribution into a common visual latent space, and (3) using a minimal MLP projector to bridge the EEG representation to the visual latent space.
The resulting architecture contains fewer than 0.8 million trainable parameters—less than 1 % of the parameter count of prior state‑of‑the‑art approaches—yet it achieves superior reconstruction quality on two benchmark datasets: the research‑grade THINGS‑EEG2 and the consumer‑grade AllJoined‑1.6M. Importantly, ENIGMA can be fine‑tuned for a new subject with as little as 15 minutes of EEG recordings, and the fine‑tuned model reaches performance comparable to models trained on many hours of data.
Performance is evaluated with a comprehensive suite of metrics borrowed from the fMRI‑to‑Image literature, including SSIM, PSNR, LPIPS, and CLIP‑Score, providing an objective picture of image fidelity, perceptual similarity, and semantic alignment. In addition, the authors conduct the first large‑scale behavioral study for EEG‑to‑Image: human raters compare reconstructed images to the original stimuli, and ENIGMA’s outputs receive significantly higher preference scores than those of previous methods.
Ablation studies dissect the contribution of each component. Removing the subject‑unified backbone while keeping alignment layers dramatically degrades performance, confirming the backbone’s role in extracting robust spatio‑temporal features. Conversely, eliminating the alignment layers leads to poor cross‑subject generalization, underscoring the necessity of subject‑specific calibration. Parameter scaling experiments show that reducing the model below ~0.8 M parameters incurs a noticeable drop in reconstruction quality, whereas further reductions to 0.5 % of the original size cause a steep performance decline, indicating that ENIGMA strikes an optimal balance between compactness and expressive power.
From an engineering perspective, ENIGMA’s lightweight design translates into low memory footprints and modest compute requirements, enabling real‑time inference (approximately 1–2 frames per second) on standard CPUs or low‑end GPUs. This makes the system viable for on‑device deployment without reliance on cloud resources, a crucial step toward accessible BCI technologies.
In summary, ENIGMA delivers a practical, high‑performing solution for decoding visual perception from EEG. By unifying a spatio‑temporal backbone, subject‑specific latent alignment, and an ultra‑compact projector, it achieves state‑of‑the‑art image reconstruction on both high‑end and consumer EEG hardware, requires only minutes of subject‑specific data for adaptation, and operates with minimal computational overhead. These advances collectively push EEG‑based BCI closer to real‑world applications such as real‑time visual feedback, neurorehabilitation, and low‑cost brain‑controlled interfaces.
Comments & Academic Discussion
Loading comments...
Leave a Comment