ESTAR: Early-Stopping Token-Aware Reasoning For Efficient Inference
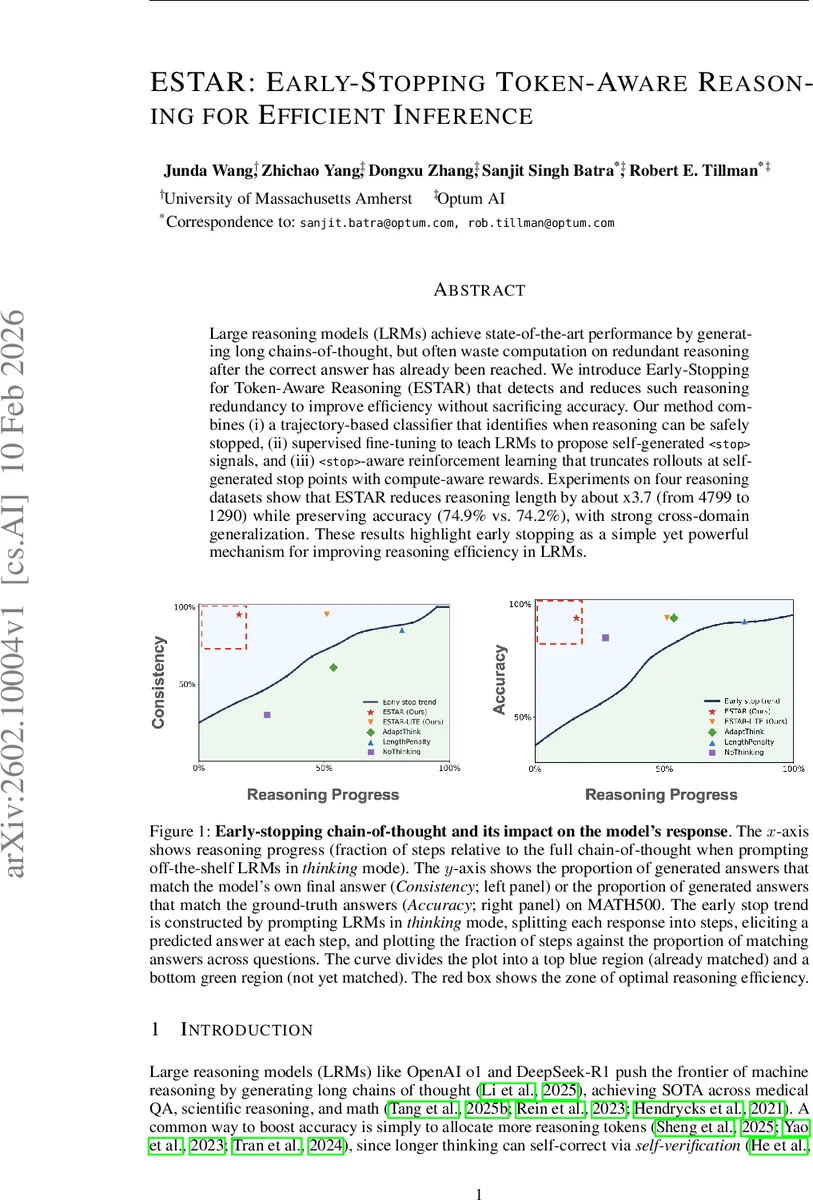
Large reasoning models (LRMs) achieve state-of-the-art performance by generating long chains-of-thought, but often waste computation on redundant reasoning after the correct answer has already been reached. We introduce Early-Stopping for Token-Aware Reasoning (ESTAR), which detects and reduces such reasoning redundancy to improve efficiency without sacrificing accuracy. Our method combines (i) a trajectory-based classifier that identifies when reasoning can be safely stopped, (ii) supervised fine-tuning to teach LRMs to propose self-generated
💡 Research Summary
The paper tackles the inefficiency of large reasoning models (LRMs) that continue generating chain‑of‑thought (CoT) tokens even after the correct answer has already been reached. The authors propose ESTAR (Early‑Stopping Token‑Aware Reasoning), a three‑component framework designed to detect and truncate redundant reasoning while preserving answer quality.
First, ESTAR‑LITE is a lightweight online classifier built with LightGBM. At each decoding step it extracts a feature vector from the model’s top‑k token log‑probabilities, answer‑bucket probabilities, slope and curvature of a confidence score, and stability metrics such as answer flips. The classifier outputs a stop probability ρₜ; when ρₜ exceeds a preset threshold, the system deems the current step safe to stop.
Second, the authors fine‑tune the LRM to emit a special
Third, a reinforcement‑learning stage incorporates a compute‑aware reward that combines (i) answer correctness, (ii) the number of tokens used (shorter is better), and (iii) the confidence score from ESTAR‑LITE. Rollouts are truncated as soon as a
Experiments on four in‑domain reasoning benchmarks (USMLE, JAMA, Math500, AIME2025) and an out‑of‑domain set (GPQA) show that ESTAR reduces average CoT length from 4,799 to 1,290 tokens (≈3.7× reduction) while retaining 98.9 % of the original accuracy (74.9 % → 74.2 %). ESTAR‑LITE alone already cuts length by 2–6× with ≥95 % accuracy, and outperforms prior efficiency methods such as LengthPenalty (1.4× shorter, 97 % relative accuracy) and AdaptThink (2.2× shorter, 97.4 % relative accuracy).
Theoretical analysis introduces a “tail variation” metric TVₜ that quantifies how much the answer posterior changes after step t. The authors prove that stopping when TVₜ ≤ c·γₜ (γₜ being the confidence margin) is sufficient for safety, and they approximate this condition with the learned classifier.
Overall, ESTAR demonstrates that a principled early‑stop mechanism—combining a data‑driven classifier, self‑generated stop tokens, and reinforcement learning—can dramatically improve inference efficiency of large reasoning models without sacrificing performance, offering a practical solution for real‑world deployment where latency and compute cost matter.
Comments & Academic Discussion
Loading comments...
Leave a Comment