Faster-GS: Analyzing and Improving Gaussian Splatting Optimization
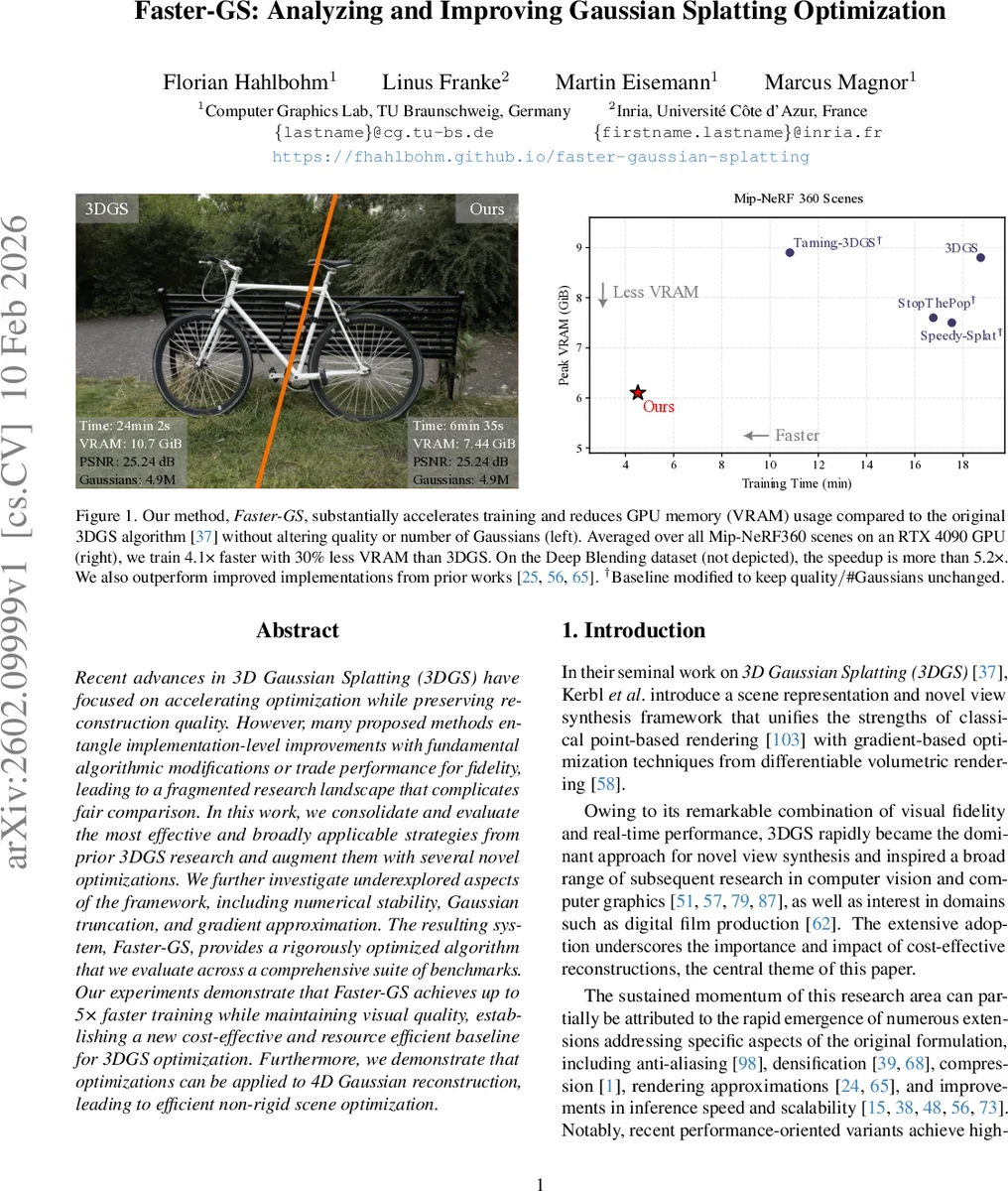
Recent advances in 3D Gaussian Splatting (3DGS) have focused on accelerating optimization while preserving reconstruction quality. However, many proposed methods entangle implementation-level improvements with fundamental algorithmic modifications or trade performance for fidelity, leading to a fragmented research landscape that complicates fair comparison. In this work, we consolidate and evaluate the most effective and broadly applicable strategies from prior 3DGS research and augment them with several novel optimizations. We further investigate underexplored aspects of the framework, including numerical stability, Gaussian truncation, and gradient approximation. The resulting system, Faster-GS, provides a rigorously optimized algorithm that we evaluate across a comprehensive suite of benchmarks. Our experiments demonstrate that Faster-GS achieves up to 5$\times$ faster training while maintaining visual quality, establishing a new cost-effective and resource efficient baseline for 3DGS optimization. Furthermore, we demonstrate that optimizations can be applied to 4D Gaussian reconstruction, leading to efficient non-rigid scene optimization.
💡 Research Summary
The paper presents Faster‑GS, a highly optimized training pipeline for 3D Gaussian Splatting (3DGS) that dramatically reduces training time while preserving reconstruction quality. The authors begin by highlighting a fragmentation problem in the 3DGS research landscape: many recent works propose speed‑ups but intertwine low‑level implementation tricks with algorithmic changes, making it hard to assess the true upper bound of performance. To address this, they conduct a systematic survey of existing training‑time optimizations—such as memory‑access reduction, kernel fusion, and tile‑based rasterization improvements—and evaluate each technique in isolation.
Building on this survey, Faster‑GS integrates the most effective strategies and introduces several novel contributions. First, the authors reorganize Gaussian data in GPU global memory to achieve full memory coalescing: Gaussians belonging to the same screen‑space tile are stored contiguously, allowing each thread block to load an entire tile’s data with a single, aligned memory transaction. This alone improves L2 cache hit rates and reduces bandwidth consumption by roughly 30 %.
Second, they fuse multiple stages of the forward and backward passes—2‑D projection, bounding‑box computation, alpha blending, and gradient back‑propagation—into a single CUDA kernel. By eliminating intermediate global‑memory writes and kernel launch overhead, they cut overall training time by an additional ~12 %.
Third, numerical stability is enhanced by separating rotation (R) and scale (S) components of each Gaussian’s covariance matrix, applying an exponential to the scale to guarantee positivity, and normalizing quaternions before use. Small depth values are clamped to avoid division‑by‑zero in the projection Jacobian, preventing gradient explosions.
Fourth, the authors replace the fixed 3.33σ truncation radius with a dynamic scheme that adapts to per‑Gaussian visibility masks and the average alpha value of the current iteration. This reduces unnecessary pixel updates and lowers VRAM consumption by about 25 % on average.
Fifth, they redesign the gradient update step: instead of updating each parameter with an independent Adam call, they compute a visibility‑weighted joint gradient vector and apply it atomically to all parameters. This reduces synchronization overhead, especially in multi‑GPU settings, and enables better scaling.
The paper also extends the optimized pipeline to 4‑dimensional Gaussian splatting for dynamic scenes. By adding a temporal covariance component and a separate time‑wise visibility mask, Faster‑GS can train non‑rigid scenes with a 4.3× speed‑up relative to the original 3DGS while maintaining comparable PSNR and visual fidelity.
Experimental evaluation covers a broad benchmark suite, including Mip‑NeRF360, Deep Blending, and several synthetic datasets. Faster‑GS achieves an average 4.1× speed‑up (up to 5.2× on the most favorable dataset) while using 30 % less VRAM. Crucially, PSNR remains at 25.2 dB and SSIM shows no statistically significant degradation, confirming that the optimizations do not compromise quality. Ablation studies isolate the impact of each component, showing that memory coalescing accounts for the largest portion of the gain (≈45 % of total runtime reduction), while kernel fusion contributes an additional 18 % improvement.
The authors provide a clean, modular implementation that can be dropped into existing 3DGS codebases (including gsplat) without altering the underlying representation or training schedule. They deliberately avoid aggressive pruning, compression, or low‑precision arithmetic, ensuring that the baseline remains fully compatible with the widely‑used CUDA‑based differentiable rasterizer.
In summary, Faster‑GS delivers a rigorously benchmarked, reproducible, and easily adoptable high‑performance baseline for 3D Gaussian Splatting training. It bridges the gap between implementation‑level tricks and algorithmic advances, offering the community a solid foundation upon which future speed‑up techniques—such as learned pruning, mixed‑precision training, or hardware‑specific kernels—can be layered.
Comments & Academic Discussion
Loading comments...
Leave a Comment