The Catastrophic Failure of The k-Means Algorithm in High Dimensions, and How Hartigan's Algorithm Avoids It
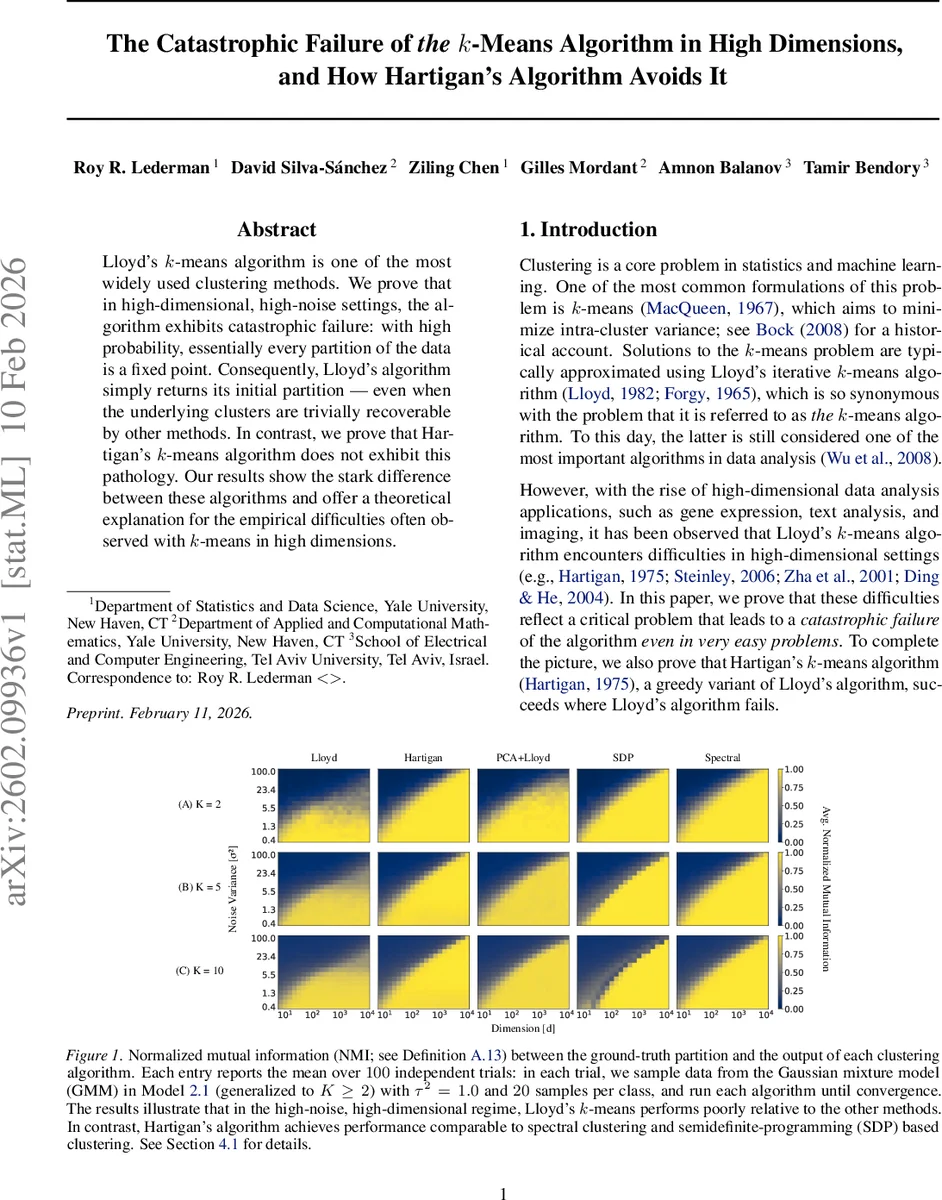
Lloyd’s k-means algorithm is one of the most widely used clustering methods. We prove that in high-dimensional, high-noise settings, the algorithm exhibits catastrophic failure: with high probability, essentially every partition of the data is a fixed point. Consequently, Lloyd’s algorithm simply returns its initial partition - even when the underlying clusters are trivially recoverable by other methods. In contrast, we prove that Hartigan’s k-means algorithm does not exhibit this pathology. Our results show the stark difference between these algorithms and offer a theoretical explanation for the empirical difficulties often observed with k-means in high dimensions.
💡 Research Summary
The paper investigates a striking failure mode of the widely used Lloyd’s k‑means algorithm in high‑dimensional, high‑noise regimes, and shows that Hartigan’s variant avoids this pathology. The authors consider a two‑component isotropic Gaussian mixture model (GMM) in ℝ^d with means μ*_1, μ*_2 ∼ N(0, τ²I_d) and additive noise ξ_i ∼ N(0, σ²I_d). For n samples, they analyze the behavior of Lloyd’s batch reassignment and Hartigan’s greedy single‑sample moves when the noise variance σ² exceeds the sample size (σ² > n) and the dimension d grows.
Key technical contributions begin with Lemma 3.1 and Lemma 3.2, which characterize the squared distances from a data point to the centroid of its current cluster and to the centroid of the opposite cluster. Both distances follow scaled chi‑square distributions with d degrees of freedom, where the scaling factors α_cur and α_alt depend on cluster purity, cluster sizes, and the signal‑to‑noise ratio (τ, σ). Using a Chernoff‑type bound (Lemma 3.3), the authors derive exponential tails for the difference of two such scaled chi‑square variables.
Theorem 3.4 studies the probability that a single mis‑assigned point will be corrected in the next Lloyd iteration. Under the condition σ > √(2 c̄ τ (c − 1)/
Comments & Academic Discussion
Loading comments...
Leave a Comment