VersaViT: Enhancing MLLM Vision Backbones via Task-Guided Optimization
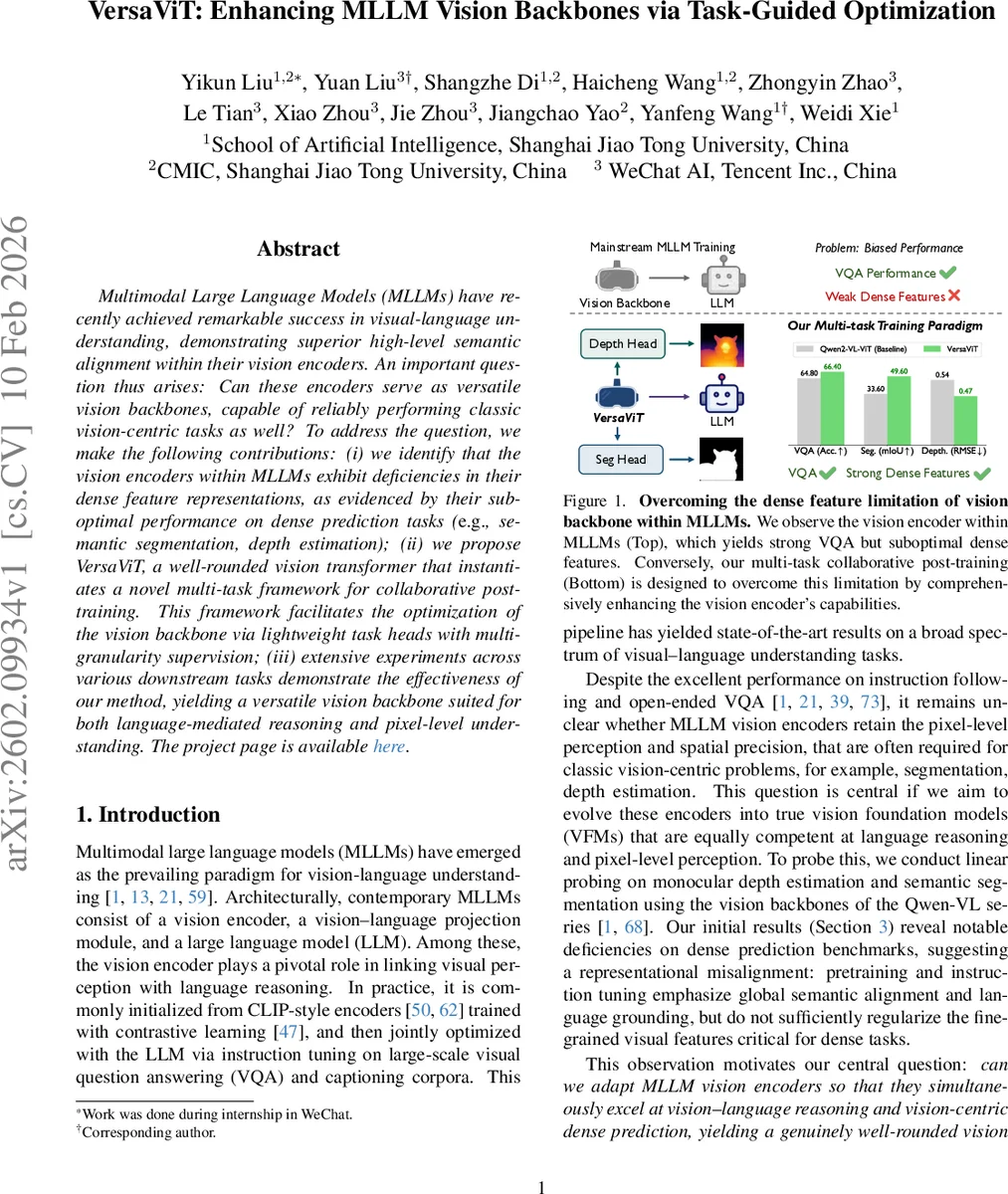
Multimodal Large Language Models (MLLMs) have recently achieved remarkable success in visual-language understanding, demonstrating superior high-level semantic alignment within their vision encoders. An important question thus arises: Can these encoders serve as versatile vision backbones, capable of reliably performing classic vision-centric tasks as well? To address the question, we make the following contributions: (i) we identify that the vision encoders within MLLMs exhibit deficiencies in their dense feature representations, as evidenced by their suboptimal performance on dense prediction tasks (e.g., semantic segmentation, depth estimation); (ii) we propose VersaViT, a well-rounded vision transformer that instantiates a novel multi-task framework for collaborative post-training. This framework facilitates the optimization of the vision backbone via lightweight task heads with multi-granularity supervision; (iii) extensive experiments across various downstream tasks demonstrate the effectiveness of our method, yielding a versatile vision backbone suited for both language-mediated reasoning and pixel-level understanding.
💡 Research Summary
The paper “VersaViT: Enhancing MLLM Vision Backbones via Task-Guided Optimization” addresses a critical gap in the development of Multimodal Large Language Models (MLLMs). While MLLMs have achieved remarkable success in high-level visual-language reasoning, their core vision encoders often exhibit significant weaknesses when applied to classic, vision-centric dense prediction tasks like semantic segmentation and monocular depth estimation. The authors diagnose this issue as a representational skew caused by the prevailing MLLM training recipe, which prioritizes global semantic alignment through contrastive pre-training and text-centric instruction tuning but fails to adequately regularize fine-grained, pixel-level visual features.
To bridge this capability gap, the paper introduces VersaViT, a method for creating a well-rounded vision backbone via a novel multi-task collaborative post-training framework. The core idea is to re-balance and enhance a pre-existing MLLM vision encoder (e.g., from Qwen2-VL) by jointly training it on a set of complementary tasks that provide multi-granularity supervision. The framework attaches three lightweight, task-specific heads to a shared vision backbone:
- Generative Vision-Language Fine-tuning (VQA/Captioning): Maintains and enhances high-level semantic alignment and instruction-following capability.
- Monocular Depth Estimation: Injects mid-level, 3D-aware spatial reasoning and geometric consistency using pseudo-labels generated by the Depth Anything V2 model.
- Referring Image Segmentation: Instills low-level, pixel-wise precision and language-conditioned localization ability.
These tasks are trained concurrently with a combined loss function. A key design principle is that task-specific conflicts are absorbed by the individual heads, allowing the shared vision backbone to evolve towards a more general, transferable, and “dense-friendly” feature representation without sacrificing its original language grounding prowess.
The proposed method is extensively validated across a wide range of downstream tasks. Results demonstrate that VersaViT not only preserves or even improves the original VQA performance of the backbone but also leads to dramatic improvements on dense prediction benchmarks. For instance, it significantly boosts metrics on semantic segmentation (ADE20k, Pascal Context), referring segmentation (RefCOCO/+/g), and depth estimation (NYUv2). This synergistic outcome proves that supervision from different task granularities can be complementary when mediated through a properly designed multi-task framework.
In conclusion, VersaViT presents a practical and effective pathway for evolving MLLM vision encoders into more versatile Vision Foundation Models (VFMs). It offers a modular, post-training solution that enhances pixel-level perception and spatial reasoning while maintaining language understanding, all with minimal engineering overhead compared to full model retraining. This work challenges the assumption of a trade-off between high-level semantic and low-level perceptual tasks, showcasing the potential for a single, balanced vision backbone excelling in both domains.
Comments & Academic Discussion
Loading comments...
Leave a Comment