Flexible Entropy Control in RLVR with Gradient-Preserving Perspective
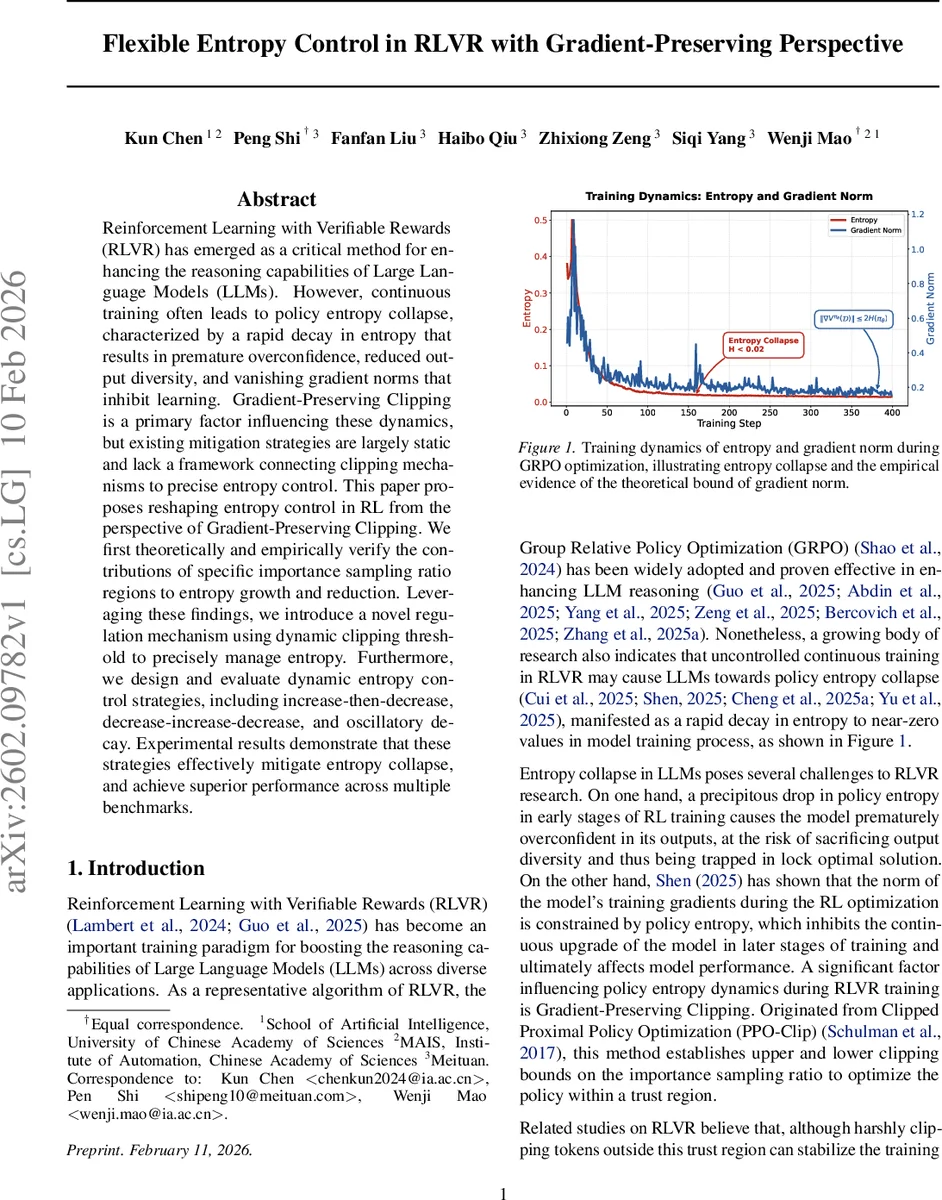
Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a critical method for enhancing the reasoning capabilities of Large Language Models (LLMs). However, continuous training often leads to policy entropy collapse, characterized by a rapid decay in entropy that results in premature overconfidence, reduced output diversity, and vanishing gradient norms that inhibit learning. Gradient-Preserving Clipping is a primary factor influencing these dynamics, but existing mitigation strategies are largely static and lack a framework connecting clipping mechanisms to precise entropy control. This paper proposes reshaping entropy control in RL from the perspective of Gradient-Preserving Clipping. We first theoretically and empirically verify the contributions of specific importance sampling ratio regions to entropy growth and reduction. Leveraging these findings, we introduce a novel regulation mechanism using dynamic clipping threshold to precisely manage entropy. Furthermore, we design and evaluate dynamic entropy control strategies, including increase-then-decrease, decrease-increase-decrease, and oscillatory decay. Experimental results demonstrate that these strategies effectively mitigate entropy collapse, and achieve superior performance across multiple benchmarks.
💡 Research Summary
The paper addresses a critical failure mode in Reinforcement Learning with Verifiable Rewards (RLVR) for large language models: policy‑entropy collapse. During continuous RL training, the entropy of the policy distribution rapidly decays, causing premature over‑confidence, loss of output diversity, and a reduction in gradient magnitude because the gradient norm is bounded by the entropy (‖∇Vπ‖ ≤ 2H). The authors identify Gradient‑Preserving Clipping (the clipping of the importance‑sampling ratio in PPO‑Clip) as a primary driver of this collapse. Existing approaches treat the clipping thresholds as static hyper‑parameters, which either suppress low‑probability “exploration” tokens or over‑amplify high‑probability tokens, both of which accelerate entropy loss.
Theoretical contribution
The authors derive a closed‑form relationship between the policy‑gradient of the surrogate PPO objective and the gradient of the entropy. By computing the inner product ⟨∇L,∇H⟩ they show that the sign of the entropy change depends on the sign of the advantage (Â) and the token’s surprisal (−ln πθ(a|s)) relative to the current entropy H. This yields four distinct “entropy‑sensitive regions”:
- E1 (high probability, Â>0) – entropy decreases.
- E2 (low probability, Â>0) – entropy increases.
- E3 (high probability, Â<0) – entropy increases.
- E4 (low probability, Â<0) – entropy decreases.
These regions are empirically validated by selectively applying clipping only to tokens that fall within each region (0.7 < r < 1.3). The experiments confirm that E1/E4 consistently shrink entropy while E2/E3 expand it.
Dynamic clipping mechanism
Building on this insight, the paper proposes two adaptive clipping functions:
- Dynamic upper clipping ε↑(πθ) = α·πθ + β with α < 0. The threshold is larger for low‑probability tokens (encouraging exploration) and smaller for high‑probability tokens (preventing over‑concentration).
- Dynamic lower clipping ε↓(πθ) = γ·πθ + δ with γ > 0, which tightens the lower bound for tokens that would otherwise be boosted when a negative‑advantage token is penalized.
Both functions are linear in the current token probability, ensuring easy implementation and numerical stability while providing a non‑linear effect on the effective clipping interval.
Entropy‑control schedules
The authors design three schedule families that modulate the dynamic thresholds over training time:
- Increase‑Then‑Decrease (ID) – start with a high upper threshold to boost exploration, then gradually lower it to consolidate learning.
- Decrease‑Increase‑Decrease (DID) – begin conservatively, open the policy later for renewed exploration, and finally tighten again for stability.
- Oscillatory Decay (OD) – periodically oscillate the thresholds, preventing the policy from settling in a local optimum.
Experimental validation
Experiments use a GPT‑style LLM trained with Group Relative Policy Optimization (GRPO) on five RLVR benchmarks (multiple‑choice QA, code generation, logical reasoning, dialogue, summarization). Compared to standard PPO‑Clip and static “Clip‑Higher/Clip‑Lower” baselines, the dynamic‑clipping + ID strategy maintains a stable entropy curve, avoids the ‖∇Vπ‖ ≤ 2H bottleneck, and yields an average 3.2 % absolute improvement in task performance. The DID and OD variants show similar gains, with OD achieving the highest final scores on tasks that benefit from sustained exploration.
Impact and future work
The paper provides a rigorous mathematical link between clipping behavior and entropy dynamics, turning a previously heuristic component into a controllable lever. By demonstrating that entropy can be precisely steered through probability‑dependent clipping, it opens the door to more robust RLVR pipelines that retain diversity and gradient flow throughout training. Future directions suggested include learning non‑linear ε(πθ) functions via meta‑learning, extending the approach to other policy‑gradient algorithms (e.g., TRPO, A2C), and integrating the schedule into automated hyper‑parameter tuning frameworks.
Comments & Academic Discussion
Loading comments...
Leave a Comment