DR.Experts: Differential Refinement of Distortion-Aware Experts for Blind Image Quality Assessment
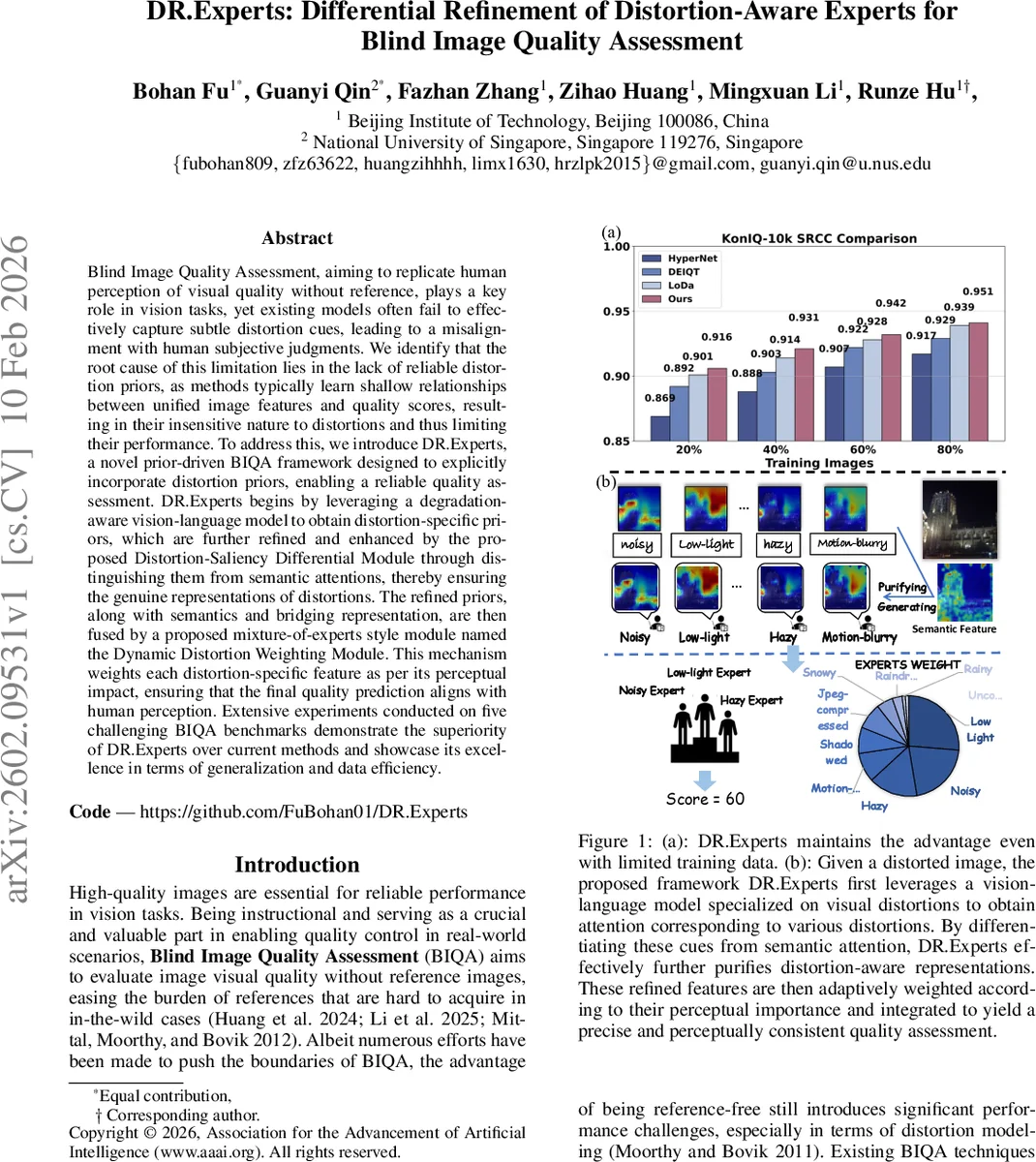
Blind Image Quality Assessment, aiming to replicate human perception of visual quality without reference, plays a key role in vision tasks, yet existing models often fail to effectively capture subtle distortion cues, leading to a misalignment with human subjective judgments. We identify that the root cause of this limitation lies in the lack of reliable distortion priors, as methods typically learn shallow relationships between unified image features and quality scores, resulting in their insensitive nature to distortions and thus limiting their performance. To address this, we introduce DR.Experts, a novel prior-driven BIQA framework designed to explicitly incorporate distortion priors, enabling a reliable quality assessment. DR.Experts begins by leveraging a degradation-aware vision-language model to obtain distortion-specific priors, which are further refined and enhanced by the proposed Distortion-Saliency Differential Module through distinguishing them from semantic attentions, thereby ensuring the genuine representations of distortions. The refined priors, along with semantics and bridging representation, are then fused by a proposed mixture-of-experts style module named the Dynamic Distortion Weighting Module. This mechanism weights each distortion-specific feature as per its perceptual impact, ensuring that the final quality prediction aligns with human perception. Extensive experiments conducted on five challenging BIQA benchmarks demonstrate the superiority of DR.Experts over current methods and showcase its excellence in terms of generalization and data efficiency.
💡 Research Summary
DR.Experts introduces a novel paradigm for blind image quality assessment (BIQA) that explicitly incorporates distortion priors into the learning pipeline, addressing the long‑standing issue of insufficient sensitivity to subtle degradations in existing methods. The framework consists of three key components. First, a distortion‑specific prior module leverages a low‑level vision‑language model, DA‑CLIP, which extends CLIP with an additional image controller trained to predict distortion embeddings. By feeding an input image and a set of ten textual prompts (e.g., “motion‑blur”, “low‑light”, “jpeg‑compressed”) into the frozen CLIP text and image encoders, DA‑CLIP produces a set of attention maps that serve as initial distortion‑aware features. These are obtained via a Hadamard product between image and text embeddings followed by a linear projection, yielding a per‑distortion feature vector F_i^D for each distortion type i.
Second, the Distortion‑Saliency Differential Module (DSDM) refines these raw priors. Because DA‑CLIP’s outputs still contain semantic noise inherited from its pre‑training on ImageNet‑style classification, DSDM applies a differential attention mechanism inspired by the Differential Transformer. For each distortion type, query and key matrices are derived from both the distortion features (Q_i^D, K_i^D) and the semantic features extracted by a Vision Transformer (ViT) backbone (Q_i, K_i). The module computes softmax(Q_i^D K_i^{D,T}) and subtracts a scaled version of softmax(Q_i K_i^{T}) using a learnable coefficient α, then multiplies the result by a value matrix that concatenates semantic and distortion features. This operation isolates distortion‑specific information while suppressing overlapping semantic content, producing a clean distortion feature F_i^{distortion}. All refined distortion features are passed through a two‑layer feed‑forward network (FFN) with GELU activation, generating a set of expert representations that capture the characteristics of each distortion type.
Third, the Dynamic Distortion Weighting Module (DDWM) aggregates the refined distortion experts, the original semantic token, and a bridging feature (the difference between the two) within a Mixture‑of‑Experts (MoE) architecture. DDWM learns dynamic weights w_i for each expert based on the image’s distortion composition, effectively modeling the perceptual impact of each degradation. The weighted sum forms a comprehensive quality token, which is finally fed to a regression head to produce the predicted quality score.
Extensive experiments on five challenging BIQA benchmarks—LIVE‑Challenge, KonIQ‑10k, SPAQ, TID2013, and CSIQ—show that DR.Experts consistently outperforms state‑of‑the‑art CNN‑based, ViT‑based, and CLIP‑based BIQA models in terms of Spearman’s rank correlation coefficient (SRCC) and Pearson’s linear correlation coefficient (PLCC). Notably, when the training set is reduced to less than 10 % of the original size, performance degradation remains minimal, demonstrating strong data efficiency. Visualizations of the learned distortion weights reveal that the model assigns higher importance to distortion types that human observers deem most detrimental (e.g., low‑light, noise), providing interpretability and traceability of the final score.
In summary, DR.Experts pioneers the use of explicit distortion priors derived from a vision‑language model, refines them through a differential attention mechanism, and dynamically weights them in an expert‑based aggregation. This design yields a BIQA system that is both highly accurate and aligned with human perceptual judgments, while offering explainability and robustness to limited training data. The approach opens new avenues for distortion‑aware quality assessment in images, videos, and multimodal vision applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment