AgentSkiller: Scaling Generalist Agent Intelligence through Semantically Integrated Cross-Domain Data Synthesis
Large Language Model agents demonstrate potential in solving real-world problems via tools, yet generalist intelligence is bottlenecked by scarce high-quality, long-horizon data. Existing methods collect privacy-constrained API logs or generate scripted interactions lacking diversity, which struggle to produce data requisite for scaling capabilities. We propose AgentSkiller, a fully automated framework synthesizing multi-turn interaction data across realistic, semantically linked domains. It employs a DAG-based architecture with explicit state transitions to ensure determinism and recoverability. The pipeline builds a domain ontology and Person-Centric Entity Graph, defines tool interfaces via Service Blueprints for Model Context Protocol servers, and populates environments with consistent databases and strict Domain Policies. A cross-domain fusion mechanism links services to simulate complex tasks. Finally, the pipeline creates user tasks by verifying solution paths, filtering via execution-based validation, and generating queries using a Persona-based Simulator for automated rollout. This produces reliable environments with clear state changes. To demonstrate effectiveness, we synthesized $\approx$ 11K interaction samples; experimental results indicate that models trained on this dataset achieve significant improvements on function calling over baselines, particularly in larger parameter regimes.
💡 Research Summary
AgentSkiller addresses a critical bottleneck in the development of generalist LLM‑based agents: the scarcity of high‑quality, long‑horizon, multi‑turn interaction data that span multiple tool‑using domains. Existing data‑generation strategies fall into two camps—collecting real‑world API logs (limited by privacy, coverage, and scale) and scripted synthetic interactions (lacking diversity and naturalness). Both approaches fail to provide the volume and realism needed for scaling agent capabilities.
The proposed framework automates the entire pipeline from abstract domain ideas to fully executable environments, producing roughly 11 000 multi‑turn interaction trajectories across realistic, semantically linked domains. Its architecture rests on three design principles: (1) a Dual‑Model Architecture that separates high‑level semantic reasoning (handled by a text‑oriented LLM such as GPT‑5.2) from low‑level code generation (handled by a coding‑oriented LLM such as Claude Opus); (2) State‑Machine Orchestration implemented as a Directed Acyclic Graph (DAG) of 18 atomic steps managed by LangGraph, with automatic checkpointing for fault tolerance; and (3) Test‑Driven Self‑Correction, whereby generated SQL, Python, or Model Context Protocol (MCP) server code is executed against a test suite, and any failures trigger an automated “Block Editor” that iteratively patches the code based on error traces.
The synthesis pipeline proceeds through five sequential phases:
-
Domain Ontology & Person‑Centric Entity Graph Construction – Starting from a curated list of seed topics (e.g., healthcare, finance, travel), the system expands the ontology, extracts domain‑invariant entities, and builds a graph centered on realistic persons, organizations, and products. This graph provides a coherent semantic backbone for downstream scenario generation.
-
Service Blueprint Generation – For each domain, explicit MCP server specifications are created, defining input/output schemas, authentication requirements, rate limits, and error codes. These blueprints serve as contracts that guarantee deterministic tool behavior.
-
Database & Policy Implementation – Using the ontology and entity graph, constraint‑satisfying relational databases are automatically populated, and domain policies are synthesized to enforce data integrity and access control.
-
Cross‑Domain Fusion – Independent services are linked to simulate complex, multi‑step tasks (e.g., “retrieve patient record → file insurance claim → process payment”). The DAG ensures that state transitions are deterministic and fully recoverable, enabling reproducible multi‑domain interactions.
-
Task Instantiation & Validation – A planner searches for feasible solution paths that achieve a predefined goal state. Each candidate path undergoes execution‑based validation; only trajectories that succeed without errors are retained. A Persona‑Based Simulator then generates natural‑language user queries, and an automated Rollout engine executes the full dialogue, producing high‑fidelity interaction logs.
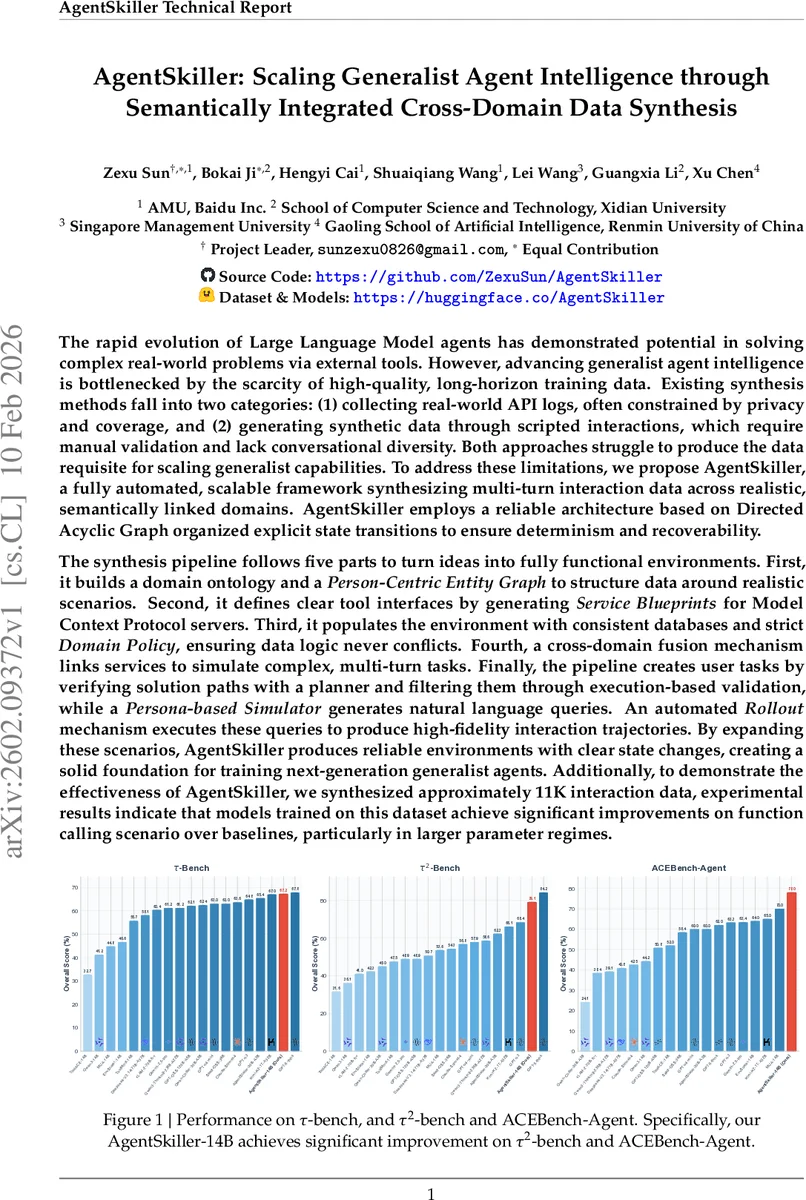
Training a 14‑billion‑parameter model (AgentSkiller‑14B) on the synthesized dataset, the authors evaluate performance on three function‑calling benchmarks: τ‑bench, τ2‑bench, and ACEBench‑Agent. AgentSkiller‑14B consistently outperforms open‑source baselines such as ToolACE‑14B, Qwen3‑14B, and others, achieving overall scores above 63 % and improvements of 5–10 percentage points over comparable models. Notably, the performance gap widens for larger models (30 B+ parameters), indicating that the synthesized data scales effectively with model size.
Key insights from the study include:
- Data Diversity and Realism – By grounding environments in a person‑centric ontology and linking services across domains, the generated interactions exhibit richer contextual variation than manually scripted datasets.
- Deterministic State Transitions – The DAG‑based state machine guarantees that every step is reproducible, simplifying debugging and enabling systematic curriculum generation.
- Automated Quality Assurance – Test‑driven self‑correction eliminates syntactic and logical errors before data is released, reducing the need for costly human annotation.
Limitations are acknowledged. The ontology expansion currently relies on manually curated seed topics, which may constrain coverage in niche domains. Cross‑domain fusion can become computationally expensive as the number of linked services grows, potentially limiting scalability. Moreover, the current implementation focuses on English‑language prompts, leaving multilingual extensions as future work.
Future directions proposed include:
- Leveraging large‑scale web crawls and knowledge graphs to automate ontology growth.
- Integrating reinforcement‑learning planners to improve goal‑path discovery efficiency.
- Developing meta‑validation techniques that combine automated testing with minimal human oversight to further cut labeling costs.
In conclusion, AgentSkiller presents a robust, fully automated pipeline that synthesizes high‑quality, multi‑turn, cross‑domain interaction data at scale. Empirical results demonstrate that training on this data yields substantial gains in function‑calling ability, especially for larger LLMs, positioning AgentSkiller as a foundational infrastructure for advancing generalist agent intelligence.
Comments & Academic Discussion
Loading comments...
Leave a Comment