ALIVE: Animate Your World with Lifelike Audio-Video Generation
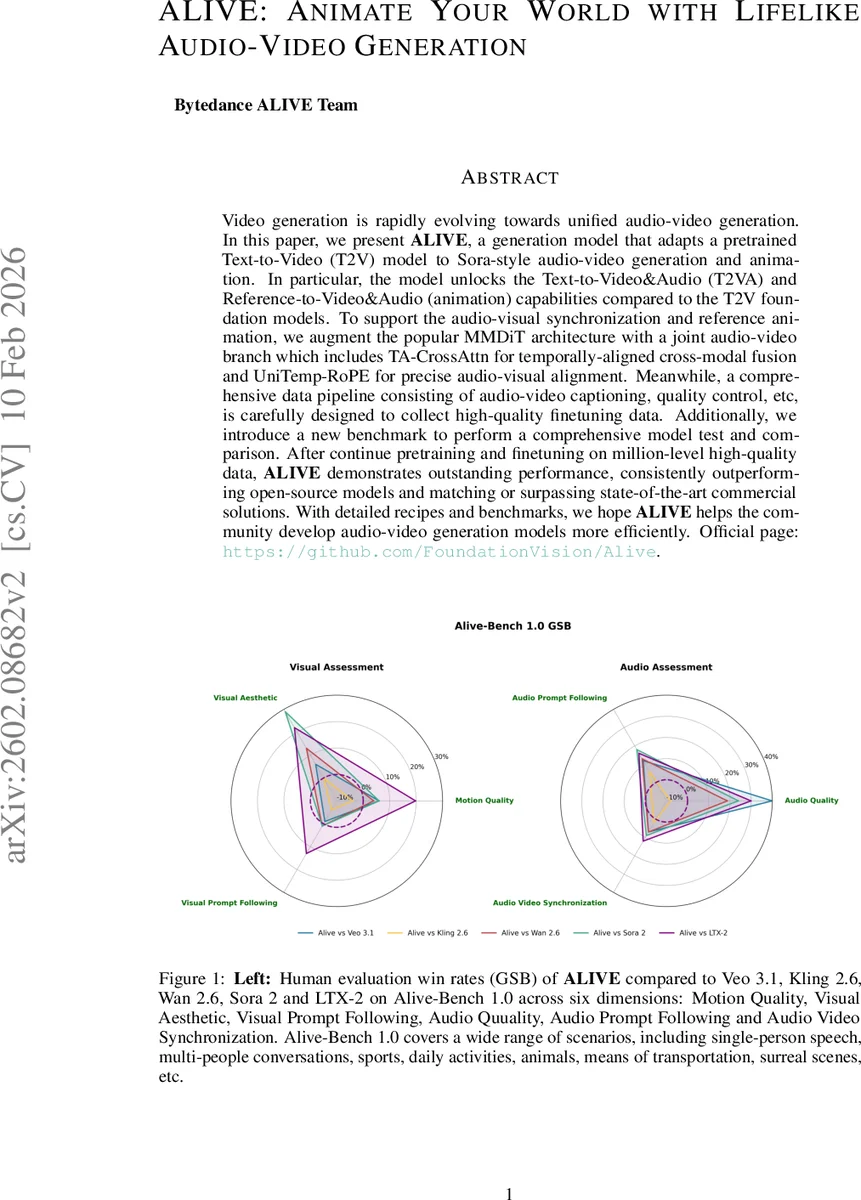
Video generation is rapidly evolving towards unified audio-video generation. In this paper, we present ALIVE, a generation model that adapts a pretrained Text-to-Video (T2V) model to Sora-style audio-video generation and animation. In particular, the model unlocks the Text-to-Video&Audio (T2VA) and Reference-to-Video&Audio (animation) capabilities compared to the T2V foundation models. To support the audio-visual synchronization and reference animation, we augment the popular MMDiT architecture with a joint audio-video branch which includes TA-CrossAttn for temporally-aligned cross-modal fusion and UniTemp-RoPE for precise audio-visual alignment. Meanwhile, a comprehensive data pipeline consisting of audio-video captioning, quality control, etc., is carefully designed to collect high-quality finetuning data. Additionally, we introduce a new benchmark to perform a comprehensive model test and comparison. After continue pretraining and finetuning on million-level high-quality data, ALIVE demonstrates outstanding performance, consistently outperforming open-source models and matching or surpassing state-of-the-art commercial solutions. With detailed recipes and benchmarks, we hope ALIVE helps the community develop audio-video generation models more efficiently. Official page: https://github.com/FoundationVision/Alive.
💡 Research Summary
ALIVE (Animate Your World with Lifelike Audio‑Video Generation) is a unified audio‑video generation framework that extends a pretrained text‑to‑video (T2V) foundation model to support simultaneous high‑fidelity video synthesis, synchronized speech, background sounds, and reference‑based animation. The authors build on the Waver 1.0 video diffusion transformer and introduce a “Dual Stream + Single Stream” architecture: a Video‑DiT processes visual latents while a newly designed Audio‑DiT processes compressed audio latents obtained via a Wave‑VAE encoder.
The core technical contribution lies in the temporally‑aligned cross‑modal interaction. Standard cross‑attention ignores physical time, which leads to poor lip‑sync especially in multi‑speaker scenarios. ALIVE solves this with two novel components: TA‑CrossAttn (Temporally‑Aligned Cross‑Attention) and UniTemp‑RoPE (Unified Temporal Rotary Positional Embedding). UniTemp‑RoPE maps video latent positions to continuous timestamps in the audio coordinate system, turning discrete token indices into real‑valued temporal positions that reflect the actual sampling rates of audio (e.g., 16 kHz) and video (e.g., 30 fps). TA‑CrossAttn then incorporates these continuous positions into the attention mechanism, and a timestep‑aware adaptive layer‑norm normalizes the cross‑modal signals before fusion, preventing one modality from dominating the other. In early (dual‑stream) layers the interaction is bidirectional, allowing video to guide audio onset timing and audio to guide visual texture; in later (single‑stream) layers it becomes unidirectional (audio → video) to preserve the already‑established audio structure while refining visual details.
Audio generation is conditioned on two separate textual streams. Speech transcripts are wrapped in a
To achieve 1080p output without prohibitive compute, ALIVE adopts a cascaded refinement strategy. A 480p base model is first trained jointly on audio‑video data. Then an Audio‑Video Refiner, initialized from the base, upscales video to 1080p while keeping the audio latents untouched. The refiner injects timestep‑dependent noise only into the video latent stream, leaving the Audio‑DiT frozen; this design preserves the synchronization learned at the base stage and avoids degradation of audio quality observed when the audio stream is also noised.
Data collection is a major focus. The authors construct a large‑scale pipeline that (1) filters raw video‑audio pairs for both visual and acoustic quality, (2) generates joint captions with structured tags, (3) corrects subject‑speech correspondence in multi‑person clips, and (4) applies hierarchical filtering and keyword balancing to obtain roughly one million high‑quality samples. This pipeline addresses the lack of public resources that simultaneously guarantee visual fidelity, audio fidelity, and cross‑modal coherence.
For evaluation, the paper introduces Alive‑Bench 1.0, a comprehensive benchmark covering six dimensions: Motion Quality, Visual Aesthetic, Visual Prompt Following, Audio Quality, Audio Prompt Following, and Audio‑Video Synchronization, with a total of 22 detailed metrics. Human preference studies (GSB) show ALIVE outperforming recent open‑source models such as VEO 3.1, Kling 2.6, and WAN 2.6, and matching or surpassing the commercial Sora 2 system across most axes.
A further contribution is the “Role‑Playing Animate” module. By treating reference images as persistent identity anchors and adding a temporal offset during conditioning, the model can animate a character across a sequence without the typical copy‑paste bias. Multi‑reference conditioning enables complex scenes where several characters retain consistent appearance while moving independently.
In summary, ALIVE advances unified audio‑video generation through (1) precise temporal alignment via UniTemp‑RoPE and TA‑CrossAttn, (2) a robust dual‑conditioning audio generation pipeline, (3) a scalable high‑resolution cascaded refiner, (4) a meticulously curated multi‑modal dataset, and (5) a new benchmark for systematic evaluation. Limitations include the current focus on short clips (5‑10 seconds), which may lead to high memory consumption for longer content, and slightly lower naturalness in multilingual, multi‑speaker speech compared to top commercial solutions. Nonetheless, ALIVE sets a new performance baseline and provides detailed recipes that can accelerate future research in lifelike audio‑video synthesis.
Comments & Academic Discussion
Loading comments...
Leave a Comment