Improving Data and Reward Design for Scientific Reasoning in Large Language Models
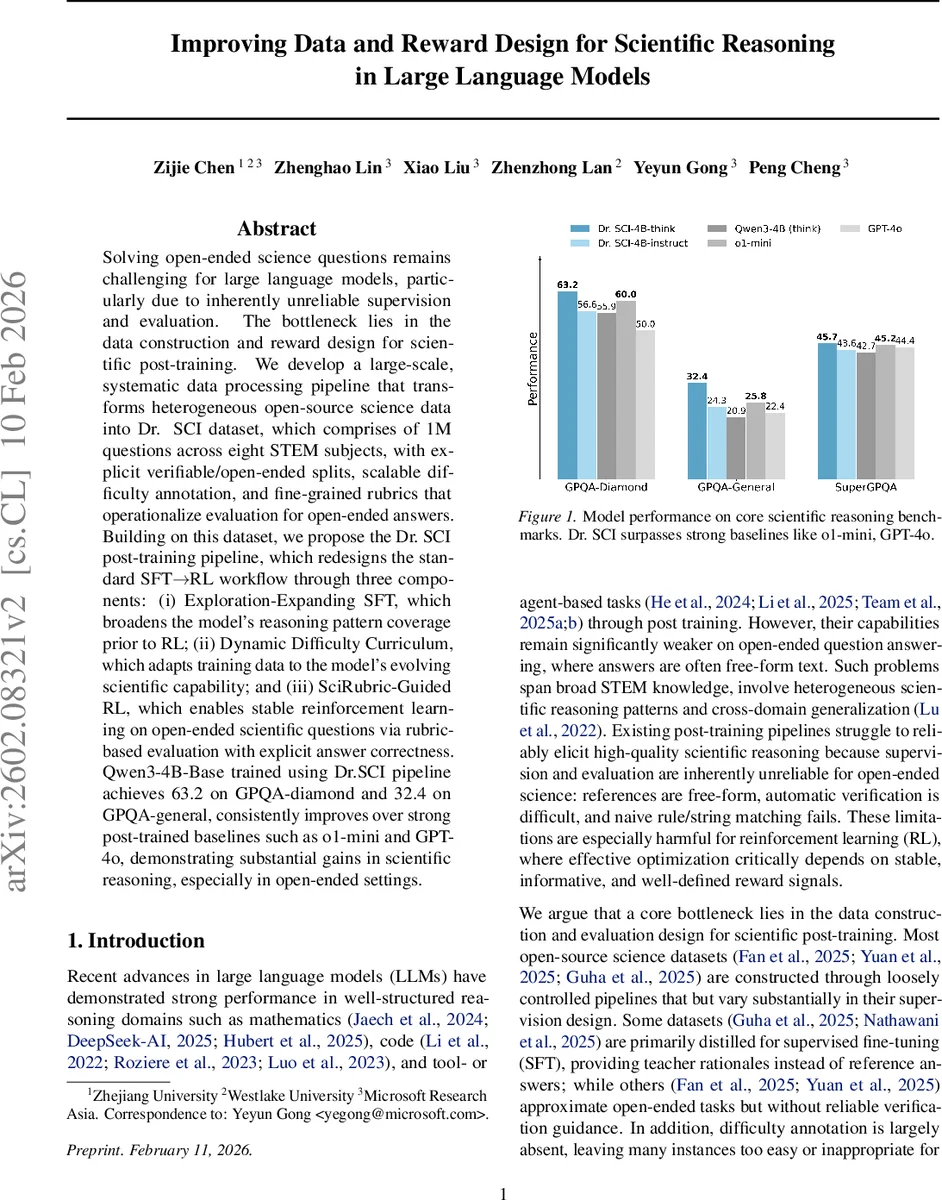
Solving open-ended science questions remains challenging for large language models, particularly due to inherently unreliable supervision and evaluation. The bottleneck lies in the data construction and reward design for scientific post-training. We develop a large-scale, systematic data processing pipeline that transforms heterogeneous open-source science data into Dr. SCI dataset, which comprises of 1M questions across eight STEM subjects, with explicit verifiable/open-ended splits, scalable difficulty annotation, and fine-grained rubrics that operationalize evaluation for open-ended answers. Building on this dataset, we propose the Dr. SCI post-training pipeline, which redesigns the standard SFT -> RL workflow through three components: (i) Exploration-Expanding SFT, which broadens the model’s reasoning pattern coverage prior to RL; (ii) Dynamic Difficulty Curriculum, which adapts training data to the model’s evolving scientific capability; and (iii) SciRubric-Guided RL, which enables stable reinforcement learning on open-ended scientific questions via rubric-based evaluation with explicit answer correctness. Qwen3-4B-Base trained using Dr. SCI pipeline achieves 63.2 on GPQA-diamond and 32.4 on GPQA-general, consistently improves over strong post-trained baselines such as o1-mini and GPT-4o, demonstrating substantial gains in scientific reasoning, especially in open-ended settings.
💡 Research Summary
The paper tackles the persistent difficulty that large language models (LLMs) face when answering open‑ended scientific questions, attributing the problem primarily to unreliable supervision and evaluation signals during post‑training. To remedy this, the authors construct a massive, high‑quality dataset called Dr. SCI that contains 1,006,701 scientific reasoning problems across eight STEM domains (mathematics, physics, chemistry, biology, medicine, computer science, economics, and general science). Each problem is explicitly labeled as either verifiable (answers can be checked automatically via numeric or multiple‑choice criteria) or open‑ended (requiring free‑form explanations). The dataset undergoes rigorous cleaning: removal of malformed entries, deduplication, conflict resolution, and exclusion of trivially easy items (those solved correctly by a strong baseline in all eight rollouts). Difficulty scores are estimated using a non‑thinking version of Qwen‑3‑32B, yielding a J‑shaped distribution that supplies a calibrated difficulty signal for curriculum learning.
For open‑ended items, the authors generate fine‑grained evaluation rubrics using an LLM (OpenAI o3). Each rubric consists of 7–20 atomic criteria, classified as Essential, Important, Optional, or Pitfall. On average, an open‑ended question receives 14.5 rubric items, with 4.3 marked Essential. These rubrics serve as the backbone for a novel reinforcement‑learning (RL) reward scheme.
Building on Dr. SCI, the paper proposes a three‑stage post‑training pipeline, Dr. SCI, that re‑designs the conventional supervised fine‑tuning (SFT) → RL workflow:
-
Exploration‑Expanding SFT – Instead of randomly sampling training data, the method greedily selects examples that maximize novel 4‑gram coverage, thereby exposing the model to a wide variety of reasoning patterns (e.g., derivations, experimental design, conceptual explanation). Candidate responses are generated from multiple open‑source models in both “thinking” and “instruction” modes, and a target size N is reached by iteratively adding the example that contributes the most previously unseen 4‑grams. This step yields two SFT policies (think‑style and instruct‑style) that together broaden the model’s exploratory capacity.
-
Dynamic Difficulty Curriculum – Each sample’s difficulty d(x)∈
Comments & Academic Discussion
Loading comments...
Leave a Comment