PersonaDual: Balancing Personalization and Objectivity via Adaptive Reasoning
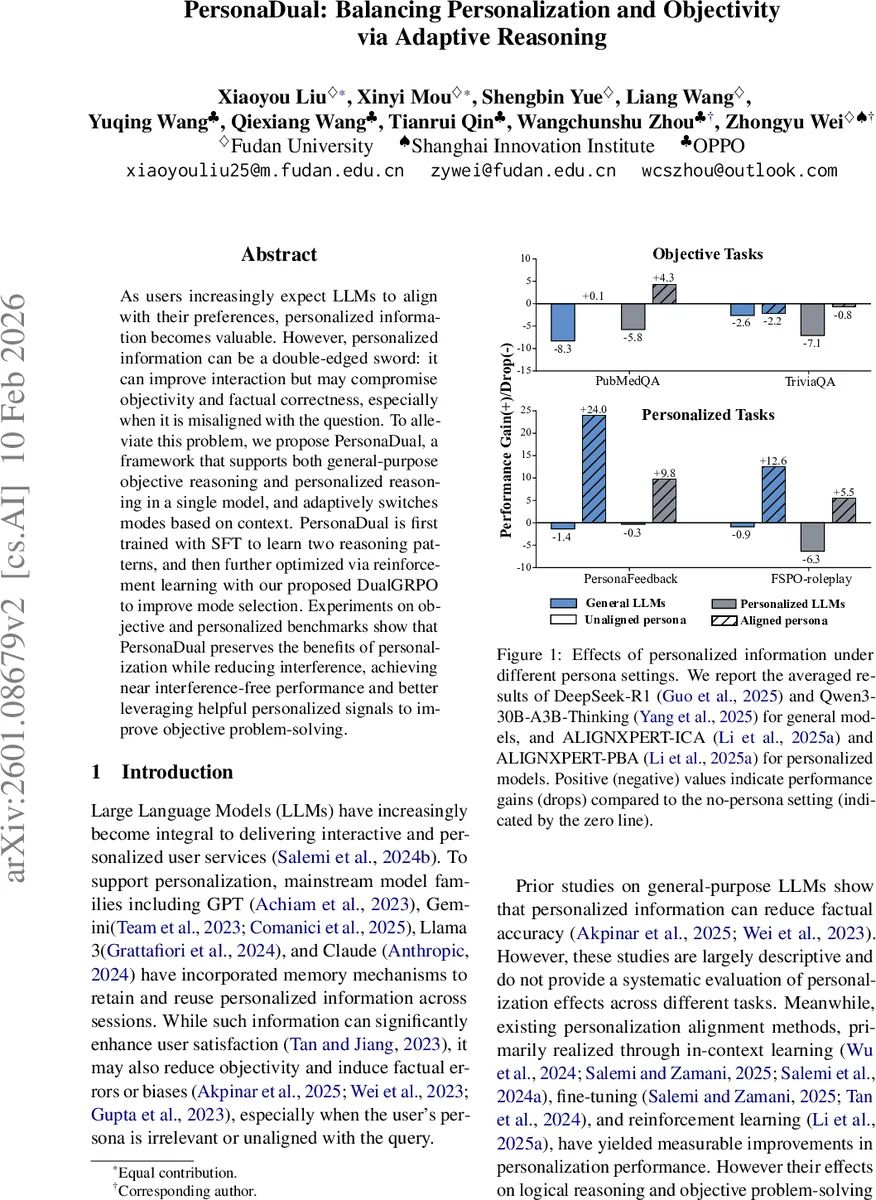
As users increasingly expect LLMs to align with their preferences, personalized information becomes valuable. However, personalized information can be a double-edged sword: it can improve interaction but may compromise objectivity and factual correctness, especially when it is misaligned with the question. To alleviate this problem, we propose PersonaDual, a framework that supports both general-purpose objective reasoning and personalized reasoning in a single model, and adaptively switches modes based on context. PersonaDual is first trained with SFT to learn two reasoning patterns, and then further optimized via reinforcement learning with our proposed DualGRPO to improve mode selection. Experiments on objective and personalized benchmarks show that PersonaDual preserves the benefits of personalization while reducing interference, achieving near interference-free performance and better leveraging helpful personalized signals to improve objective problem-solving.
💡 Research Summary
The paper tackles a fundamental tension in large language models (LLMs): the desire to personalize responses to individual users versus the need to preserve factual correctness and objectivity. Existing personalization techniques—such as in‑context prompting, fine‑tuning with user‑specific data, or reinforcement learning that aligns models to user preferences—have demonstrably increased user satisfaction but often incur an “alignment tax”: factual accuracy drops, hallucinations increase, and bias can be amplified when the supplied persona is irrelevant or misaligned with the task. The authors therefore propose PersonaDual, a unified framework that embeds two distinct reasoning modes within a single LLM and learns to switch between them adaptively based on the query and any available persona information.
Core Design
- Dual Modes – A general (objective) reasoning mode that ignores any persona data, and a personalized mode that explicitly incorporates persona attributes (occupation, interests, affective needs) throughout the reasoning chain.
- Mode Tokens – Two special prefix tokens, `
Comments & Academic Discussion
Loading comments...
Leave a Comment