ReForm: Reflective Autoformalization with Prospective Bounded Sequence Optimization
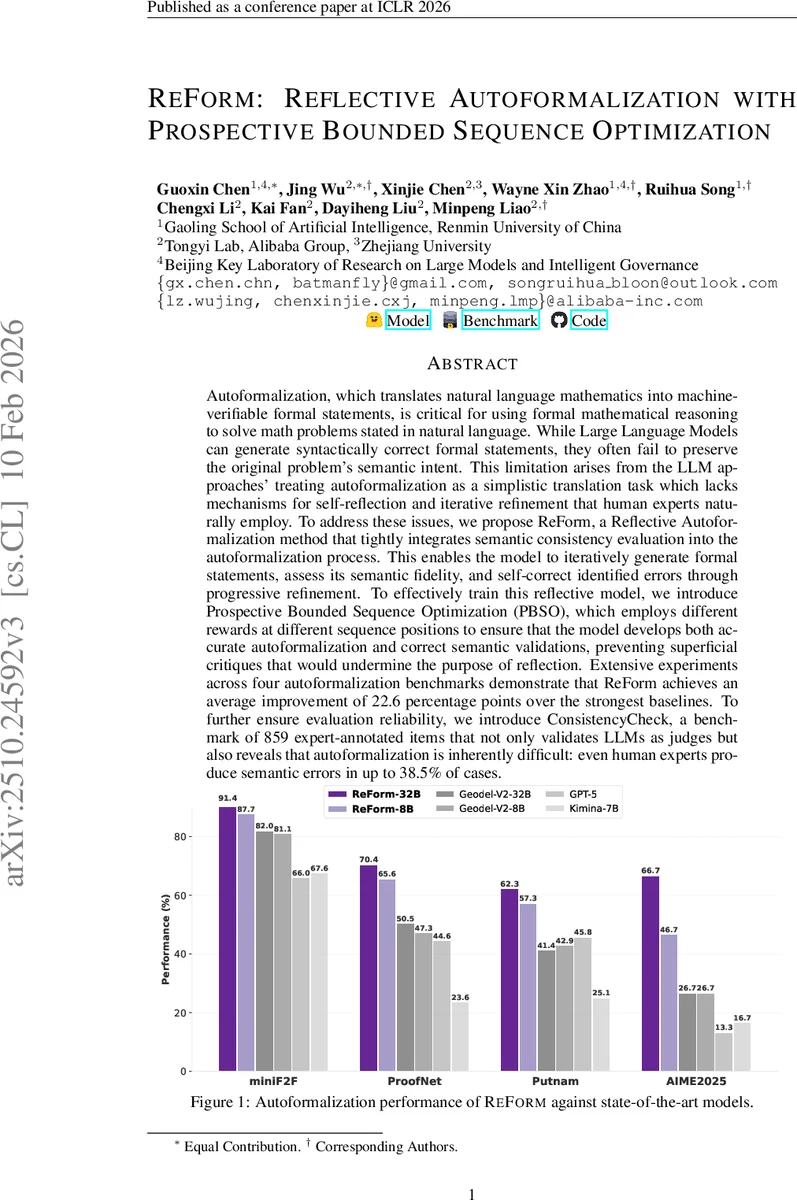
Autoformalization, which translates natural language mathematics into machine-verifiable formal statements, is critical for using formal mathematical reasoning to solve math problems stated in natural language. While Large Language Models can generate syntactically correct formal statements, they often fail to preserve the original problem’s semantic intent. This limitation arises from the LLM approaches’ treating autoformalization as a simplistic translation task which lacks mechanisms for self-reflection and iterative refinement that human experts naturally employ. To address these issues, we propose ReForm, a Reflective Autoformalization method that tightly integrates semantic consistency evaluation into the autoformalization process. This enables the model to iteratively generate formal statements, assess its semantic fidelity, and self-correct identified errors through progressive refinement. To effectively train this reflective model, we introduce Prospective Bounded Sequence Optimization (PBSO), which employs different rewards at different sequence positions to ensure that the model develops both accurate autoformalization and correct semantic validations, preventing superficial critiques that would undermine the purpose of reflection. Extensive experiments across four autoformalization benchmarks demonstrate that ReForm achieves an average improvement of 22.6 percentage points over the strongest baselines. To further ensure evaluation reliability, we introduce ConsistencyCheck, a benchmark of 859 expert-annotated items that not only validates LLMs as judges but also reveals that autoformalization is inherently difficult: even human experts produce semantic errors in up to 38.5% of cases.
💡 Research Summary
The paper “ReForm: Reflective Autoformalization with Prospective Bounded Sequence Optimization” tackles a central bottleneck in the pipeline of formal mathematical reasoning: translating natural‑language problems into machine‑verifiable formal statements (autoformalization) while preserving the original semantic intent. Existing large language models (LLMs) are capable of producing syntactically correct Lean or Coq code, but they frequently misinterpret quantifier scopes, overlook implicit constraints, or otherwise diverge from the problem’s meaning. The authors argue that this failure stems not only from data quality but from the prevailing one‑pass generation paradigm, which lacks any mechanism for self‑reflection or iterative correction.
Reflective Autoformalization Paradigm
ReForm reconceptualizes autoformalization as an iterative self‑correction loop that mirrors how human experts work. Given a natural‑language question Q, the model maintains a history Hₜ of all previous formal statements S₁…Sₜ₋₁ and their associated critiques C₁…Cₜ₋₁. At each iteration t it (1) generates a new formal statement Sₜ conditioned on Q and Hₜ, and (2) immediately produces a semantic critique Cₜ that evaluates the fidelity of Sₜ to Q. The critique pinpoints concrete errors (e.g., “the universal quantifier should range over ℕ, not ℤ”). The next iteration uses this feedback as part of its context, allowing the model to refine the statement. This process is implemented as a single continuous autoregressive generation: the tokens for Sₜ, then Cₜ, then Sₜ₊₁, etc., are emitted in one forward pass, preserving computational efficiency while enabling dynamic, intra‑sequence self‑validation.
Prospective Bounded Sequence Optimization (PBSO)
Training a model to execute this loop requires simultaneous optimization of two heterogeneous objectives: (a) a task reward r_task that is granted only when the final statement passes the Lean compiler and a semantic consistency check (implemented via an LLM judge), and (b) an auxiliary reward rₜ^aux that rewards each intermediate critique for being faithful—i.e., correctly identifying all existing semantic mismatches without false positives or premature termination. Conventional reinforcement learning methods handle a single terminal reward, which would leave the critique learning signal absent and cause the model to generate superficial or hallucinated critiques. PBSO introduces a “prospective bounded return”: for each token position i it computes a discounted sum of future rewards G_i = Σ_{j≥i} γ^{j‑i} r_j, then clips G_i to the predefined reward range. This clipping prevents unbounded accumulation and stabilizes training, while the discount factor γ ensures that earlier steps receive credit for enabling later successes. Consequently, the model learns to produce high‑quality critiques that genuinely guide subsequent refinements, and simultaneously learns to translate those critiques into correct formal statements.
Experimental Evaluation
The authors evaluate ReForm on four prominent autoformalization benchmarks: miniF2F, ProofNet, Putnam, and AIME2025. Two model sizes are trained—ReForm‑32B and ReForm‑8B—using PBSO on top of strong base LLMs. Baselines include Geodel‑V2‑32B, Geodel‑V2‑8B, GPT‑5, and Kimina‑7B. Across all datasets, ReForm achieves an average improvement of 22.6 percentage points in combined syntactic‑and‑semantic accuracy. For example, on ProofNet the best baseline reaches 70.4% semantic correctness, while ReForm‑32B attains 87.7%.
To address the reliability of LLM‑based evaluation, the authors construct ConsistencyCheck, a benchmark of 859 expert‑annotated items covering miniF2F and ProofNet. Human experts themselves make semantic errors in 16.4% of miniF2F and 38.5% of ProofNet formalizations, highlighting the intrinsic difficulty of the task. LLM judges achieve 85.8% accuracy on ConsistencyCheck, which the authors deem sufficient for comparative evaluation. Importantly, ReForm’s gains far exceed the noise floor introduced by imperfect judges, confirming the robustness of the reported improvements.
Ablation and Analysis
Ablation studies show that removing the auxiliary critique reward drops final semantic accuracy by roughly 12 pp, confirming that accurate self‑validation is essential. Varying the discount factor γ demonstrates that values around 0.95 balance credit assignment without destabilizing training. The authors also measure inference overhead: the reflective loop adds about 1.3× latency compared to a pure one‑pass model, but memory consumption remains comparable because the entire process is a single autoregressive pass.
Limitations and Future Work
The current design relies on the same LLM to generate both statements and critiques, which could propagate critique errors. Future work may incorporate a dedicated, smaller verification model or external symbolic tools to improve critique reliability. Extending PBSO to more than two reward signals (e.g., multi‑step theorem proving, proof sketch generation) is another promising direction. Finally, expanding ConsistencyCheck to a broader range of mathematical domains would provide a more comprehensive assessment of semantic fidelity.
Conclusion
ReForm introduces a novel reflective autoformalization paradigm that interleaves generation with semantic self‑validation, and a new reinforcement learning algorithm (PBSO) that can jointly optimize heterogeneous rewards across a sequence. Empirically, this combination yields substantial gains over state‑of‑the‑art one‑pass models, while also providing a rigorous benchmark (ConsistencyCheck) to evaluate semantic consistency. The work demonstrates that embedding human‑like iterative review into LLMs can markedly improve the fidelity of automatically generated formal mathematics, opening avenues for more reliable integration of LLMs into formal reasoning pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment