Long-Term Mapping of the Douro River Plume with Multi-Agent Reinforcement Learning
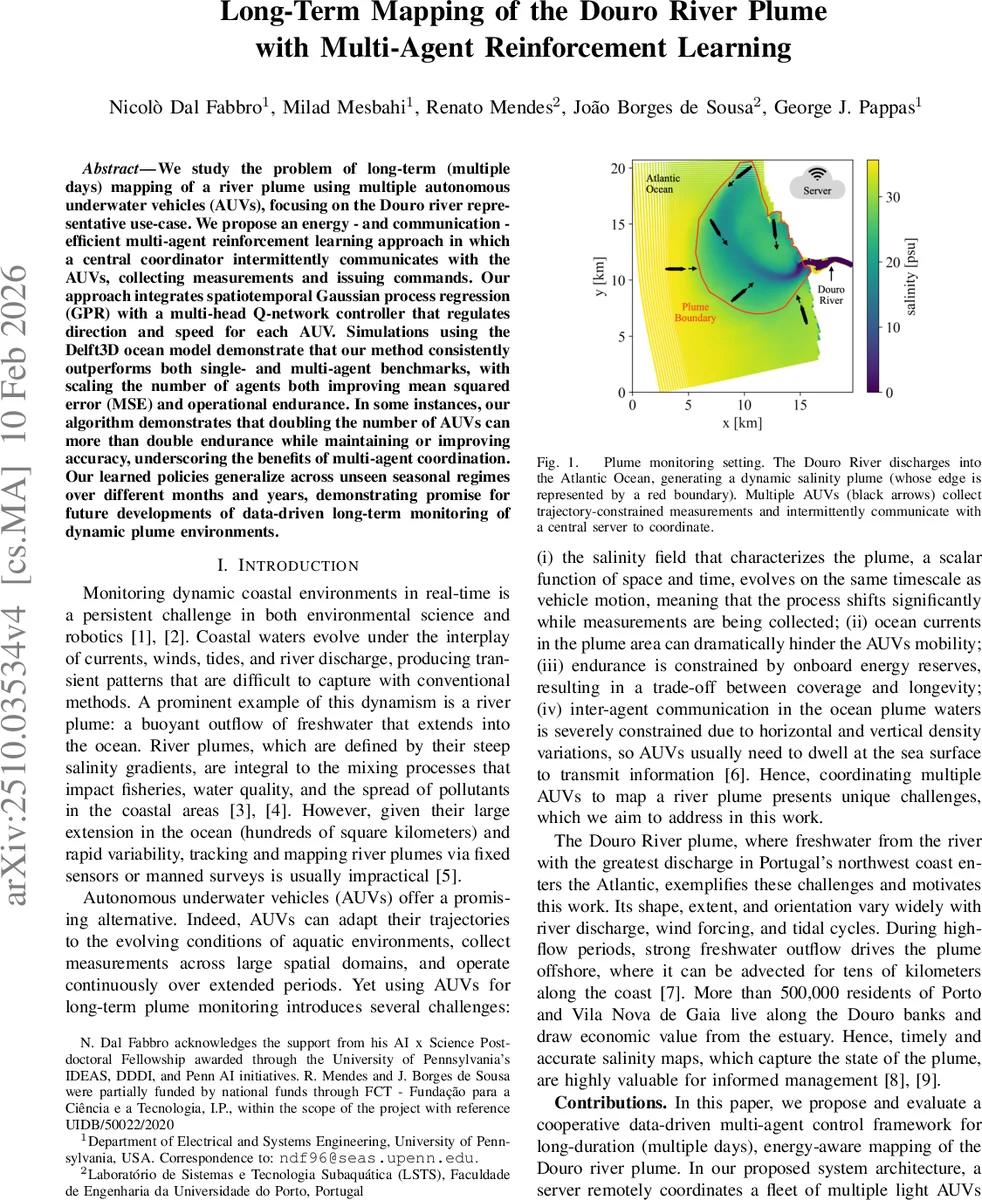
We study the problem of long-term (multiple days) mapping of a river plume using multiple autonomous underwater vehicles (AUVs), focusing on the Douro river representative use-case. We propose an energy - and communication - efficient multi-agent reinforcement learning approach in which a central coordinator intermittently communicates with the AUVs, collecting measurements and issuing commands. Our approach integrates spatiotemporal Gaussian process regression (GPR) with a multi-head Q-network controller that regulates direction and speed for each AUV. Simulations using the Delft3D ocean model demonstrate that our method consistently outperforms both single- and multi-agent benchmarks, with scaling the number of agents both improving mean squared error (MSE) and operational endurance. In some instances, our algorithm demonstrates that doubling the number of AUVs can more than double endurance while maintaining or improving accuracy, underscoring the benefits of multi-agent coordination. Our learned policies generalize across unseen seasonal regimes over different months and years, demonstrating promise for future developments of data-driven long-term monitoring of dynamic plume environments.
💡 Research Summary
The paper tackles the challenging problem of long‑term (multi‑day) mapping of a dynamic river plume using a fleet of autonomous underwater vehicles (AUVs). Focusing on the Douro River plume as a realistic case study, the authors develop an energy‑ and communication‑efficient multi‑agent reinforcement learning (MARL) framework that relies on intermittent, low‑bandwidth communication with a central server. The core of the solution combines a spatiotemporal Gaussian Process Regression (GPR) estimator with a multi‑head Deep Q‑Network (DQN) controller that independently selects heading direction and cruise speed for each AUV.
Key system design points:
- Intermittent communication – Every 30 minutes all AUVs surface, upload a small batch of recent salinity measurements (typically 5–10 space‑time points, < 200 bytes), and receive new motion commands. This keeps radio usage minimal while still allowing the server to maintain a global view of the plume.
- State construction – The server updates the GPR model with all received data, producing a posterior mean and variance field for salinity at the current time slot. These fields, together with each vehicle’s recent trajectory and the measured wind vector, are encoded into per‑agent state embeddings.
- Multi‑head DQN – One head outputs a discrete heading (8 possible directions) and another outputs a discrete speed (high speed = 1 m s⁻¹, low speed = 0.4 m s⁻¹). Decoupling direction and speed reduces the size of the action space and enables the network to learn nuanced trade‑offs between exploration (fast motion) and energy conservation (slow motion).
- Reward design – The reward balances two competing objectives: (a) reduction of the mean‑squared error (MSE) between the GPR estimate and the true salinity field, and (b) propulsion energy consumption, modeled as proportional to the cube of the chosen speed. This encourages the policy to accelerate when rapid plume changes demand fresh data, and to slow down when the plume is relatively stable.
The authors evaluate the approach using high‑fidelity simulations built on the Delft3D ocean model, which incorporates realistic bathymetry, tidal forcing, wind, and river discharge for the Douro estuary. Experiments compare three fleet sizes (3, 6, and 9 AUVs) against several baselines: (i) a lawn‑mower coverage pattern, (ii) a single‑agent DQN, and (iii) a multi‑agent heuristic that follows the plume front without learning. Results show that the proposed MARL method consistently achieves lower MSE (up to 30 % improvement) and significantly longer mission endurance—doubling the number of AUVs can more than double the operational lifetime because the low‑speed mode reduces energy consumption by a factor of eight. Importantly, policies trained on data from specific months generalize to unseen seasonal conditions (different months and years), demonstrating robustness to variations in wind, tide, and discharge.
The paper’s contributions can be summarized as follows:
- Problem formulation that explicitly incorporates plume dynamics, vehicle kinematics, ocean currents, and communication constraints into an online optimization problem.
- Algorithmic integration of GPR for real‑time field estimation with a multi‑head DQN that learns both direction and speed decisions under an energy‑aware reward.
- System architecture that offloads heavy computation to a cloud server, preserving AUV battery for propulsion and sensing, while using ultra‑low‑overhead uplink/downlink messages.
- Extensive validation on a realistic ocean model, showing superior accuracy, scalability, and endurance compared to existing single‑agent and heuristic multi‑agent approaches.
Future work suggested includes field trials with actual light AUVs, incorporation of predictive ocean‑current models to further exploit favorable flow patterns, and extension of the framework to other dynamic marine monitoring tasks such as pollutant spill tracking, harmful algal bloom detection, or acoustic mapping. Overall, the study presents a compelling case that data‑driven, multi‑agent reinforcement learning can overcome the physical and operational challenges of long‑term plume monitoring, offering a scalable and energy‑efficient solution for coastal environmental sensing.
Comments & Academic Discussion
Loading comments...
Leave a Comment