$n$-Musketeers: Reinforcement Learning Shapes Collaboration Among Language Models
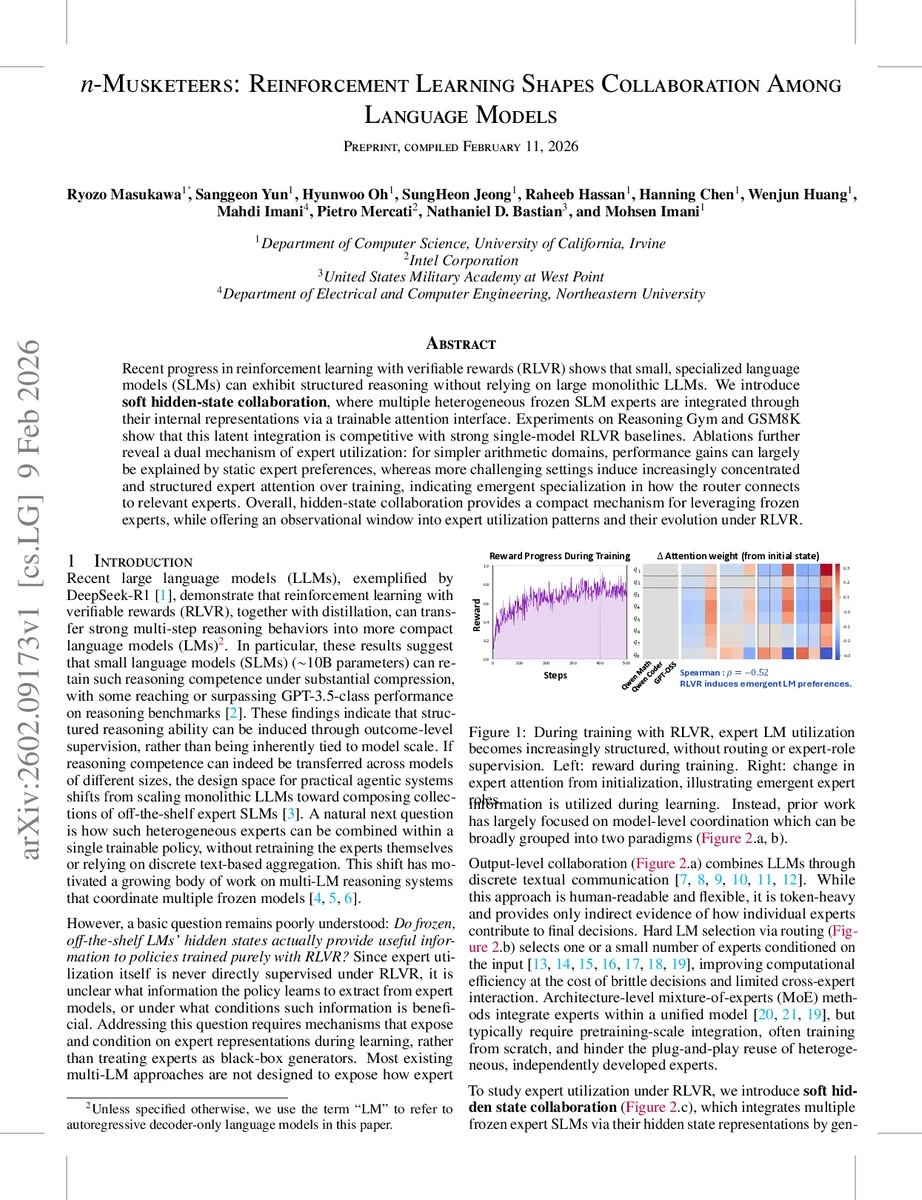
Recent progress in reinforcement learning with verifiable rewards (RLVR) shows that small, specialized language models (SLMs) can exhibit structured reasoning without relying on large monolithic LLMs. We introduce soft hidden-state collaboration, where multiple heterogeneous frozen SLM experts are integrated through their internal representations via a trainable attention interface. Experiments on Reasoning Gym and GSM8K show that this latent integration is competitive with strong single-model RLVR baselines. Ablations further reveal a dual mechanism of expert utilization: for simpler arithmetic domains, performance gains can largely be explained by static expert preferences, whereas more challenging settings induce increasingly concentrated and structured expert attention over training, indicating emergent specialization in how the router connects to relevant experts. Overall, hidden-state collaboration provides a compact mechanism for leveraging frozen experts, while offering an observational window into expert utilization patterns and their evolution under RLVR.
💡 Research Summary
The paper “n‑Musketeers: Reinforcement Learning Shapes Collaboration Among Language Models” investigates how multiple frozen, off‑the‑shelf small language models (SLMs) can be combined under a reinforcement‑learning‑with‑verifiable‑rewards (RLVR) regime without retraining the experts themselves. The authors argue that recent work shows small specialized models can acquire structured reasoning abilities through outcome‑level supervision, suggesting a shift from scaling monolithic LLMs to composing collections of expert SLMs. However, existing multi‑LM approaches either rely on token‑heavy textual communication, hard routing that limits cross‑expert interaction, or mixture‑of‑experts architectures that require joint pre‑training.
To fill this gap, the authors propose “soft hidden‑state collaboration,” a latent‑interface method that extracts the final‑layer hidden states from each frozen expert, aligns them via expert‑specific linear projections, and aggregates them with a Perceiver‑style cross‑attention bottleneck. A small set of trainable latent query vectors (the “bottleneck”) attends to the aligned expert representations, producing a fixed‑size context tensor C. This context is injected as a prefix to a trainable policy model πθ, which is then optimized with RLVR (using GRPO, PPO, or related algorithms). Because the context tokens are not supervised at the token level, the only learning signal comes from the task‑level reward r(x, y), allowing the system to discover how to use expert information end‑to‑end.
Experiments are conducted on Reasoning Gym and GSM8K, covering a range of arithmetic, algebraic, and logical tasks. The soft hidden‑state approach consistently outperforms strong single‑model RLVR baselines, achieving up to a 22.9 percentage‑point boost in the best settings. Detailed ablations explore (i) the number of latent queries (m), (ii) pooling strategies (last‑token vs mean), (iii) initialization of the output projection, and (iv) the composition of the expert pool (homogeneous vs heterogeneous models, different tokenizers). Results show that (a) a modest number of queries (m≈8) balances expressivity and computational cost, (b) last‑token pooling works best for causal models, and (c) initializing the output projection near zero stabilizes early training.
A key insight emerges from the analysis of attention patterns over training. For simple arithmetic domains, performance gains can be largely explained by static expert preferences: certain experts receive consistently higher attention weights, and the policy learns to rely on them throughout training. In contrast, for more challenging reasoning tasks, the attention distribution becomes increasingly concentrated and structured as training progresses. Specific latent queries begin to focus on particular experts, indicating emergent specialization and “role assignment” without any explicit routing supervision. Visualizations (Figure 1) illustrate this transition from uniform attention at initialization to sharply peaked attention aligned with reward improvements.
Further probing reveals that much of the performance benefit stems from the latent‑prompting effect of the learned context tokens rather than fine‑grained reasoning traces extracted from the experts. In other words, the Perceiver adapter serves primarily as a principled, trainable interface that makes expert utilization observable, while the underlying hidden states provide auxiliary signals that the RLVR policy can exploit.
The paper’s contributions are threefold: (1) introducing a plug‑and‑play hidden‑state collaboration framework that exposes SLM utilization dynamics under outcome‑level supervision, (2) empirically demonstrating that frozen expert hidden states contain actionable reasoning cues that improve RLVR performance, and (3) characterizing when and how these cues help, degrade, or become irrelevant through controlled experiments.
Overall, the work shows that RLVR can automatically shape how a policy attends to multiple frozen experts, leading to emergent, task‑dependent expert roles without any hard routing or textual aggregation. This opens a promising avenue for building modular, efficient reasoning agents that combine heterogeneous specialist models through lightweight latent interfaces, offering both performance gains and interpretability of expert usage.
Comments & Academic Discussion
Loading comments...
Leave a Comment