Next-Gen CAPTCHAs: Leveraging the Cognitive Gap for Scalable and Diverse GUI-Agent Defense
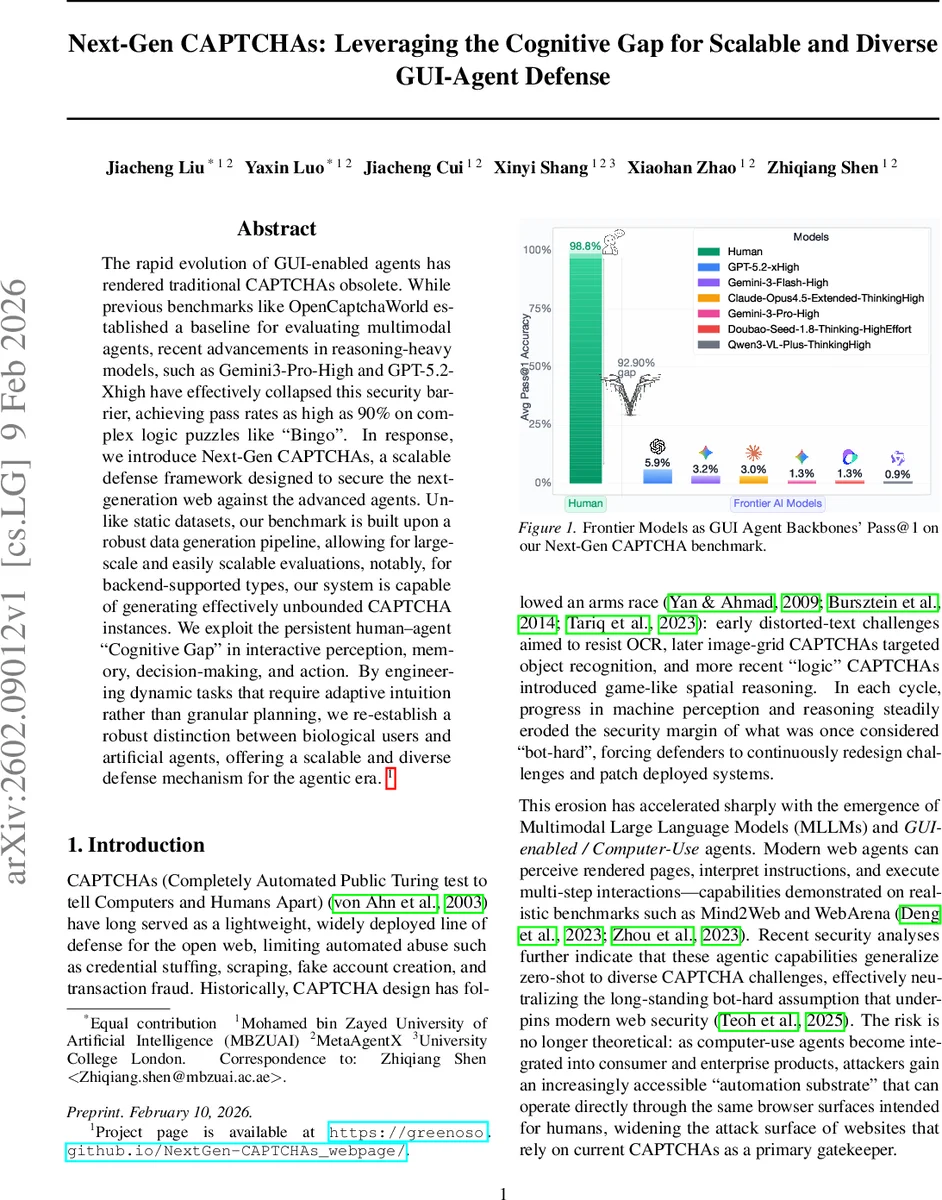
The rapid evolution of GUI-enabled agents has rendered traditional CAPTCHAs obsolete. While previous benchmarks like OpenCaptchaWorld established a baseline for evaluating multimodal agents, recent advancements in reasoning-heavy models, such as Gemini3-Pro-High and GPT-5.2-Xhigh have effectively collapsed this security barrier, achieving pass rates as high as 90% on complex logic puzzles like “Bingo”. In response, we introduce Next-Gen CAPTCHAs, a scalable defense framework designed to secure the next-generation web against the advanced agents. Unlike static datasets, our benchmark is built upon a robust data generation pipeline, allowing for large-scale and easily scalable evaluations, notably, for backend-supported types, our system is capable of generating effectively unbounded CAPTCHA instances. We exploit the persistent human-agent “Cognitive Gap” in interactive perception, memory, decision-making, and action. By engineering dynamic tasks that require adaptive intuition rather than granular planning, we re-establish a robust distinction between biological users and artificial agents, offering a scalable and diverse defense mechanism for the agentic era.
💡 Research Summary
The paper opens by documenting how modern GUI‑enabled agents have effectively nullified traditional CAPTCHA defenses. Early CAPTCHAs relied on distorted text to thwart OCR, later image‑grid challenges targeted object recognition, and recent “logic” CAPTCHAs introduced spatial reasoning. Each of these layers was successively broken by advances in computer vision (CNNs, Vision Transformers) and, most recently, by Multimodal Large Language Models (MLLMs) such as Gemini‑3‑Pro‑High and GPT‑5.2‑Xhigh, which achieve 90%+ Pass@1 on complex puzzles like “Bingo”. Recognizing that the security margin has collapsed, the authors turn to a persistent “cognitive gap” between humans and current agents. Humans excel at rapid, intuitive pattern recognition and can act under partial observation with minimal deliberation, whereas state‑of‑the‑art agents still struggle with precise visual grounding, maintaining latent task state over time, and executing low‑level UI actions (especially drag‑and‑drop or timed interactions). Existing CAPTCHAs are short, decomposable workflows (screenshot → parse → candidate search → click) that fit neatly into an agent’s perception‑thinking‑action loop, allowing agents to solve them reliably.
To exploit the human‑agent gap, the authors propose Next‑Gen CAPTCHAs, a scalable defense framework that generates dynamic, intuition‑driven challenges. The core is an automatic generation pipeline that can synthesize virtually unlimited instances across 27 newly designed CAPTCHA families, each paired with a rule‑based, automatically verifiable answer. Only two families involve vision‑language tasks; the rest are procedurally generated with deterministic solutions, eliminating the need for human annotation. Example families include Red Dot (timed click), Mirror Multi‑Script, Occluded Pattern Counting, 3D Viewpoint, Dynamic Jigsaw, and many others that require robust grounding, memory, and complex action primitives.
For evaluation, the authors curate a benchmark of 519 vision‑language puzzles sampled from the 27 families, plus a lightweight subset (5 puzzles per family) for low‑budget testing. They benchmark a variety of GUI agents—Browser‑Use (the primary reference), Claude‑Cowork, and CrewAI—under realistic closed‑API settings on live web pages. Human participants achieve near‑ceiling performance (92.9% pass rate) with average completion times of 4–6 seconds, confirming usability. In stark contrast, high‑reasoning MLLMs achieve single‑digit Pass@1 rates, many near 0%, despite having access to the same visual information and tool use. Correlation analysis shows that for legacy CAPTCHAs, success correlates positively with interaction length and negatively with reasoning token usage, reflecting the decomposable nature of those tasks. For Next‑Gen CAPTCHAs, correlations are essentially zero, indicating that longer deliberation does not improve agent success; failures stem from mis‑grounding UI affordances or skipping required actions (e.g., failing to drag‑and‑drop in a jigsaw).
The paper also presents a formal extended POMDP model of the CAPTCHA‑solving process, highlighting the observation‑memory‑decision‑action loop and the cost of internal deliberation. By designing tasks that amplify brittleness in any of these components, the framework deliberately creates failure modes for agents while remaining intuitive for humans.
Finally, the authors release an open‑source real‑web evaluation platform that standardizes browser interaction logging and can accommodate any GUI‑enabled MLLM. They argue that the primary contribution is not the benchmark itself but the deployable, continuously generative defense system it samples from. The system offers scalable diversity, controllable difficulty, and automatic verification, providing a sustainable path forward for web security in the era of autonomous agents.
In summary, the work identifies the collapse of traditional CAPTCHA security, articulates a human‑agent cognitive gap, and delivers a procedurally generated, agent‑defensive CAPTCHA suite together with an evaluation ecosystem. The results demonstrate a substantial human‑agent performance gap and suggest that leveraging interactive intuition rather than static difficulty is a promising direction for future web‑scale defenses.
Comments & Academic Discussion
Loading comments...
Leave a Comment