Next Concept Prediction in Discrete Latent Space Leads to Stronger Language Models
We propose Next Concept Prediction (NCP), a generative pretraining paradigm built on top of Next Token Prediction (NTP). NCP predicts discrete concepts that span multiple tokens, thereby forming a more challenging pretraining objective. Our model, ConceptLM, quantizes hidden states using Vector Quantization and constructs a concept vocabulary. It leverages both NCP and NTP to drive parameter updates and generates a concept to guide the generation of the following tokens. We train ConceptLM from scratch at scales ranging from 70M to 1.5B parameters with up to 300B training data, including Pythia and GPT-2 backbones. Results on 13 benchmarks show that NCP yields consistent performance gains over traditional token-level models. Furthermore, continual pretraining experiments on an 8B-parameter Llama model indicate that NCP can further improve an NTP-trained model. Our analysis suggests that NCP leads to more powerful language models by introducing a harder pretraining task, providing a promising path toward better language modeling.
💡 Research Summary
The paper introduces Next Concept Prediction (NCP), a novel pre‑training objective that augments the traditional next‑token prediction (NTP) used in large language models (LLMs). While NTP asks a model to predict a single token given its left context, NCP asks the model to predict a concept that spans multiple tokens. A concept is a discrete latent representation derived from the model’s continuous hidden states via vector quantization (VQ). By learning to predict these higher‑level symbols, the model faces a harder, more informative learning task, which the authors argue leads to better long‑range dependency modeling and more efficient scaling.
Architecture (ConceptLM)
- Token‑level Encoder – Converts the input token sequence into continuous hidden states h.
- Concept‑level Module –
- Compression: Mean‑pooling over blocks of k tokens reduces the sequence length from T to M = T/k.
- Vector Quantization: Each compressed hidden vector c is split into S independent segments. Every segment is quantized with its own codebook of size N (the paper uses N = 64). This yields a discrete concept vector ĉ formed by concatenating the selected codebook entries.
- Prediction Heads: For each segment a separate linear head outputs logits over the N codebook entries. The softmax distribution is used as a weighted sum of the entries, keeping the whole pipeline differentiable.
- Token‑level Decoder – The predicted concept ĉ is broadcast k times, shifted by k‑1 positions to avoid leakage, and added element‑wise to the token‑level hidden states. The decoder then predicts the next token using the usual language‑modeling cross‑entropy loss.
Training Objectives
- L_VQ – Reconstruction loss for the VQ module, using stop‑gradient to keep quantization from directly constraining the encoder.
- L_NCP – Mean‑squared error between the predicted continuous concept ĉ and the ground‑truth compressed hidden state c.
- L_NTP – Standard next‑token cross‑entropy computed on the merged hidden representation ĥ (token hidden + broadcast concept). The total loss is L = L_NTP + L_NCP + L_VQ.
Experiments
The authors train models from scratch on two popular backbones:
- GPT‑2 series (124 M to 1.5 B parameters) on the OpenWebText corpus (≈8 B tokens).
- Pythia series (70 M to 410 M parameters) on the Pile (≈300 B tokens).
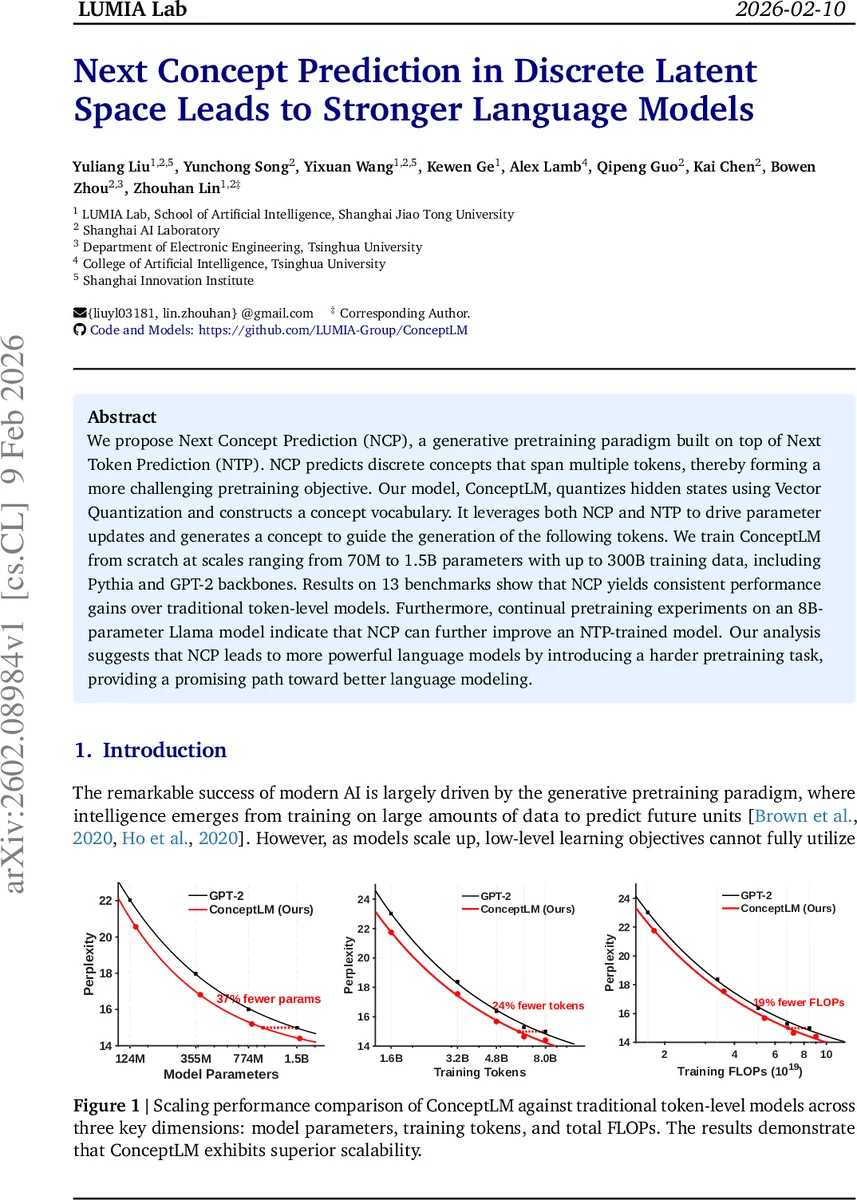
They evaluate on 13 downstream benchmarks covering language modeling (WikiText, OpenWebText), zero‑shot reasoning (LAMBADA, ARC‑Easy/Challenge, Winogrande, PIQA, HellaSwag, SciQ, RACE) and report both perplexity and accuracy. Across all scales, ConceptLM consistently outperforms the token‑only baseline and a parameter‑matched baseline (adding two extra token layers). For example, the 124 M GPT‑2 model improves from 22.04 perplexity (baseline) to 20.56 (ConceptLM) and from 40.86 % to 51.83 % on LAMBADA‑Standard. Gains become larger as model size grows, indicating better scaling behavior.
A continual‑pretraining experiment is performed on an 8 B Llama‑3.1 model using only 9.6 B additional tokens from a long‑context dataset (LongCtxEng). After NCP‑augmented pretraining, the model achieves an average 0.4‑point boost (≈2 % relative) across four benchmarks, demonstrating that NCP can enhance already‑trained LLMs.
Analysis
- Long‑range Dependency – Because a concept aggregates k tokens, predicting the next concept forces the encoder to capture information spanning at least k tokens, encouraging the model to learn broader context.
- Discrete Latent Space Efficiency – The product quantization scheme (S segments × N entries) yields an effective vocabulary size of N^S while keeping each codebook small, allowing rich representation without large memory overhead.
- Scaling Efficiency – Plots in the paper show that for a given FLOP budget, ConceptLM achieves lower perplexity than token‑only models, suggesting that the harder NCP objective yields better utilization of compute.
- Ablations – Removing L_NCP degrades performance, confirming that the concept‑level loss is essential rather than a side effect of VQ. Varying k and S shows a trade‑off: larger k improves long‑range modeling but can increase quantization error; more segments S improve expressivity but add parameter overhead.
Limitations & Future Work
- Hyper‑parameter Sensitivity – The compression factor k and segment count S must be tuned per model size and dataset; suboptimal choices can hurt performance.
- Codebook Maintenance – VQ introduces additional training dynamics (codebook updates) that may complicate large‑scale distributed training.
- Error Propagation – Incorrect concept predictions could misguide token generation; the authors mitigate this with a soft‑weighted sum and a shift to prevent leakage, but further robustness studies are needed.
- Generality – Experiments are limited to English text; extending NCP to multilingual or multimodal data (e.g., vision‑language) is an open direction.
Conclusion
Next Concept Prediction enriches the pre‑training objective by introducing a discrete, multi‑token latent space. By jointly optimizing NCP and the classic next‑token loss, ConceptLM learns stronger, more globally aware representations, scales more efficiently, and yields consistent downstream gains. The work opens a promising avenue for future LLM research: moving beyond token‑level prediction toward hierarchical, concept‑level learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment