StretchTime: Adaptive Time Series Forecasting via Symplectic Attention
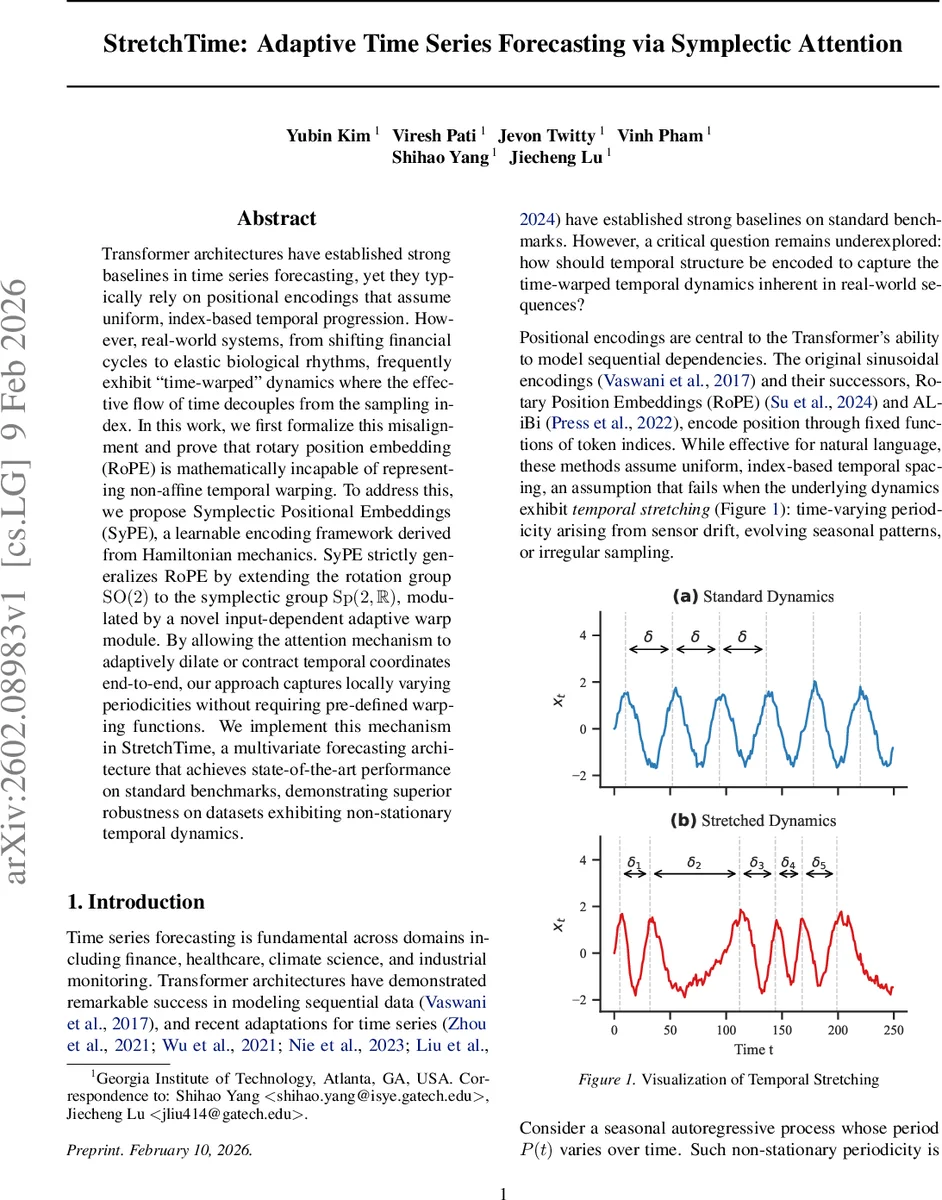
Transformer architectures have established strong baselines in time series forecasting, yet they typically rely on positional encodings that assume uniform, index-based temporal progression. However, real-world systems, from shifting financial cycles to elastic biological rhythms, frequently exhibit “time-warped” dynamics where the effective flow of time decouples from the sampling index. In this work, we first formalize this misalignment and prove that rotary position embedding (RoPE) is mathematically incapable of representing non-affine temporal warping. To address this, we propose Symplectic Positional Embeddings (SyPE), a learnable encoding framework derived from Hamiltonian mechanics. SyPE strictly generalizes RoPE by extending the rotation group $\mathrm{SO}(2)$ to the symplectic group $\mathrm{Sp}(2,\mathbb{R})$, modulated by a novel input-dependent adaptive warp module. By allowing the attention mechanism to adaptively dilate or contract temporal coordinates end-to-end, our approach captures locally varying periodicities without requiring pre-defined warping functions. We implement this mechanism in StretchTime, a multivariate forecasting architecture that achieves state-of-the-art performance on standard benchmarks, demonstrating superior robustness on datasets exhibiting non-stationary temporal dynamics.
💡 Research Summary
The paper tackles a fundamental limitation of Transformer‑based time‑series forecasting: standard positional encodings, especially Rotary Position Embedding (RoPE), assume a uniform, index‑based progression of time. Real‑world sequences often exhibit non‑linear “time‑warping” where the effective physical time τ(t) diverges from the sampling index. The authors formalize this misalignment and prove (Theorem 3.1) that RoPE cannot represent non‑affine warping because it enforces a constant angular velocity, making it impossible to match a varying τ(t).
To overcome this, they introduce Symplectic Positional Embeddings (SyPE), derived from Hamiltonian mechanics. For each frequency band a symmetric Hamiltonian matrix K is learned, generating a continuous flow S(t)=exp(t J K) in the symplectic group Sp(2,ℝ). RoPE appears as a special case when K is diagonal. An Adaptive Warp module computes input‑dependent time increments Δbτₜ = Softplus(wᵀτ hₜ) and accumulates them into warped coordinates bτₜ. Queries and keys are transformed by S(bτₜ) and J S(bτₜ), respectively, yielding attention scores that depend solely on the warped time difference (Theorem 3.2).
The resulting architecture, StretchTime, embeds these SyPE‑augmented attention layers into a multivariate forecasting pipeline. Input series are first residualized against the last observed value, tokenized by concatenating a global context vector, a channel‑specific projection of the raw value, a learnable absolute position, and a channel identifier. The tokens pass through the SyPE‑enabled Transformer, and the final forecast is obtained by adding back the residual reference.
Empirical evaluation on seven public benchmarks (ETT, Weather, Electricity, etc.) and on synthetically warped versions demonstrates state‑of‑the‑art performance, with average MSE reductions of roughly 8 % over strong baselines, especially when the degree of warping is high. Ablation studies confirm that both the adaptive warp module and the learnable Hamiltonian parameters are essential; removing either degrades performance to the level of standard RoPE.
In summary, the work redefines positional encoding as an input‑conditioned, dynamically learnable transformation, enabling end‑to‑end modeling of time‑warped dynamics without pre‑specified warping functions. Limitations include the 2‑dimensional nature of the symplectic flow (requiring stacking for higher‑dimensional periodicities) and the extra computational overhead of the warp module, suggesting avenues for future research.
Comments & Academic Discussion
Loading comments...
Leave a Comment