Gesturing Toward Abstraction: Multimodal Convention Formation in Collaborative Physical Tasks
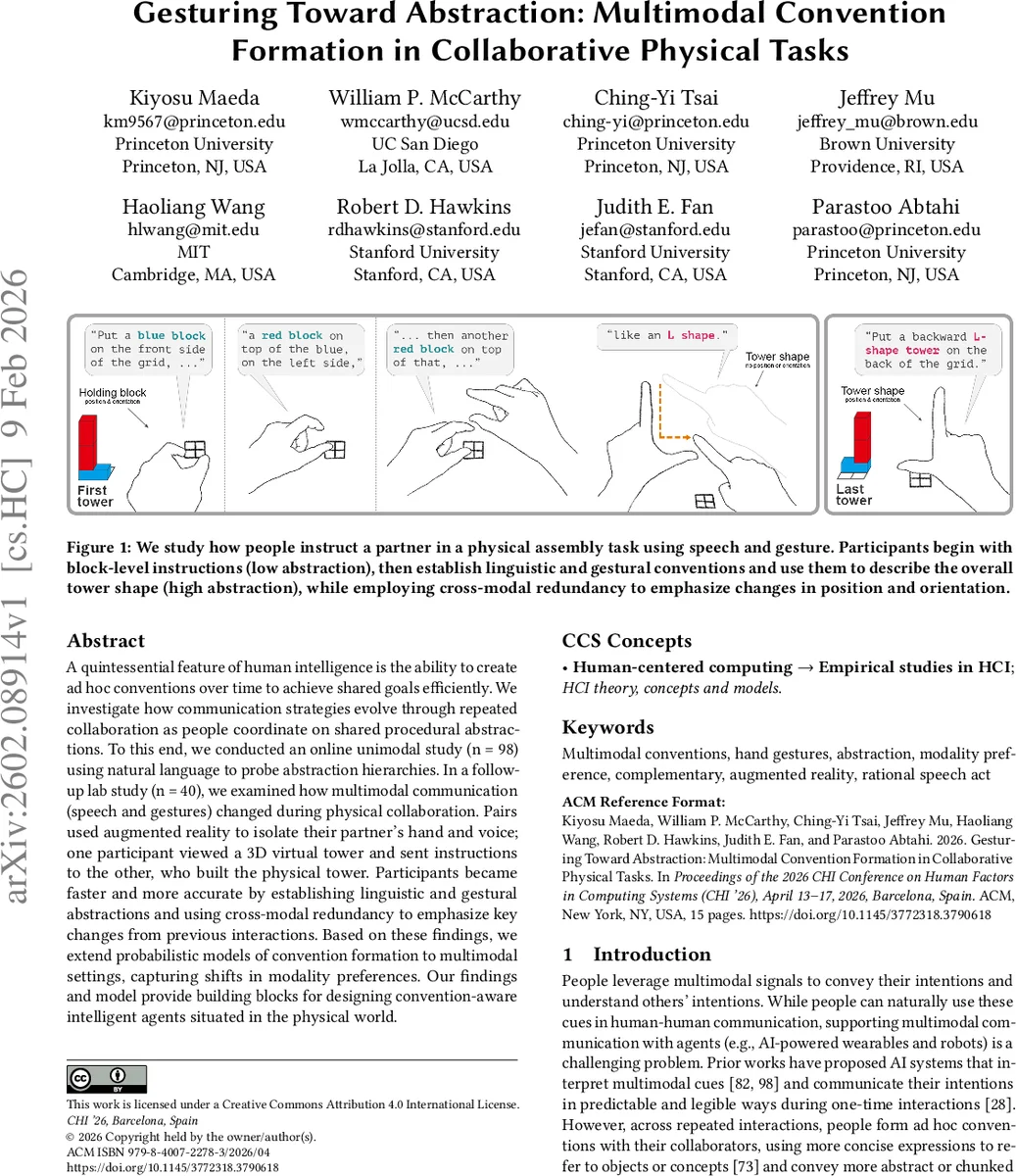
A quintessential feature of human intelligence is the ability to create ad hoc conventions over time to achieve shared goals efficiently. We investigate how communication strategies evolve through repeated collaboration as people coordinate on shared procedural abstractions. To this end, we conducted an online unimodal study (n = 98) using natural language to probe abstraction hierarchies. In a follow-up lab study (n = 40), we examined how multimodal communication (speech and gestures) changed during physical collaboration. Pairs used augmented reality to isolate their partner’s hand and voice; one participant viewed a 3D virtual tower and sent instructions to the other, who built the physical tower. Participants became faster and more accurate by establishing linguistic and gestural abstractions and using cross-modal redundancy to emphasize key changes from previous interactions. Based on these findings, we extend probabilistic models of convention formation to multimodal settings, capturing shifts in modality preferences. Our findings and model provide building blocks for designing convention-aware intelligent agents situated in the physical world.
💡 Research Summary
This paper investigates how people develop efficient multimodal conventions—using both speech and gesture—during repeated physical assembly tasks. The research proceeds in two phases. First, an online unimodal study with 98 participants examined linguistic abstraction. Participants reconstructed the same block towers over twelve repetitions, moving from detailed block‑level descriptions to concise tower‑level expressions such as “upside‑down U,” “long C,” and “long L.” Reconstruction accuracy (F1) improved from 0.88 to 0.98, and instruction length dropped by an average of 8.5 words, indicating rapid linguistic compression. The second phase involved a lab study with 40 dyads using augmented reality (AR). One partner viewed a virtual 3D tower and gave spoken instructions, while the other built the physical tower. AR headsets isolated the partner’s hand and voice, allowing clean separation of speech and gesture channels while still providing real‑time visual feedback of block placements. Over repetitions, dyads formed both linguistic and gestural abstractions and increasingly employed cross‑modal redundancy: they used speech and gesture together, especially to signal changes in tower position or orientation, thereby boosting reliability and reducing cognitive load. To model these dynamics, the authors extend the Rational Speech Act (RSA) framework to a multimodal lexicon that maps symbols to continuous-valued utterance‑gesture pairs. Simulations show that agents can acquire abstract tower representations and capture participant‑specific shifts in modality preference across interactions. The contributions are threefold: (1) a large‑scale online study quantifying language abstraction, (2) an AR‑mediated multimodal dataset of repeated physical collaboration, and (3) a probabilistic model of multimodal convention formation that can inform the design of convention‑aware AI agents. Limitations include the controlled indoor AR setting and the need for broader validation of gesture recognition and speech noise handling. Future work should test the model in diverse physical environments, with more complex tasks, and integrate it into real robots or wearable devices to assess generalizability.
Comments & Academic Discussion
Loading comments...
Leave a Comment