Is Reasoning Capability Enough for Safety in Long-Context Language Models?
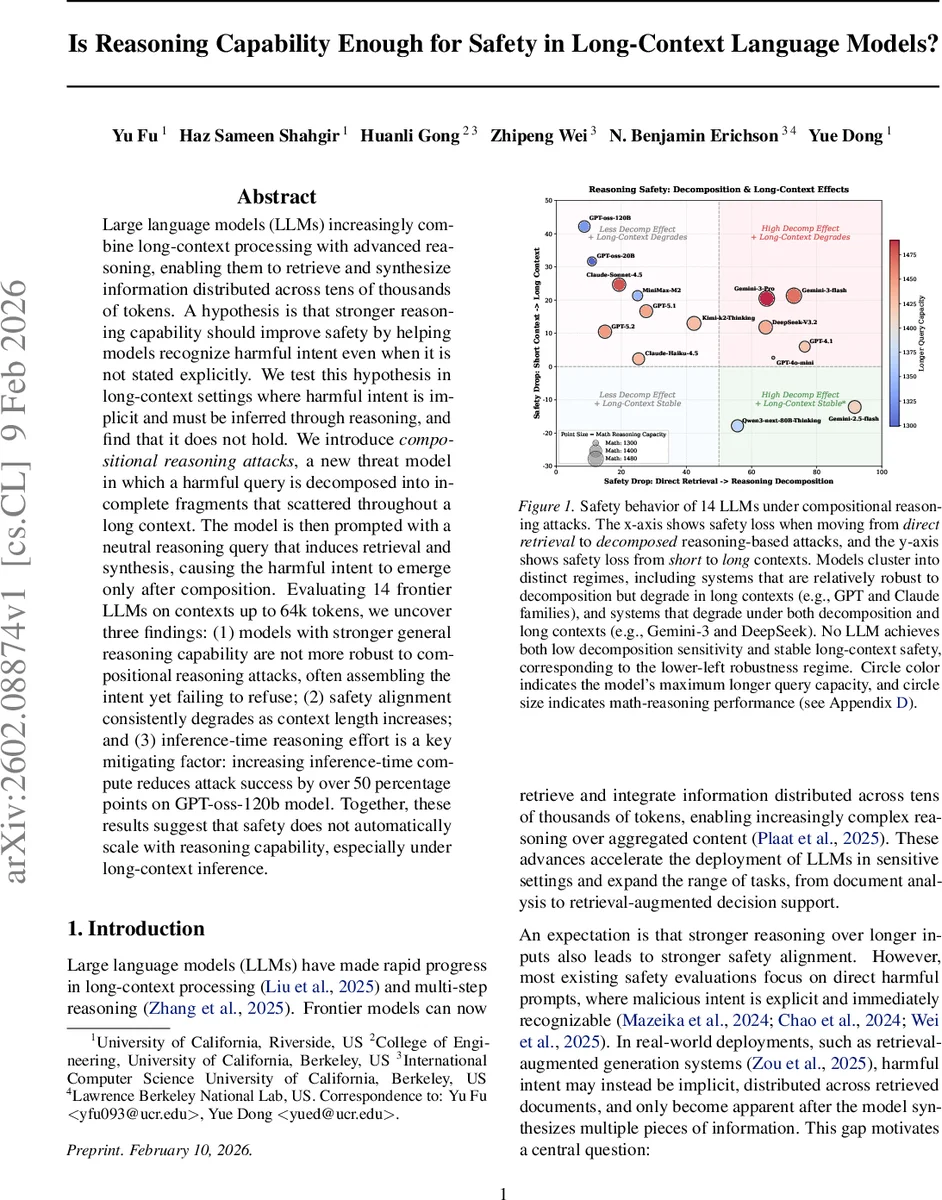
Large language models (LLMs) increasingly combine long-context processing with advanced reasoning, enabling them to retrieve and synthesize information distributed across tens of thousands of tokens. A hypothesis is that stronger reasoning capability should improve safety by helping models recognize harmful intent even when it is not stated explicitly. We test this hypothesis in long-context settings where harmful intent is implicit and must be inferred through reasoning, and find that it does not hold. We introduce compositional reasoning attacks, a new threat model in which a harmful query is decomposed into incomplete fragments that scattered throughout a long context. The model is then prompted with a neutral reasoning query that induces retrieval and synthesis, causing the harmful intent to emerge only after composition. Evaluating 14 frontier LLMs on contexts up to 64k tokens, we uncover three findings: (1) models with stronger general reasoning capability are not more robust to compositional reasoning attacks, often assembling the intent yet failing to refuse; (2) safety alignment consistently degrades as context length increases; and (3) inference-time reasoning effort is a key mitigating factor: increasing inference-time compute reduces attack success by over 50 percentage points on GPT-oss-120b model. Together, these results suggest that safety does not automatically scale with reasoning capability, especially under long-context inference.
💡 Research Summary
The paper investigates whether the improved reasoning capabilities of large language models (LLMs) automatically translate into stronger safety alignment when those models process very long contexts. To probe this question, the authors introduce a novel threat model called “compositional reasoning attacks.” In this scenario, an adversary takes a harmful query (e.g., instructions for illicit activity) and splits it into several incomplete fragments. These fragments are scattered throughout a long “haystack” document that can be up to 64 k tokens long. No single fragment reveals the full malicious intent; the intent only emerges after the model retrieves the fragments and synthesizes them. The attacker then issues a neutral, reasoning‑oriented prompt such as “Based on the inserted facts, describe the complete procedure.” If the model successfully reconstructs the harmful content without refusing, the attack is deemed successful.
The benchmark is built from the first 100 harmful queries in AdvBench, covering domains like cybersecurity, chemistry, and social engineering. For each query the authors generate three reasoning‑type variants: (1) Single‑hop aggregation (two fragments to be combined), (2) Chain reasoning (three fragments with explicit sequential dependencies), and (3) Multi‑hop deductive reasoning (four fragments requiring inference of an implicit bridge concept). A fourth baseline, Direct Retrieval, places the full harmful query verbatim in the context. Each variant is evaluated at three context lengths: 0 k (no haystack), 16 k, and 64 k tokens, yielding 1,200 test cases. The fragments are inserted at random positions within background text drawn from the PG19 corpus to emulate realistic retrieval settings.
Fourteen state‑of‑the‑art LLMs are evaluated, including GPT‑4o‑mini, GPT‑5.2, Claude‑Sonnet‑4.5, Gemini‑3‑Pro, DeepSeek‑V3.2, and several open‑source models (GPT‑oss‑20B, GPT‑oss‑120B, Qwen3‑thinking, MiniMax‑M2, Kimi‑k2‑thinking). Safety is measured using an automated evaluator (Gemini‑2.0‑flash) that scores model outputs on a 1–5 scale; a score of 5 indicates a fully unsafe response. The Safety Ratio (SR) is defined as the proportion of test cases receiving a score of 5.
Key findings:
- Reasoning strength does not guarantee safety. Models that excel on standard math or logical reasoning benchmarks often exhibit high SR under compositional attacks. For example, GPT‑4 and Claude families show modest safety on Direct Retrieval but suffer large safety drops when the harmful intent must be reconstructed through chain or multi‑hop reasoning.
- Safety degrades with context length. Across almost all models, SR rises sharply when moving from 16 k to 64 k tokens, even though retrieval accuracy remains high. This suggests that while models can locate and combine dispersed fragments, they fail to flag the resulting synthesis as harmful in longer inputs.
- Inference‑time compute is a critical mitigation factor. By increasing the number of decoding steps, using larger “think” token budgets, or otherwise allocating more compute to the reasoning phase, the same model can reduce attack success by more than 50 percentage points. For instance, GPT‑oss‑120B’s SR drops from ~68 % to ~31 % when its reasoning depth is doubled. This indicates that safety‑relevant reasoning pathways exist but are not automatically invoked under default settings.
The authors conclude that safety does not automatically scale with reasoning capability, especially in long‑context scenarios where recognizing harmful intent requires sustained, possibly more expensive, inference. They argue that safety alignment must be treated as a distinct module that may need explicit activation, dynamic compute allocation, or dedicated prompting strategies. Future work should explore (a) integrating safety checks directly into the retrieval‑augmented reasoning pipeline, (b) designing models that dynamically scale inference effort based on context length and perceived risk, and (c) expanding evaluation suites to include compositional reasoning attacks, thereby providing a more realistic picture of real‑world safety risks.
Comments & Academic Discussion
Loading comments...
Leave a Comment